9.10.1 Project Roadmap: Build a Traceable Agent
An Agent project portfolio should show a traceable execution loop, not just one final model answer.
See the Project Loop First
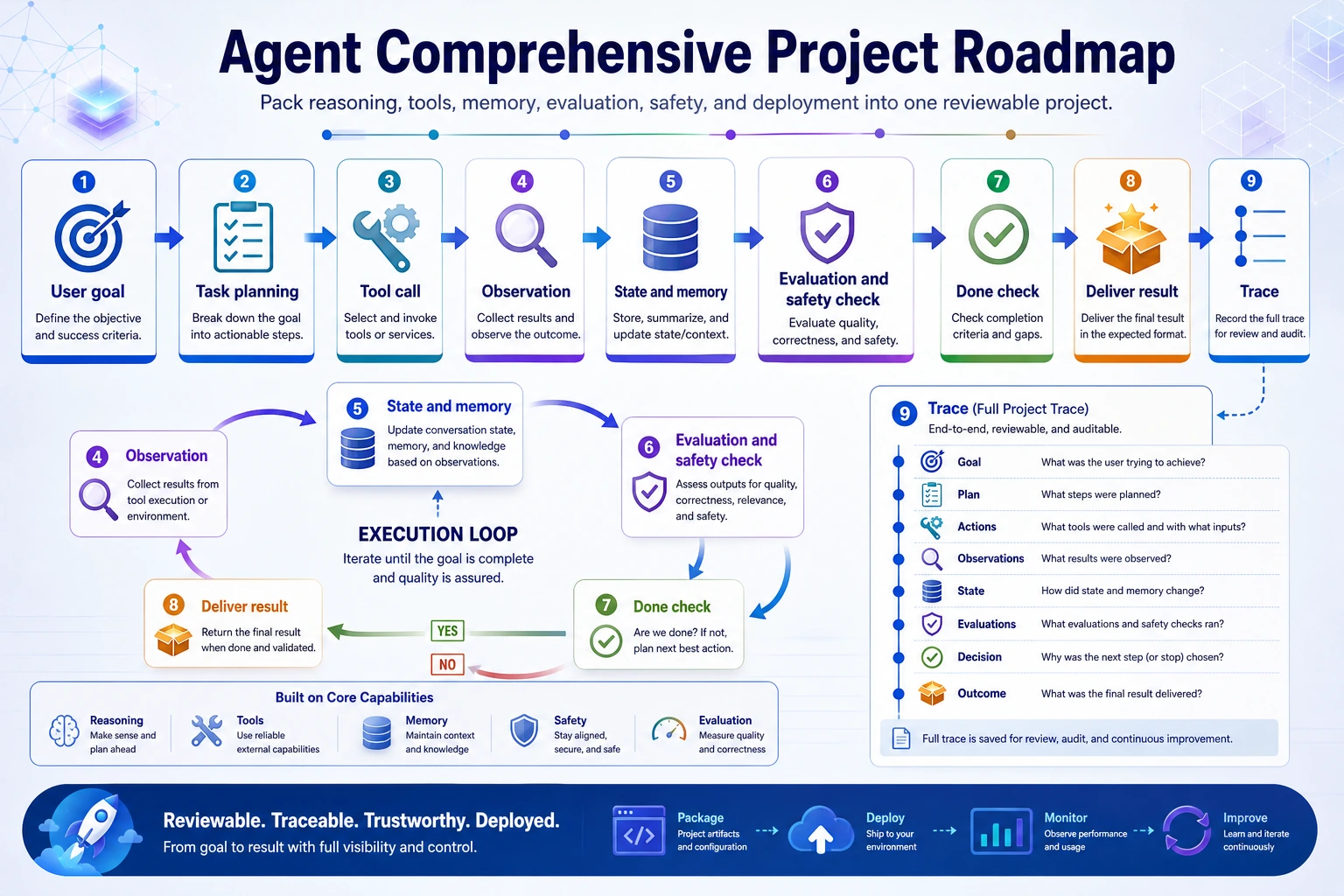
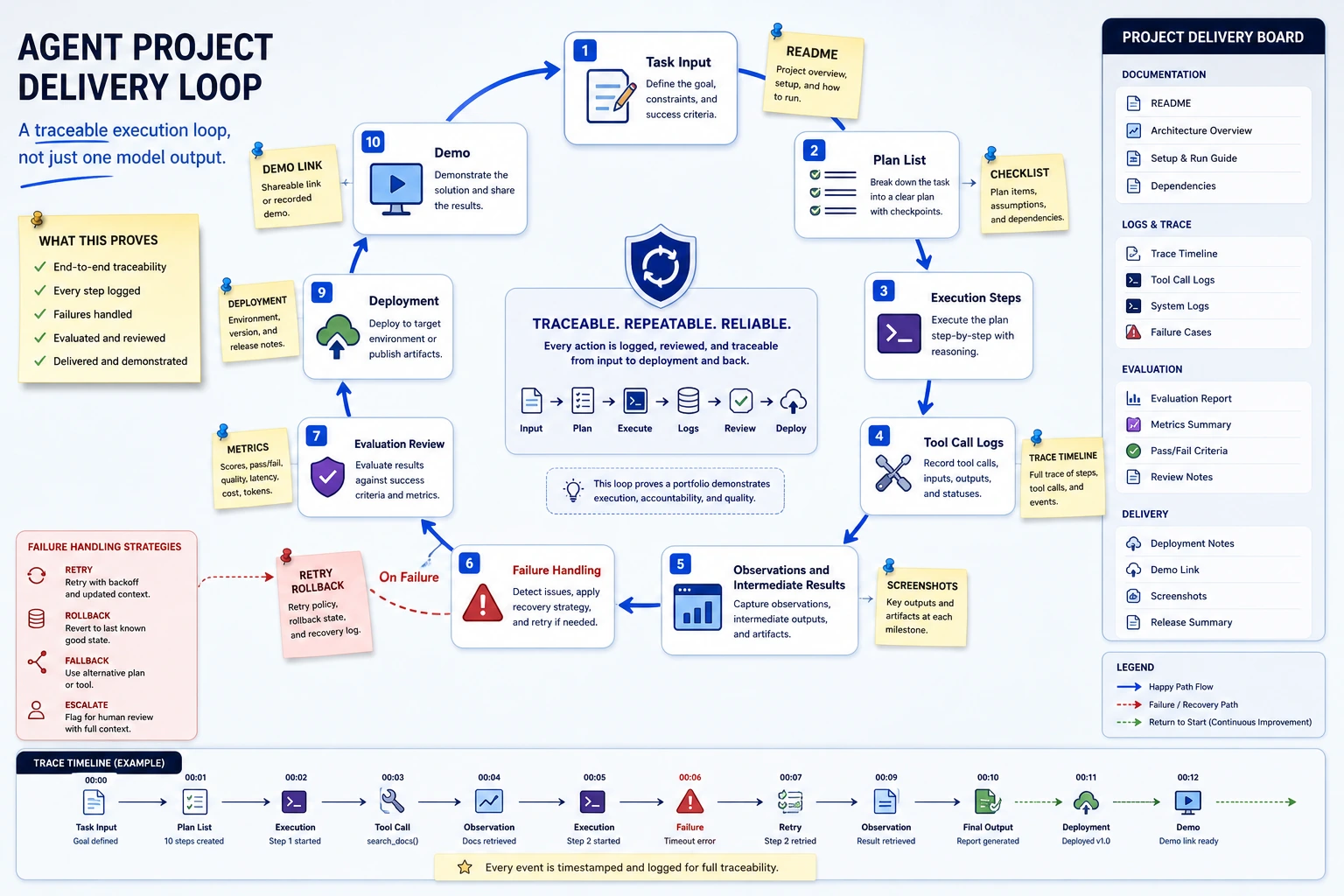
The loop is: goal, plan, tool call, observation, state update, failure handling, stop decision, final output, evaluation.
Run an Agent Evidence Check
Use this before calling the project portfolio-ready.
project = {
"goal_defined": True,
"trace_saved": True,
"tool_logs": True,
"failure_case": True,
"eval_tasks": 10,
}
ready = (
project["goal_defined"]
and project["trace_saved"]
and project["tool_logs"]
and project["failure_case"]
and project["eval_tasks"] >= 5
)
print("portfolio_ready:", ready)
print("evidence:", "goal, trace, tools, failure, eval")
Expected output:
portfolio_ready: True
evidence: goal, trace, tools, failure, eval
If this says False, improve the evidence before adding more Agent roles.
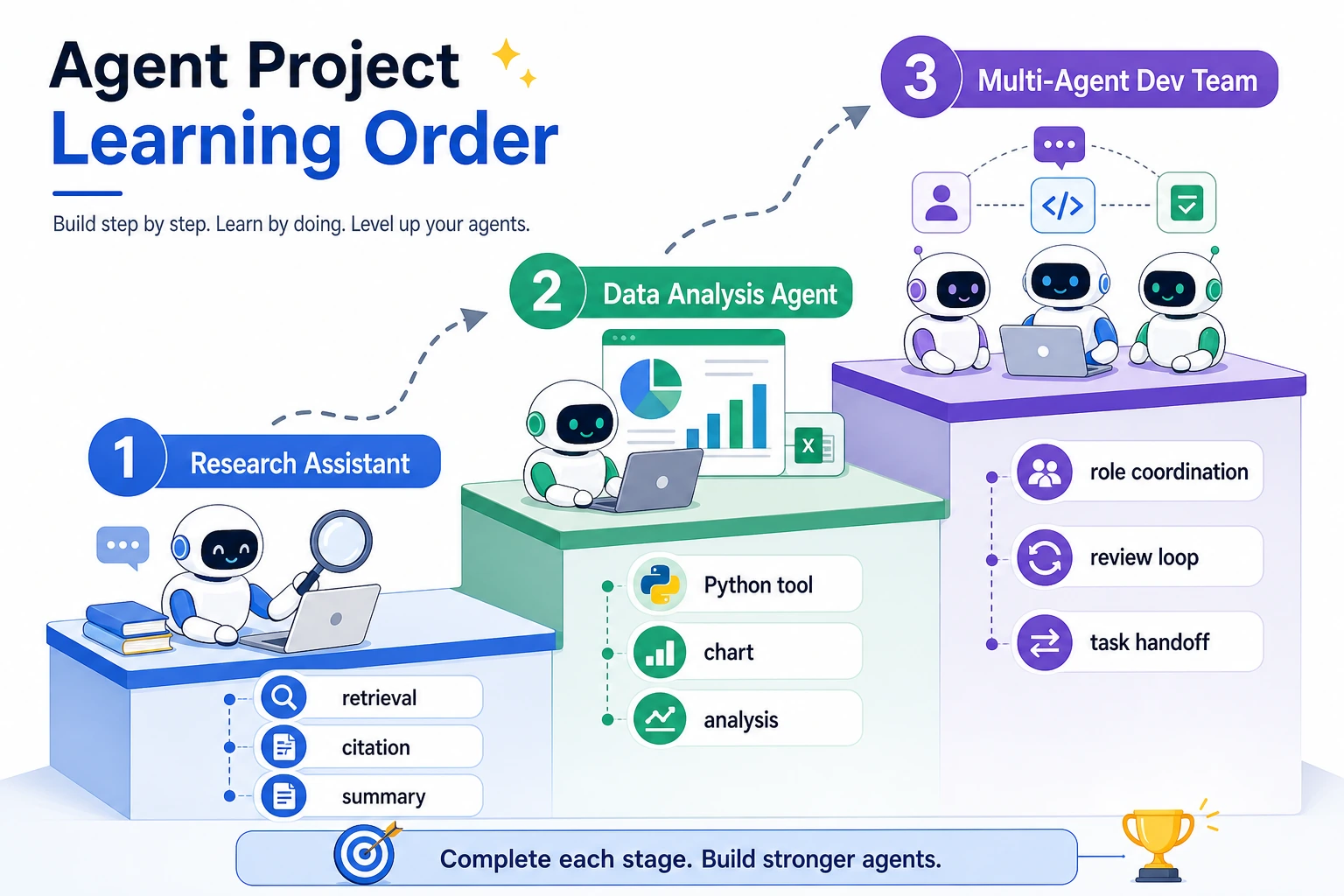
Learn in This Order
| Step | Project | What It Trains |
|---|---|---|
| 1 | Research assistant | Retrieval, citation, summarization, trustworthy output |
| 2 | Data analysis Agent | Python tool calls, table analysis, charts, interpretation |
| 3 | Multi-Agent development team | Role division, handoff, review loop, merge ownership |
| 4 | Hands-on workshop | The smallest traceable single-Agent baseline |
Run 9.10.5 Hands-on: Build a Traceable Single-Agent Assistant before expanding the project.
Project Deliverable Standards
| Deliverable | Minimum Requirement | Stronger Portfolio Version |
|---|---|---|
| README | Goal, run command, dependencies, examples | Add architecture, trade-offs, cost, safety, retrospective |
| Architecture | Model, tools, memory, state, evaluation, safety | Add deployment boundary and human handoff |
| Tool list | Callable tools, input/output schema, failures | Add permission rules and sandbox notes |
| Execution trace | Plan, action, observation, replan, stop | Add replayable JSONL logs |
| Failure case | At least 1 real failure | Add 3 cases with cause, fix, regression check |
| Evaluation set | Fixed tasks and pass/fail rules | Add baseline, metrics, and comparison experiments |
| Deployment note | How to run locally | Add API entry, environment variables, monitoring, rollback |
Pass Check
You pass this chapter when another developer can replay your Agent run, inspect each tool call and observation, understand why it stopped, and see at least one failure analysis.
The basic version can be a single-Agent project. Add memory, MCP, multi-Agent collaboration, or deployment only after the trace and evaluation loop are solid.