9.9.3 Runtime Management
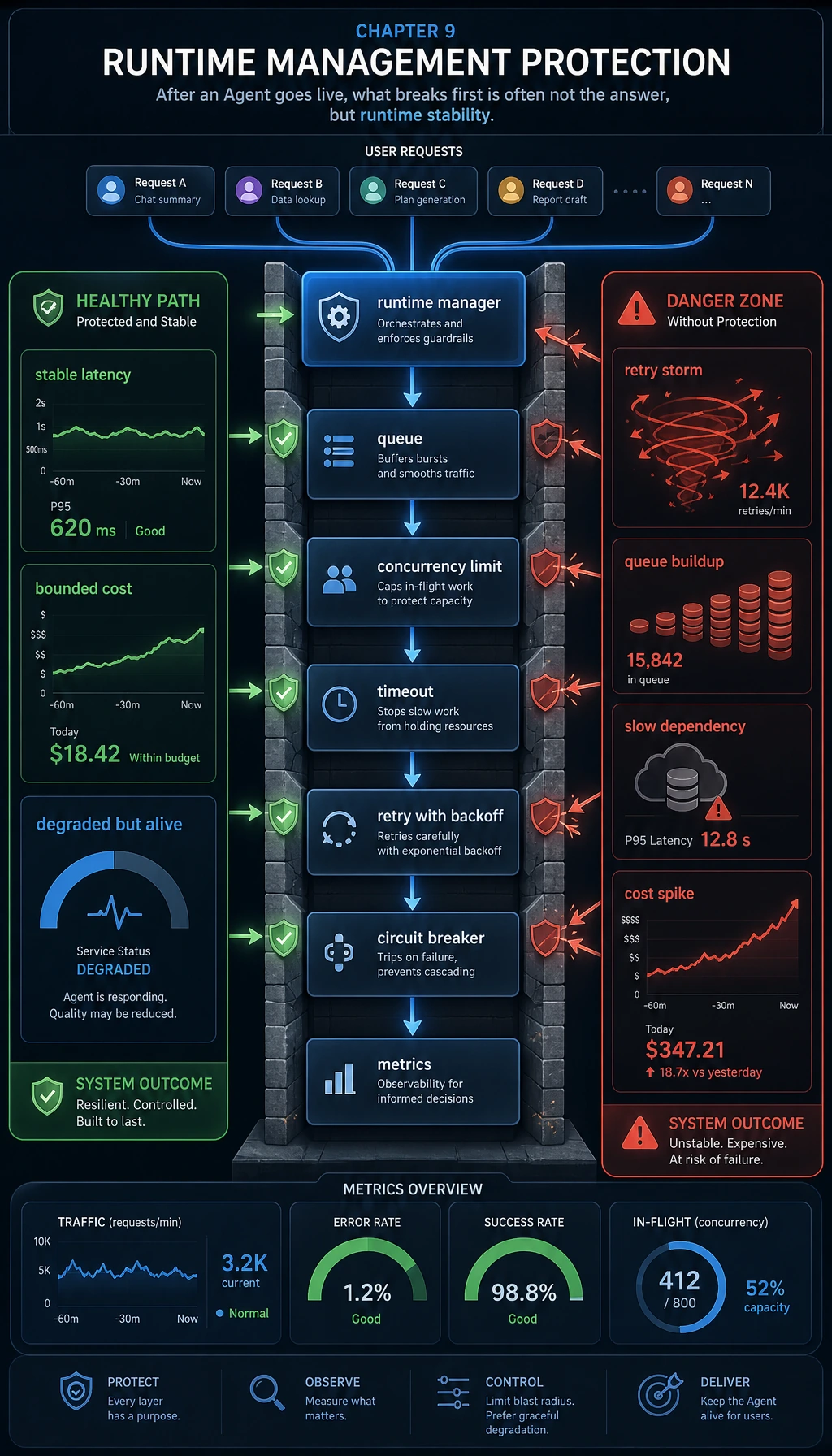
For a local demo, “it runs once” is usually good enough. Production systems have very different requirements:
- It still runs under peak traffic
- It stays stable when dependencies are flaky
- It keeps latency and cost under control
That is what runtime management is here to solve.
Learning Objectives
- Understand what concurrency, timeouts, retries, and circuit breakers are protecting against
- Learn how to build a minimal runtime manager
- Understand why runtime metrics are just as important as model metrics
- Build an engineering mindset that prioritizes system stability over one-off success
Why are Agents especially prone to runtime problems?
One request is often not one call
A typical Agent workflow includes:
- Model inference
- Tool calling
- Retrieval
- Another round of inference
This means a single user request may contain several sub-calls. The longer the chain, the more runtime fluctuations are amplified.
What shows up first after deployment is often not “wrong answers,” but “unstable execution”
Typical symptoms:
- More timeouts under high concurrency
- Retry storms after temporary upstream failures
- Requests queuing too long
- A few slow requests dragging down overall throughput
So runtime management is essentially about protecting system availability.
The four most important runtime mechanisms
Concurrency control
Limit the number of tasks running at the same time so resources are not exhausted all at once.
Timeouts
Set a boundary for each step to prevent requests from hanging forever.
Retries
Retry only a limited number of times for temporary errors, instead of starting over for every error.
Circuit breaking
When a dependency keeps failing, stop calling it for a while to avoid amplifying the failure.
First, run a minimal runtime manager
import asyncio
class AgentRuntime:
def __init__(self, max_concurrency=2, timeout_sec=0.8, max_retries=1, breaker_threshold=2):
self.semaphore = asyncio.Semaphore(max_concurrency)
self.timeout_sec = timeout_sec
self.max_retries = max_retries
self.breaker_threshold = breaker_threshold
self.breaker_open = False
self.failure_streak = 0
self.metrics = {
"total": 0,
"success": 0,
"timeout": 0,
"error": 0,
"retry": 0,
"rejected_by_breaker": 0,
"latency_ms_total": 0.0,
}
async def _upstream_call(self, task):
await asyncio.sleep(task["latency"])
if task.get("should_fail"):
raise RuntimeError("upstream_error")
return {"task_id": task["id"], "result": f"ok:{task['payload']}"}
async def handle(self, task):
self.metrics["total"] += 1
if self.breaker_open:
self.metrics["rejected_by_breaker"] += 1
return {"ok": False, "error": "circuit_open"}
last_error = None
for attempt in range(self.max_retries + 1):
if attempt > 0:
self.metrics["retry"] += 1
try:
async with self.semaphore:
result = await asyncio.wait_for(
self._upstream_call(task),
timeout=self.timeout_sec,
)
latency_ms = task["latency"] * 1000
self.metrics["success"] += 1
self.metrics["latency_ms_total"] += latency_ms
self.failure_streak = 0
return {"ok": True, "result": result, "attempts": attempt + 1}
except asyncio.TimeoutError:
last_error = "timeout"
if attempt == self.max_retries:
self.metrics["timeout"] += 1
self.failure_streak += 1
break
except Exception as e:
last_error = str(e)
if attempt == self.max_retries:
self.metrics["error"] += 1
self.failure_streak += 1
break
if self.failure_streak >= self.breaker_threshold:
self.breaker_open = True
return {"ok": False, "error": last_error}
def summary(self):
avg_latency = (
self.metrics["latency_ms_total"] / self.metrics["success"]
if self.metrics["success"] else 0.0
)
return {**self.metrics, "avg_latency_ms": round(avg_latency, 2)}
async def main():
runtime = AgentRuntime(max_concurrency=2, timeout_sec=0.7, max_retries=1, breaker_threshold=2)
tasks = [
{"id": "r1", "payload": "refund", "latency": 0.2},
{"id": "r2", "payload": "slow", "latency": 1.0},
{"id": "r3", "payload": "fail", "latency": 0.1, "should_fail": True},
{"id": "r4", "payload": "normal", "latency": 0.3},
{"id": "r5", "payload": "after_breaker", "latency": 0.1},
]
results = []
for task in tasks:
results.append(await runtime.handle(task))
print("results:")
for item in results:
print(item)
print("\nmetrics:")
print(runtime.summary())
print("breaker_open:", runtime.breaker_open)
asyncio.run(main())
Expected output:
results:
{'ok': True, 'result': {'task_id': 'r1', 'result': 'ok:refund'}, 'attempts': 1}
{'ok': False, 'error': 'timeout'}
{'ok': False, 'error': 'upstream_error'}
{'ok': False, 'error': 'circuit_open'}
{'ok': False, 'error': 'circuit_open'}
metrics:
{'total': 5, 'success': 1, 'timeout': 1, 'error': 1, 'retry': 2, 'rejected_by_breaker': 2, 'latency_ms_total': 200.0, 'avg_latency_ms': 200.0}
breaker_open: True
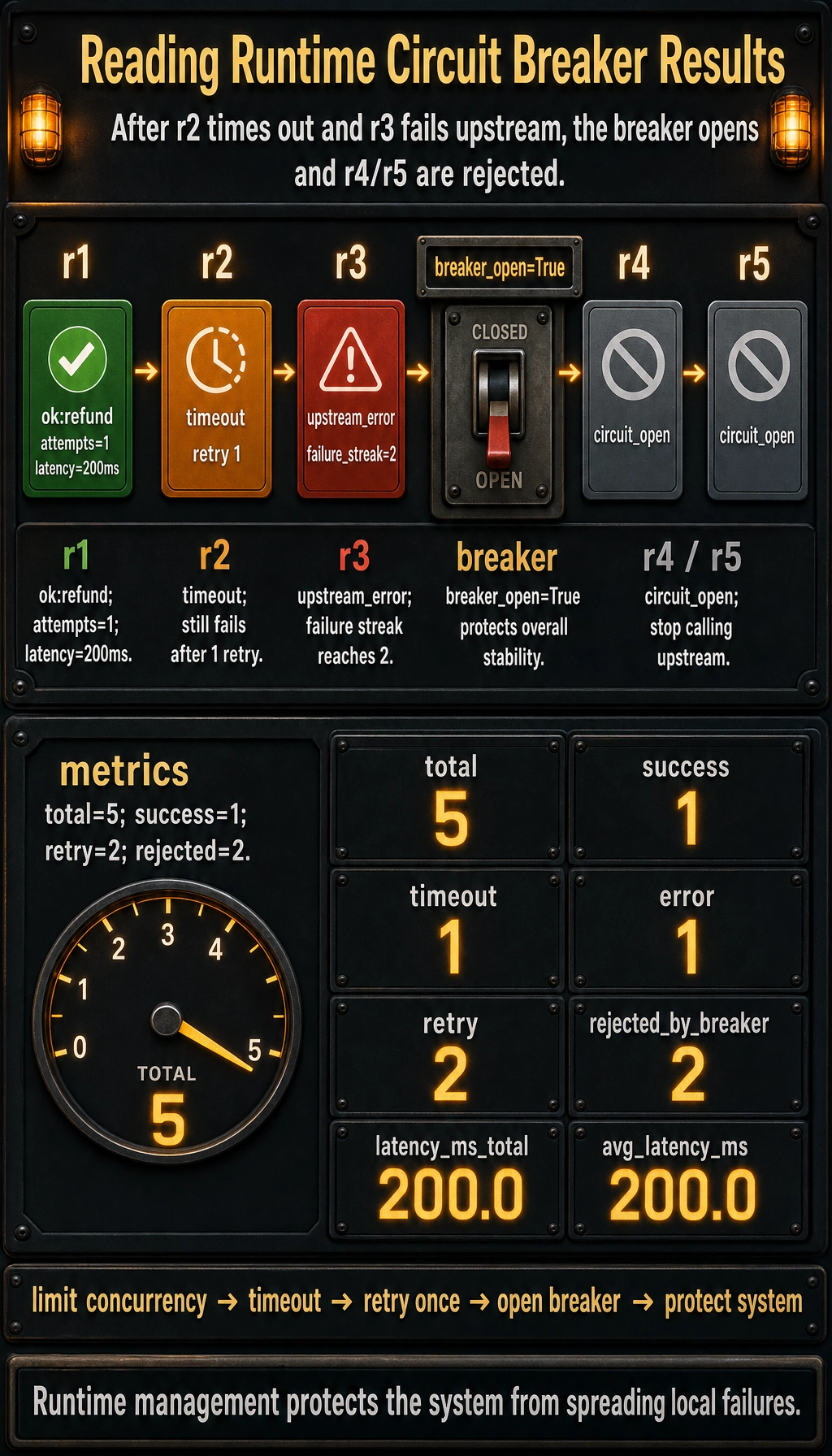
Read the timeline from r1 to r5: the first request succeeds, the next two failures consume the single retry budget and open the breaker, and the last two requests are rejected intentionally to protect the system.
Which parts of this code should you pay the most attention to?
Semaphore: concurrency limitingwait_for: timeoutattempt > 0: retry countingbreaker_open: circuit breaking
Why is this already very close to real runtime problems?
Because it covers three real production scenarios:
- Normal success
- Slow requests timing out
- Continuous failures triggering protection
How should runtime metrics be interpreted?
Start with these:
success / total: success ratetimeout / total: timeout rateretry / total: retry ratiorejected_by_breaker: number of requests rejected by the circuit breakeravg_latency_ms: average successful latency
If the timeout rate is high, check first:
- Is the upstream service slow?
- Is the timeout threshold too small?
- Is concurrency too high, causing queueing?
If the retry ratio is high, check first:
- Are you retrying errors that cannot be recovered?
- Is the upstream service unstable?
The most common runtime optimization directions
Rate limiting and backpressure
When the system is close to saturation, you should actively:
- Reject low-priority requests
- Or cap the queue length
Fallback and degradation
For example:
- Disable expensive tool chains
- Switch to cached results
- Return a lighter-weight safe response
Use different policies for different dependencies
Different tools should not share exactly the same:
- Timeout
- Retry
- Circuit-breaker thresholds
Because their stability and cost are different.
Most common misconceptions
Misconception 1: Higher concurrency is always better
Too much concurrency can directly overwhelm both your system and the upstream service.
Misconception 2: Retries always improve success rate
If error classification is wrong, retries will only amplify the failure.
Misconception 3: Only look at average latency
High-percentile latency and timeout rate often reflect the real user experience much better.
Summary
The most important thing in this section is to build a deployment mindset:
The core of Agent runtime management is not to keep trying until every request succeeds, but to protect overall system stability with concurrency control, timeouts, retries, and circuit breaking.
Once this layer is in place, the system truly has a foundation for production deployment.
Exercises
- Change the example
max_concurrencyto1and3, and compare the results. - Increase
timeout_secand observe how the timeout rate changes. - Why can’t “number of retries” be designed independently of “error type”?
- Think about it: if a certain tool is especially expensive, what protection would you add at the runtime layer?