9.10.4 Project: Multi-Agent Development Team [Optional]
Multi-Agent development team projects can easily turn into a performance:
- Many roles
- Many conversations
- But unstable results
So what really matters is not the number of roles, but:
Can the task be split reliably, is the handoff clear, and can the system roll back after failure?
This lesson will walk through a “portfolio-level minimal closed loop.”
Learning objectives
- Learn how to define a minimal role set for a multi-Agent development team
- Understand the most important handoff artifacts between roles
- Build a multi-Agent project skeleton that can be demonstrated and verified
- Understand why protocols and state matter more than “more rounds of talking”
Why is a minimal role set usually enough?
A very stable minimal closed loop usually only needs:
- planner
- coder
- reviewer
- tester
These four roles are already enough to demonstrate:
- Task decomposition
- Implementation
- Review
- Verification
If you add too many roles at the start, the system can easily look busy while actually spinning in place.
First, run a role artifact handoff example
This example does not actually modify code, but it will show the structure of the most important “handoff artifacts.”
from dataclasses import dataclass
@dataclass
class TaskPlan:
goal: str
files_to_change: list
acceptance_test: str
@dataclass
class Patch:
summary: str
changed_files: list
@dataclass
class ReviewNote:
approved: bool
issues: list
@dataclass
class TestReport:
passed: bool
cases: list
plan = TaskPlan(
goal="Fix the incorrect amount display on the refund page",
files_to_change=["refund.py", "test_refund.py"],
acceptance_test="Given 100 yuan and 20% off, the result should be 80 yuan",
)
patch = Patch(
summary="Fix the discount calculation logic and add tests",
changed_files=["refund.py", "test_refund.py"],
)
review = ReviewNote(
approved=False,
issues=["Unclear variable naming", "Incomplete edge case tests"],
)
test_report = TestReport(
passed=False,
cases=["test_discount_basic", "test_discount_zero"],
)
print(plan)
print(patch)
print(review)
print(test_report)
Expected output:
TaskPlan(goal='Fix the incorrect amount display on the refund page', files_to_change=['refund.py', 'test_refund.py'], acceptance_test='Given 100 yuan and 20% off, the result should be 80 yuan')
Patch(summary='Fix the discount calculation logic and add tests', changed_files=['refund.py', 'test_refund.py'])
ReviewNote(approved=False, issues=['Unclear variable naming', 'Incomplete edge case tests'])
TestReport(passed=False, cases=['test_discount_basic', 'test_discount_zero'])

What is the most important part of this example?
It shows that what a multi-Agent project should really demonstrate is not plain chat logs, but:
- Handoff artifacts
- Task status
- Result verification
Why are artifacts more important than conversation?
Because artifacts are the inputs that later roles actually depend on. If you only look at conversation, it is hard to tell whether the system can collaborate reliably.
A minimal workflow loop
Continue in the same file or Python session, because this block reuses the dataclasses from the previous example.
Now connect the four roles into a minimal flow:
def planner(goal):
return TaskPlan(
goal=goal,
files_to_change=["refund.py", "test_refund.py"],
acceptance_test="Given 100 yuan and 20% off, the result should be 80 yuan",
)
def coder(plan):
return Patch(
summary=f"Implement according to the task goal: {plan.goal}",
changed_files=plan.files_to_change,
)
def reviewer(patch):
if "test_refund.py" not in patch.changed_files:
return ReviewNote(approved=False, issues=["Missing test file changes"])
return ReviewNote(approved=True, issues=[])
def tester(review_note):
if not review_note.approved:
return TestReport(passed=False, cases=["review_failed"])
return TestReport(passed=True, cases=["test_discount_basic", "test_discount_zero"])
goal = "Fix the incorrect amount display on the refund page"
plan = planner(goal)
patch = coder(plan)
review = reviewer(patch)
test_report = tester(review)
print(plan)
print(patch)
print(review)
print(test_report)
Expected output:
TaskPlan(goal='Fix the incorrect amount display on the refund page', files_to_change=['refund.py', 'test_refund.py'], acceptance_test='Given 100 yuan and 20% off, the result should be 80 yuan')
Patch(summary='Implement according to the task goal: Fix the incorrect amount display on the refund page', changed_files=['refund.py', 'test_refund.py'])
ReviewNote(approved=True, issues=[])
TestReport(passed=True, cases=['test_discount_basic', 'test_discount_zero'])

Read the output as an artifact chain: TaskPlan defines the goal and acceptance rule, Patch changes both the implementation and test file, ReviewNote is the gate, and TestReport is the final evidence.
Why does this loop already feel like a real project?
Because it captures the three most important things in a multi-Agent project:
- Role division of labor
- Clear artifact handoffs
- A review-and-test feedback loop
If reviewer does not approve, why should tester not continue?
This shows that a multi-Agent system is not “everyone works in parallel on their own,” but must respect:
- Stage dependencies
- Handoff quality
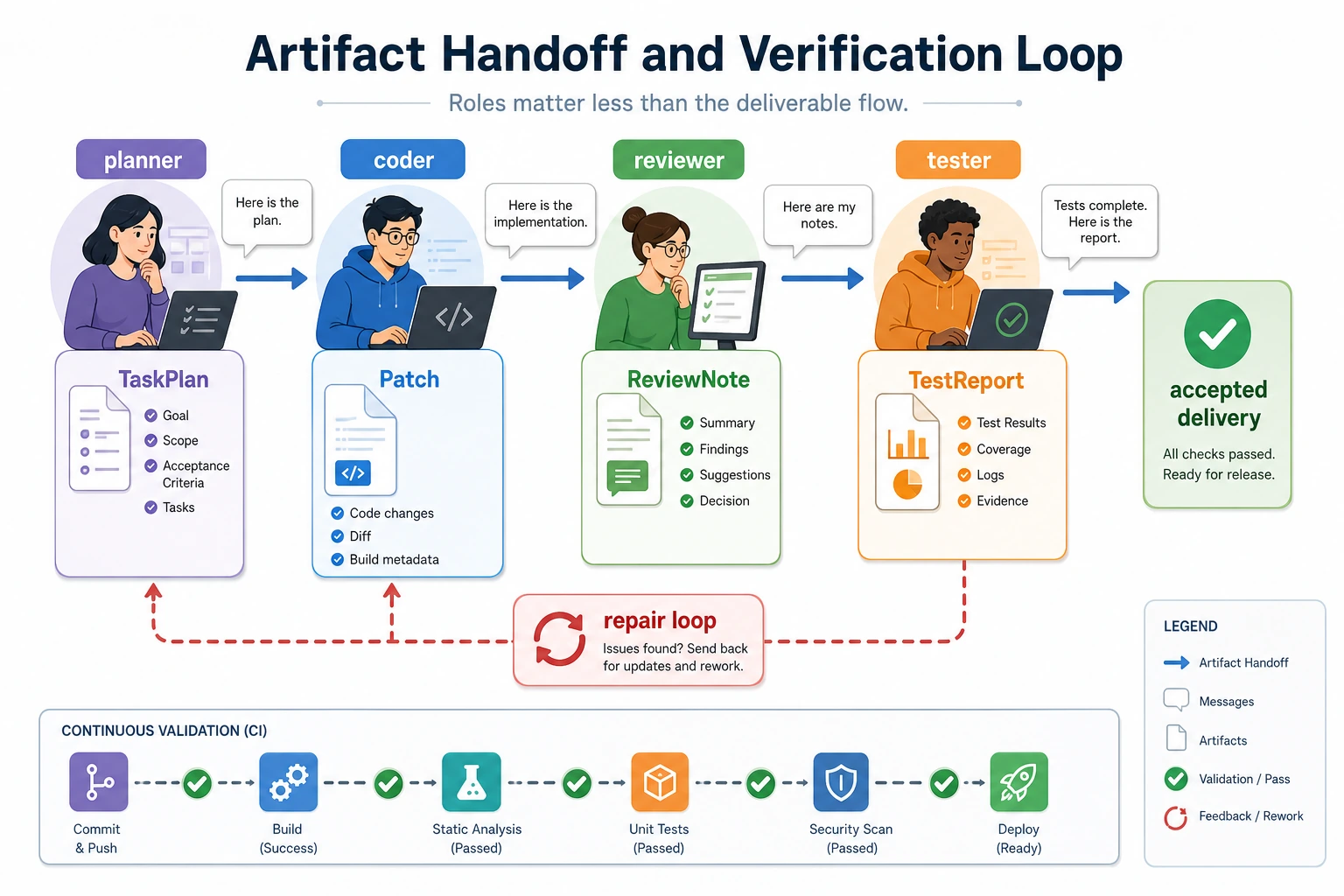
This diagram emphasizes that “the number of roles is not the point; artifact handoff is the point”: planner produces the plan, coder produces the patch, reviewer produces issues, tester produces the test report, and after failure the system returns to the corresponding role for fixes.
What should a portfolio-level project show?
A complete task trace
For example:
- Task goal
- plan
- patch
- review issues
- test report
One failure rollback
This is very convincing. For example:
- reviewer rejects the patch
- coder fixes it a second time
- tester verifies again
Clear role boundaries
Your portfolio should be able to answer:
- Why do we need these 4 roles?
- What are the input and output of each role?
The most common pitfalls
Many roles, but unclear boundaries
This makes the system look complex, but in reality it is just duplicate work.
No shared state or unified artifact format
This makes it hard for roles to hand off work reliably.
Only showing the success path
A good multi-Agent project should also show:
- How rollback happens after failure
- Which step is most likely to go wrong
Summary
The most important thing in this lesson is to establish a portfolio-level judgment:
The real value of a multi-Agent development team project is not having more and more roles, but whether task decomposition, artifact handoff, and failure rollback can be organized into a stable closed loop.
Once this loop is in place, the project becomes a very good way to demonstrate your true understanding of multi-Agent systems.
Suggested version roadmap
| Version | Goal | Delivery focus |
|---|---|---|
| Basic | Get the minimal closed loop working | Can input, process, and output, while keeping a set of examples |
| Standard | Become a presentable project | Add configuration, logging, error handling, README, and screenshots |
| Challenge | Approach portfolio quality | Add evaluation, comparison experiments, failure sample analysis, and a next-step roadmap |
It is recommended to finish the basic version first; do not pursue something huge and complete from the start. With every version upgrade, write into the README: “What new capability was added, how was it verified, and what problems remain.”
Exercises
- Add an
ops_agentto the workflow and think about where it should be inserted. - Think about why “a unified artifact format” is more important than “roles that can chat” in a multi-Agent project.
- If reviewer frequently rejects patches, which layer should you optimize first?
- If you turn this project into a demo page, which complete trace would you most want to show?