9.10.2 Project: Intelligent Research Assistant
The research assistant project is a great fit for an Agent portfolio, not because it looks advanced, but because it naturally requires the system to do all of the following well at the same time:
- Retrieval
- Reading
- Summarization
- Citation tracking
If any one of these links breaks, the result becomes “untrustworthy.” That makes it an excellent project for practicing the core theme of “trustworthy Agents.”
Learning Objectives
- Learn how to define a clear scope for a research assistant project
- Learn how to connect “retrieval -> reading -> summarization -> citation” into a closed loop
- Learn how to define the most important evaluation criteria for this project
- Learn how to package it as a convincing portfolio project
First, narrow the project scope
A research assistant project that is good for practice should start as:
- Given a topic
- Retrieve several documents
- Output a structured summary
- Attach a source to each summary item
Rather than immediately trying to build:
- Automatic paper writing
- Automatic literature reviews
Why?
Because for a research assistant, “trustworthy” matters more than “flashy.”
What does the minimal closed loop of a portfolio-grade research assistant look like?
- Input a topic or question
- Retrieve candidate materials
- Select the most relevant materials
- Generate a structured summary
- Provide a source for each summary item
- Perform error analysis and build a regression set
As long as these 6 steps are clear, the project already has strong portfolio value.
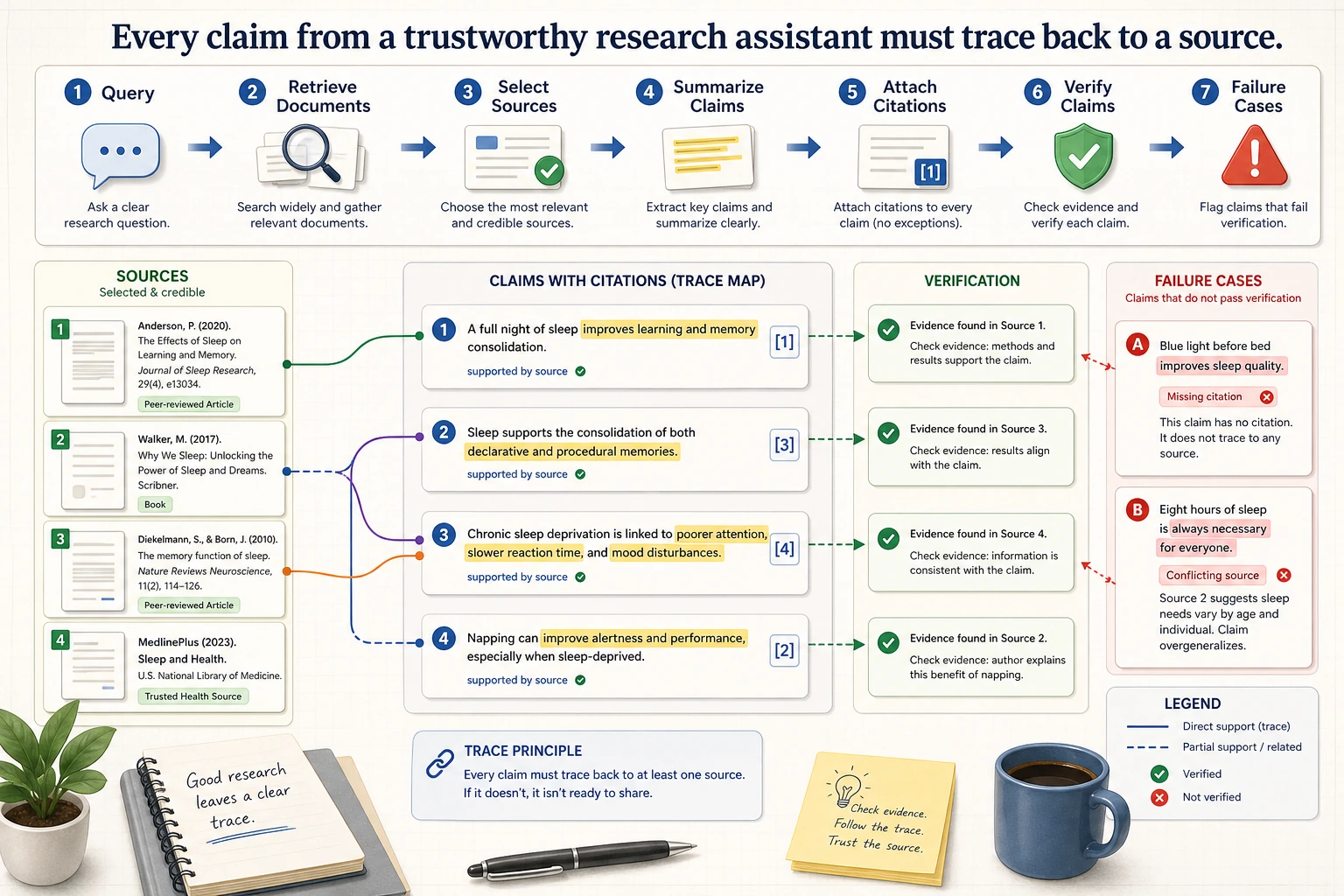
The most important thing in a research assistant is not “the summary reads smoothly,” but whether each claim can be traced back to a source. When reading the diagram, check each conclusion along the chain of retrieve, select, summarize, cite, and verify to see whether it has evidence.
Recommended progression order
For beginners, a more stable sequence is usually:
- Narrow the topic scope first
- Build the simplest retrieval baseline
- Add structured summarization
- Finally add citation validation and failure case demonstrations
This makes it easier to turn a “trustworthy research assistant” into a clear closed loop.
Let’s first look at a minimal research assistant example
This example does three things:
- Simulate retrieval with keyword matching
- Generate a structured summary
- Attach a source to each summary item
docs = [
{
"id": "d1",
"title": "RAG improves factual grounding",
"text": "RAG can improve factual grounding by retrieving external evidence.",
"keywords": {"rag", "retrieval", "grounding", "evidence"},
},
{
"id": "d2",
"title": "Long context still struggles with precision",
"text": "Long context models may still miss key details without retrieval or re-ranking.",
"keywords": {"long", "context", "retrieval", "ranking"},
},
{
"id": "d3",
"title": "Citations increase user trust",
"text": "Users trust generated summaries more when each claim is tied to an explicit source.",
"keywords": {"citation", "trust", "summary", "source"},
},
]
def retrieve(query, top_k=2):
query_terms = set(query.lower().split())
scored = []
for doc in docs:
score = len(query_terms & doc["keywords"])
scored.append((score, doc))
scored.sort(key=lambda x: x[0], reverse=True)
return [doc for score, doc in scored[:top_k] if score > 0]
def summarize_with_citations(query):
hits = retrieve(query, top_k=2)
bullets = []
for doc in hits:
bullets.append(
{
"claim": doc["text"],
"source_id": doc["id"],
"source_title": doc["title"],
}
)
return bullets
query = "rag retrieval citation trust"
result = summarize_with_citations(query)
for item in result:
print(item)
Expected output:
{'claim': 'RAG can improve factual grounding by retrieving external evidence.', 'source_id': 'd1', 'source_title': 'RAG improves factual grounding'}
{'claim': 'Users trust generated summaries more when each claim is tied to an explicit source.', 'source_id': 'd3', 'source_title': 'Citations increase user trust'}
Why is this example more valuable than a “project skeleton dataclass”?
Because it already reflects the most important product characteristic of a research assistant:
- The result is not a black-box summary
- Every conclusion can be traced back to a source
Why is citation the make-or-break issue for this kind of project?
Because without sources, users have a hard time telling whether:
- The system really read it from the documents
- Or the model just made it up
How should this project be evaluated?
Retrieval quality
For example:
- Are the retrieved documents actually relevant?
Summary quality
For example:
- Does it cover the key points?
- Does it over-generalize?
Citation accuracy
This is a particularly important layer for a research assistant:
- Does each claim really have support in the cited source?
A minimal evaluation data structure
Continue in the same file or Python session, because this block reuses summarize_with_citations().
eval_cases = [
{
"query": "rag retrieval grounding",
"expected_source_ids": {"d1", "d2"},
},
{
"query": "citation trust summary",
"expected_source_ids": {"d3"},
},
]
for case in eval_cases:
hit_ids = sorted(item["source_id"] for item in summarize_with_citations(case["query"]))
overlap = sorted(set(hit_ids) & case["expected_source_ids"])
print({
"query": case["query"],
"hit_ids": hit_ids,
"overlap": overlap,
})
Expected output:
{'query': 'rag retrieval grounding', 'hit_ids': ['d1', 'd2'], 'overlap': ['d1', 'd2']}
{'query': 'citation trust summary', 'hit_ids': ['d3'], 'overlap': ['d3']}
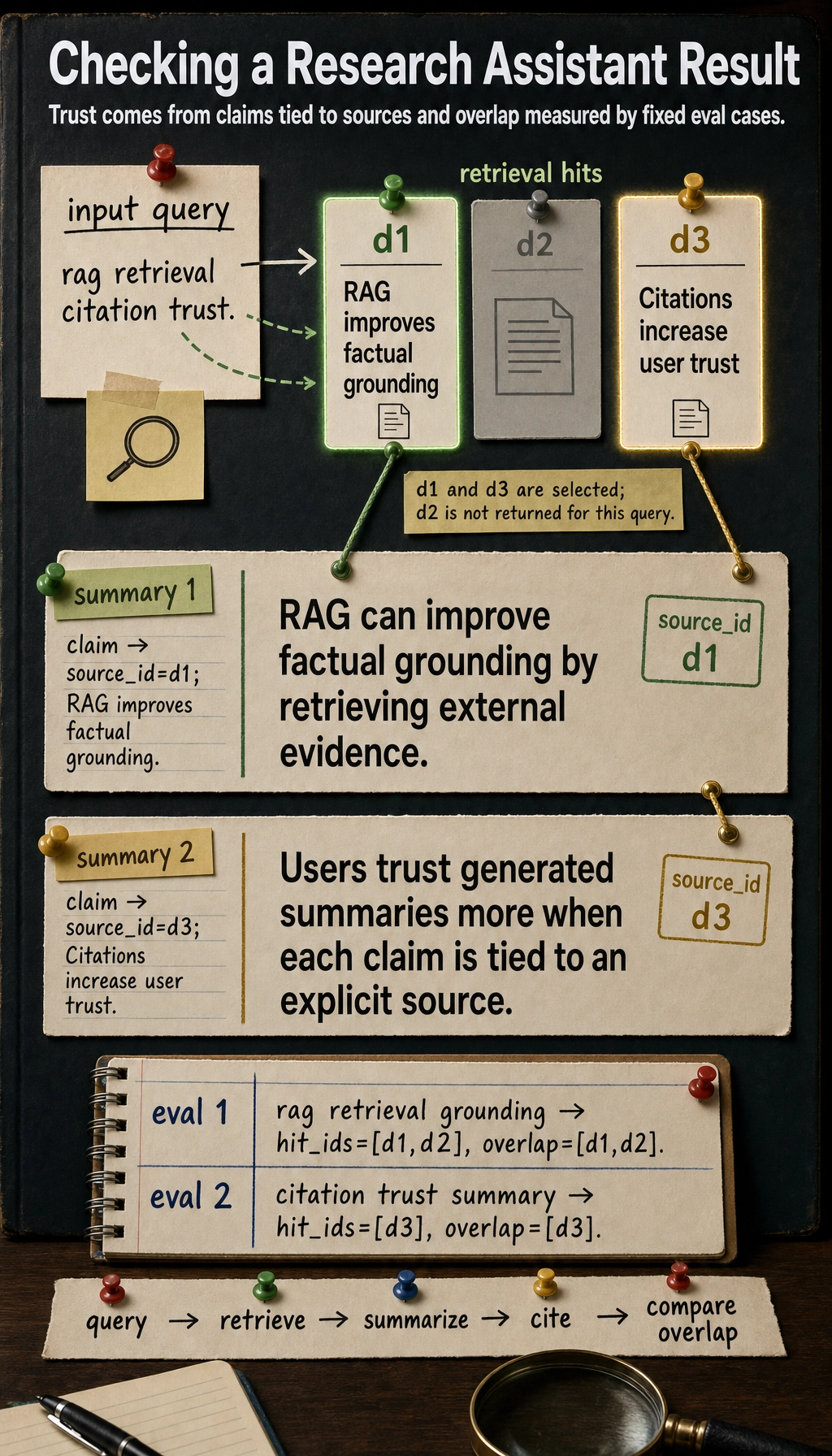
The easiest pitfalls to fall into
Retrieval is correct, but the summary loses key points
The summary sounds smooth, but the sources do not match
The project only shows one answer that “looks smart”
What is actually most worth showing in a research assistant is:
- Query
- Retrieval results
- Summary items
- Citation sources
That complete trace.
How do you polish it into a portfolio-grade project?
Show four columns on the page
- Query
- Retrieved sources
- Structured summary
- Citations
Prepare 5–10 fixed evaluation questions
This lets you consistently show:
- before / after
- retrieval strategy changes
- summary strategy improvements
List failure cases separately
For example:
- Retrieved irrelevant documents
- Missed the correct document
- Summary claim does not match the citation
What to include when delivering the project
- A flowchart from query to citation
- Side-by-side display of retrieval results and the final summary
- Failure cases where citations do not match or the summary misses important points
- A short explanation of how you define “trustworthy output”
Portfolio-grade Agent delivery standards
If you use the research assistant as an Agent portfolio project, do not just show the final summary. Instead, show the full closed loop of “goal, tools, execution, citations, evaluation, and safety boundaries.”
| Deliverable | Minimum Requirement | Portfolio-Grade Requirement |
|---|---|---|
| Goal definition | Can input a research topic | Clearly states scope, data sources, and unsupported tasks |
| Tool list | At least one retrieval or reading tool | Clearly explains each tool’s purpose, parameters, return values, and permission boundaries |
| Execution trace | Prints the retrieval and summarization process | Saves each step’s action, arguments, observation, and next decision |
| Citation checking | Each summary item has a source | Every key claim can be traced to a specific source fragment |
| Failure recovery | Returns an error when a tool fails | Distinguishes empty results, timeouts, unsupported citations, and missed summary points |
| Evaluation records | Prepares a small set of test questions | Has a fixed evaluation set, baseline, failed samples, and improvement records |
| Safety boundaries | Does not automatically execute high-risk actions | Clearly defines read-only tools, human confirmation, max steps, and cost limits |
This table upgrades the project from “can summarize materials” to a “trustworthy, traceable, and reviewable Agent system.”
Recommended README structure
A research assistant project README can be written in the following order:
# Research Assistant Agent
## 1. Project Goal
Explain what research scenario it solves and what it does not solve.
## 2. System Flow
Show query -> retrieval -> reading -> summary -> citation -> evaluation.
## 3. Tool List
List tools such as search_docs, read_source, summarize, and check_citation.
## 4. How to Run
Provide dependency installation, data preparation, example runs, and evaluation commands.
## 5. Example Trace
Show one complete execution process instead of only the final answer.
## 6. Evaluation Results
Show retrieval hits, citation accuracy, failure samples, and improvement records.
## 7. Safety and Limitations
Explain source restrictions, citation risks, maximum steps, and human confirmation boundaries.
The README should ideally let others understand what the system does, how it is validated, and where it is still unreliable without reading the source code.
A minimal Agent trace example
goal: Summarize the differences between RAG and long-context models
step 1: action=retrieve, arguments={query: "rag long context retrieval"}
observation: matched d1, d2
step 2: action=read_sources, arguments={source_ids: ["d1", "d2"]}
observation: read content related to grounding, precision, and ranking
step 3: action=summarize_with_citations
observation: generated 3 summary items, each with a source_id
step 4: action=check_citations
observation: 2 passed, 1 had insufficient evidence
final: return 2 trustworthy summaries and flag 1 for human review
The value of this trace is: if the final result has a problem, you can replay exactly which step went wrong, instead of only staring at the final answer and guessing.
Failure case library
The most common failure in a research assistant is not “completely unable to answer,” but “sounds reasonable yet is not trustworthy.” You should record at least the following failure types.
| Failure Type | Symptom | Possible Cause | Improvement Direction |
|---|---|---|---|
| Retrieval miss | Key materials never enter the candidate set | query too narrow, keyword mismatch, top-k too small | query rewrite, hybrid retrieval, expand candidates then rerank |
| Incomplete reading | The matched document is correct, but a key paragraph is missed | chunk too small or context packing is poor | parent-child retrieval, adjust context assembly |
| Over-generalized summary | The summary sounds right but drops limiting conditions | the prompt does not require preserving conditions | require output as claim, condition, source triples |
| Unsupported citation | The claim and source do not match | the model improvises or citation assembly is wrong | citation check, verify each claim one by one |
| Looping calls | The Agent keeps retrieving and never stops | missing stopping condition | maximum steps, stop when no new information appears |
Putting these failure cases into the project will show engineering ability much better than only showing success cases.
Summary
The most important idea in this section is to establish a portfolio-grade judgment:
The real highlight of a research assistant project is not “it can summarize,” but “it can organize retrieval, summarization, and citation into output that is trustworthy, traceable, and reviewable.”
Once that is in place, the project will feel much more like a mature Agent project.
Suggested version roadmap
| Version | Goal | Delivery Focus |
|---|---|---|
| Basic | Get the minimal loop working | Can input, process, and output, while keeping a set of examples |
| Standard | Turn it into a showcaseable project | Add configuration, logs, error handling, README, and screenshots |
| Challenge | Approach portfolio quality | Add evaluation, comparison experiments, failure analysis, and a next-step roadmap |
It is recommended to finish the basic version first. Do not try to make it large and complete from the beginning. Each time you level up, write into the README what new capability was added, how it was validated, and what problems remain.
Exercises
- Add another document to the example so that a query creates “competition among relevant documents.”
- Think about why “citation accuracy” is more critical in a research assistant than in ordinary Q&A.
- If a summary looks great but the source does not match, would you count it as success? Why?
- If you turn this project into a portfolio piece, which 4 sections should the homepage show first?