9.7.2 Multi-Agent Architecture Patterns
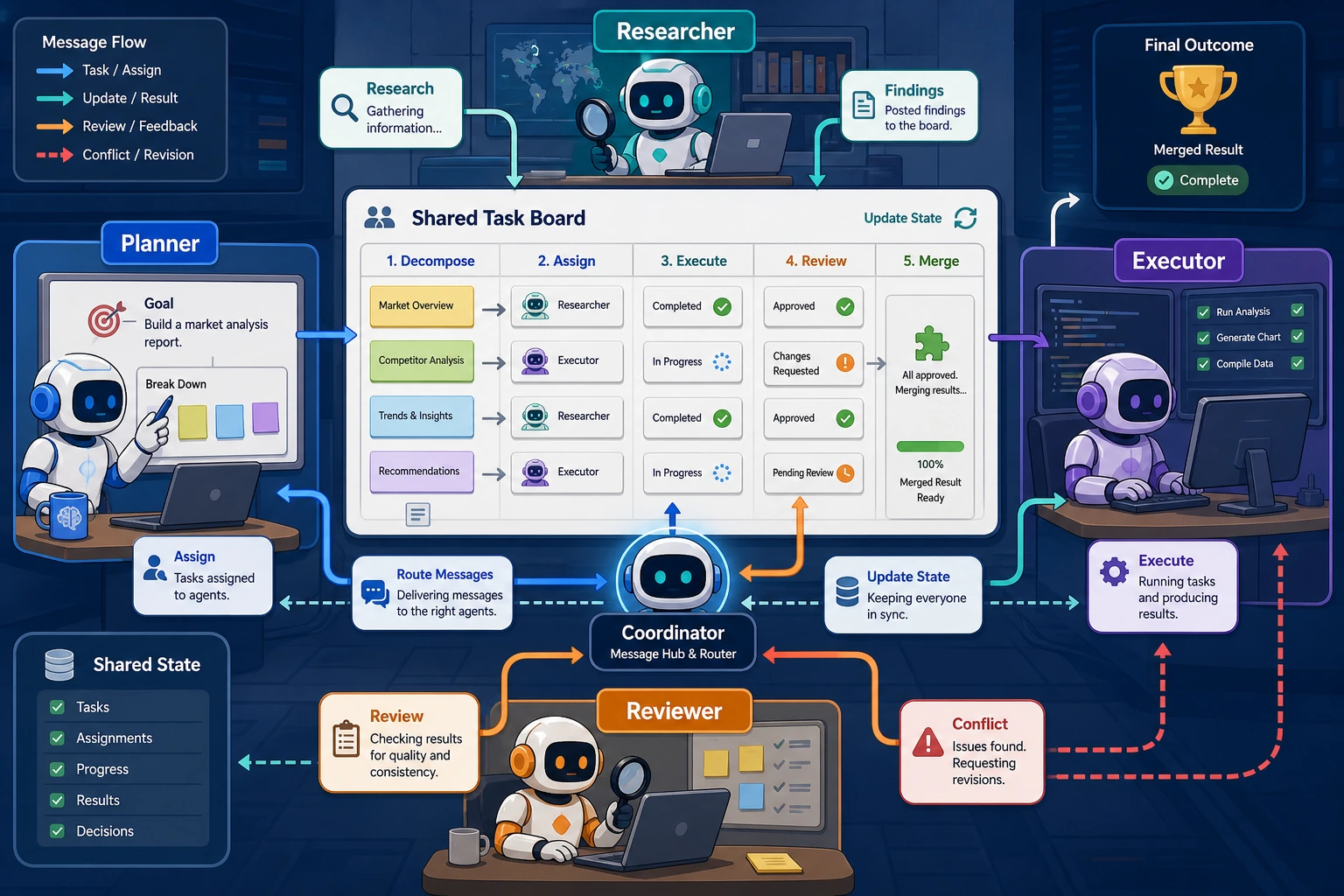
When many people build their first multi-Agent system, the easiest mistake to make is:
“If one Agent is not enough, just add more.”
But the real issue is not “how many,” it is:
How these Agents divide work, organize themselves, and collaborate.
That is the core problem multi-Agent architecture patterns are designed to solve.
Learning objectives
- Understand when you really need multiple Agents
- Distinguish the most common multi-Agent architecture patterns
- Understand the strengths and weaknesses of patterns like supervisor, pipeline, and reviewer
- Use a small example to feel how different patterns are organized
Why doesn’t every task need multiple Agents?
Multi-Agent is not the default upgrade path
If a task can already be completed stably by a single Agent, multi-Agent often only adds:
- Communication cost
- Debugging difficulty
- Failure paths
So a safer rule is usually:
First make the single-Agent version solid, then consider whether it is really necessary to split into multiple Agents.
When is it worth using multiple Agents?
Usually in these cases:
- The task can clearly be split into sub-tasks
- The sub-tasks are very different in type
- One Agent handling everything becomes too messy
- You need separate planning, execution, and review roles
Only then does multi-Agent really make sense.
First look at the most common patterns
Supervisor-Worker pattern
A supervisor is responsible for:
- Breaking down tasks
- Assigning tasks
- Summarizing results
Other workers are responsible for the actual execution.
This is one of the most common and easiest patterns to understand.
Pipeline pattern
Each Agent is responsible for a fixed stage:
- Retrieval
- Analysis
- Writing
It is more like an assembly line.
Reviewer pattern
One Agent generates output, and another is dedicated to checking or reviewing it.
This is especially common in code, documentation, and report generation.
Group / Peer pattern
Multiple Agents collaborate as peers and negotiate with each other.
This pattern is more flexible, but also harder to control.
Supervisor-Worker: the first pattern worth learning
Why is it so common?
Because it matches many real-world team structures:
- A project manager or team lead breaks down the work
- Team members handle the actual tasks
A minimal runnable example
tasks = ["retrieve materials", "organize key points", "write summary"]
workers = {
"researcher": "responsible for finding materials",
"analyst": "responsible for organizing information",
"writer": "responsible for generating the final text"
}
assignment = {
"retrieve materials": "researcher",
"organize key points": "analyst",
"write summary": "writer"
}
for task in tasks:
worker = assignment[task]
print(f"{worker} <- {task} ({workers[worker]})")
Expected output:
researcher <- retrieve materials (responsible for finding materials)
analyst <- organize key points (responsible for organizing information)
writer <- write summary (responsible for generating the final text)
Its strengths and weaknesses
Strengths:
- Clear division of labor
- Easier to control
- Easier to see which step has a problem
Weaknesses:
- The supervisor may become a bottleneck
- If task decomposition is poor, everything after that will be affected
Pipeline pattern: collaboration like a factory assembly line
How is it different from the supervisor pattern?
The supervisor pattern emphasizes “one central controller.” The pipeline pattern emphasizes “tasks flowing through fixed stages.”
For example:
- Retriever Agent finds materials
- Filter Agent removes noise
- Writer Agent generates the answer
A minimal example
def retriever(query):
return {"docs": ["refund policy", "certificate instructions"], "query": query}
def filter_agent(data):
return {"docs": [doc for doc in data["docs"] if "refund" in doc], "query": data["query"]}
def writer(data):
if not data["docs"]:
return "No sufficiently relevant information found."
return f"Based on {data['docs']}, generate the final answer."
query = "What is the refund policy"
step1 = retriever(query)
step2 = filter_agent(step1)
step3 = writer(step2)
print(step1)
print(step2)
print(step3)
Expected output:
{'docs': ['refund policy', 'certificate instructions'], 'query': 'What is the refund policy'}
{'docs': ['refund policy'], 'query': 'What is the refund policy'}
Based on ['refund policy'], generate the final answer.
What is it suitable for?
Suitable for:
- Fixed stages
- Clear order
- Very explicit responsibilities at each layer
Not very suitable for:
- Frequent plan revisions
- A lot of flexible negotiation
Reviewer pattern: separating generation and checking
Why is this pattern so practical?
In many tasks, “generation” and “review” are naturally two different abilities.
For example:
- Code writing vs. code review
- Report writing vs. fact checking
- Answer generation vs. risk review
A runnable example
def writer_agent(topic):
return f"Draft about {topic}: courses are refundable within 7 days after purchase."
def reviewer_agent(text):
if "within 7 days" in text:
return {"approved": True, "comment": "Key information is covered"}
return {"approved": False, "comment": "Missing the core time condition"}
draft = writer_agent("refund policy")
review = reviewer_agent(draft)
print("draft :", draft)
print("review:", review)
Expected output:
draft : Draft about refund policy: courses are refundable within 7 days after purchase.
review: {'approved': True, 'comment': 'Key information is covered'}
Why is this pattern useful?
Because it separates “generation quality” from “checking quality” so they can be managed independently.
This is especially valuable in high-risk tasks.
Peer / Group pattern: multiple Agents collaborate as equals
It looks very free, but it is also harder to control
In this pattern, multiple Agents can propose ideas, debate, and add details.
Strengths:
- Flexible
- Easy to generate multiple solutions
Weaknesses:
- Easy to duplicate work
- Easy to drift off topic
- Harder to converge
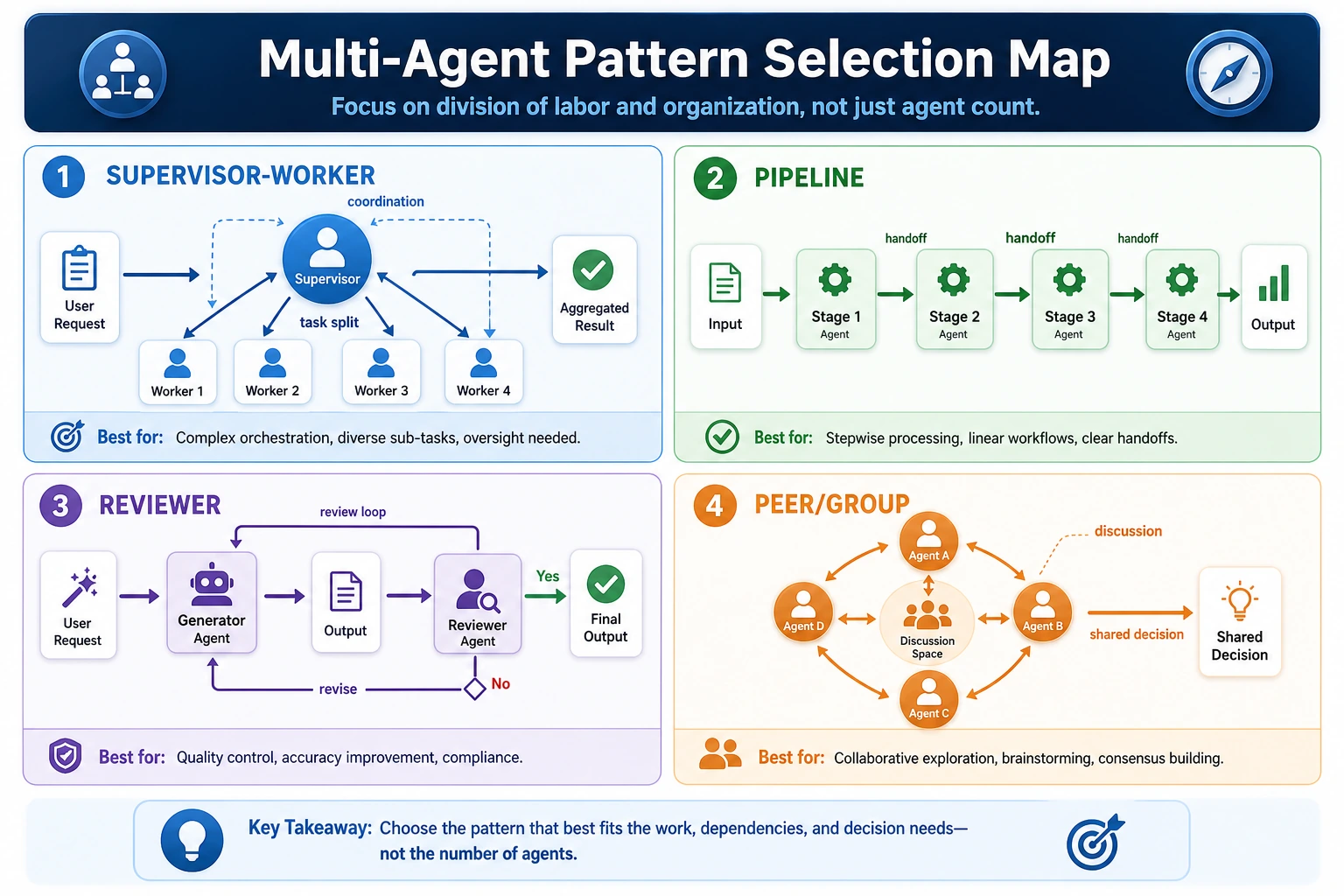
When reading this diagram, first check whether the task has a natural division of labor: choose supervisor-worker if you need central scheduling, choose pipeline if the stages are fixed, add a reviewer if you need quality checks, and only consider peer/group when you truly need multi-perspective discussion.
When should you consider it?
It is a better fit for:
- Brainstorming
- Comparing solutions
- Multi-perspective analysis
But for many engineering systems, it may not be the most stable starting point.
A very important question: who closes the loop?
No matter which pattern you use, you must answer this question:
Who is ultimately responsible for deciding that the task is done?
If this is not designed clearly, it is easy to get:
- Everyone working, but nobody closing the loop
- Multiple Agents sending messages back and forth
- The task never ending
That is also why many multi-Agent systems still end up with a “final decision maker.”
How to choose a multi-Agent architecture
If the task stages are fixed
Prefer:
- Pipeline pattern
If the task needs central decomposition and scheduling
Prefer:
- Supervisor-Worker pattern
If the task needs strong review and verification
Prefer:
- Writer-Reviewer pattern
If the task itself is multi-perspective discussion
Only then consider:
- Peer / Group pattern
So the most important question is not “which pattern is more advanced,” but:
Which pattern matches the shape of your task best?
Common mistakes beginners often make
Treating multi-Agent as “just run a few more models”
What is really hard is the architecture, not the number.
Choosing the most flexible collaboration pattern right away
The higher the flexibility, the harder debugging and convergence usually become.
Not defining an end condition
This is the root cause of many multi-Agent demos looking smart but getting stuck in infinite loops when actually run.
Summary
The most important thing in this section is not memorizing pattern names, but understanding:
The core of multi-Agent architecture patterns is to split tasks into appropriate roles and collaboration relationships, not simply to increase the number of participants.
Choose the right architecture pattern, and the system will be more stable and controllable; choose the wrong one, and complexity will grow faster than the benefits.
Exercises
- Explain the differences between the supervisor, pipeline, and reviewer patterns in your own words.
- Think about this: if you want to build an “automatic research report” system, which pattern is most suitable to implement first? Why?
- Design a three-Agent pipeline: “retrieval -> writing -> review.”
- Reflect: why do we say multi-Agent architecture is first an organizational problem, not a model-count problem?