9.2.3 Chain-of-Thought Reasoning Strategy
If we summarize the previous section in one sentence, it is:
- Reasoning problems depend on intermediate states
Then this section asks:
How do we make the model more willing, and more consistent, to write intermediate states explicitly?
The Chain-of-Thought strategy, or CoT, is built around one core idea:
- Don’t ask for the answer directly
- First let the model break the problem into steps, then give the conclusion
Learning Objectives
- Understand why Chain-of-Thought reasoning improves multi-step task performance
- Understand what kinds of tasks CoT is suitable for, and what kinds it is not
- Use runnable examples to understand the difference between “answer directly” and “answer step by step”
- Understand how to use structured reasoning in production instead of uncontrolled long-form text
Why does “thinking through the steps first” help?
Because many problems do not reach the end in one jump
For example, consider this problem:
- A product originally costs 80 yuan, gets 20% off, and then another 5 yuan is subtracted. What is the final price?
If the model generates the answer directly, it may make very typical mistakes:
- Treat “20% off” as subtracting 20 yuan
- Forget the final 5 yuan discount
- Get the step order wrong
But if it first breaks the process into steps:
80 * 0.8 = 6464 - 5 = 59
the final answer is usually more stable.
The core of CoT is not “writing more,” but “exposing intermediate structure”
This point is especially important. The real value of Chain-of-Thought is not:
- Making the output longer
But rather:
- Making local facts
- Intermediate variables
- Step dependencies
explicit.
An analogy: scratch paper is not for looking serious
When students solve problems, they use scratch paper not to make the answer longer, but to:
- prevent the mental state from being lost
- break a complex problem into smaller parts
- make checking easier
CoT plays a similar role for models.
First, let’s compare “direct answer” and “chain reasoning”
The example below does not call an LLM, but it clearly demonstrates:
- Why a “rough direct mapping” is easy to get wrong
- Why “break the steps first, then calculate” is more stable
import re
problem = "A product originally costs 80 yuan, gets 20% off, and then another 5 yuan is subtracted. What is the final price?"
def bad_direct_answer(text):
numbers = list(map(int, re.findall(r"\d+", text)))
original, discount, minus = numbers
# Common mistake: misreading “20% off” as “subtract 20”
return original - discount - minus
def chain_reason_answer(text):
original, discount, minus = map(int, re.findall(r"\d+", text))
steps = []
discounted_price = original * (1 - discount / 100)
steps.append(f"First calculate the discounted price: {original} * (1 - {discount}/100) = {discounted_price}")
final_price = discounted_price - minus
steps.append(f"Then subtract the extra {minus} yuan: {discounted_price} - {minus} = {final_price}")
return final_price, steps
print("problem:", problem)
print("bad direct answer:", bad_direct_answer(problem))
answer, steps = chain_reason_answer(problem)
print("\nchain reasoning steps:")
for step in steps:
print("-", step)
print("final answer:", answer)
Expected output:
problem: A product originally costs 80 yuan, gets 20% off, and then another 5 yuan is subtracted. What is the final price?
bad direct answer: 55
chain reasoning steps:
- First calculate the discounted price: 80 * (1 - 20/100) = 64.0
- Then subtract the extra 5 yuan: 64.0 - 5 = 59.0
final answer: 59.0
What does this code show most clearly?
It shows that:
- Direct mapping can easily misinterpret the problem
- Explicitly breaking the steps makes errors easier to expose
For example:
- Does “20% off” mean
-20or*0.8?
As soon as you write that step out, the mistake is much harder to hide.
Why is CoT especially useful for math, logic, and planning tasks?
Because these tasks usually have:
- Clear intermediate variables
- Clear step order
- Clear local dependencies
That naturally matches chain reasoning.
Why shouldn’t CoT be used for every task?
Because not every problem needs step-by-step reasoning. For example:
- “What is the capital of France?”
This kind of question is more like retrieval, and does not need a long reasoning chain.
So CoT is not about “the more, the better” by default, but rather:
- More valuable for multi-step problems
How is CoT usually used in Agents?
First decompose, then call tools
In many Agent tasks, CoT is not directly used for arithmetic, but to decide:
- What to do first
- What to do next
- Which step needs a tool
For example:
- Identify the problem type
- Decide whether to check policy first or inventory first
- After getting observations, organize the conclusion
It can also become more structured “reasoning slots”
In production, we do not always need the model to output a long natural-language thought process. Many systems instead switch to a shorter, more structured format, such as:
factssubtasksdecisionnext_action
This kind of structure is often easier to:
- validate
- log
- debug
CoT is also often combined with self-checking
A very common enhancement is:
- Reason first
- Check key steps
- Output the final answer
This can reduce some careless mistakes.
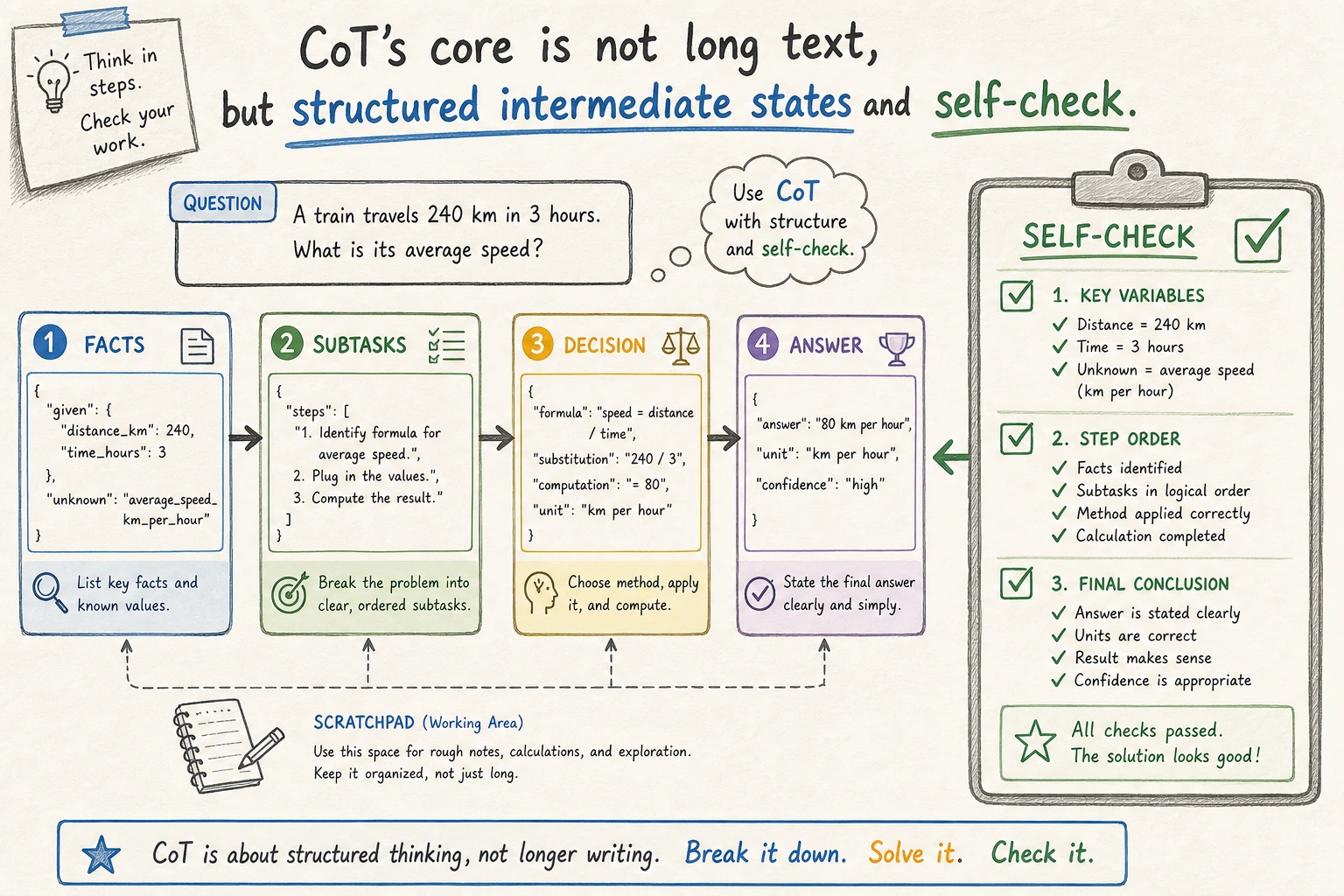
This diagram emphasizes “structured intermediate states,” not letting the model output endless long-form thinking. In production, reasoning is more often compressed into verifiable slots such as facts, subtasks, decision, and next_action.
When is CoT most helpful?
Problems that require step-by-step decomposition
For example:
- Multi-step calculation
- Conditional filtering
- Combined decision-making
- Complex rule checking
Problems that require explaining the process
For example:
- Why recommend this solution
- Why can’t this request be executed
- Why does this answer follow the rules
When the system must provide not only a conclusion but also a reason, explicit intermediate steps are very valuable.
Problems with high error cost
If a mistake in calculation or judgment can lead to serious consequences, then explicit steps are usually more worthwhile.
When might CoT actually hurt performance?
Simple retrieval questions
If the problem itself does not require step-by-step reasoning, forcing the model to output a long process usually just means:
- slower
- longer
- more expensive
A reasoning chain that is too long can confuse itself
When the chain gets too long, the model may:
- Have correct early steps but drift later
- Repeat explanations
- Become inconsistent in intermediate states
In other words, longer CoT is not automatically better.
It may not be suitable to expose the full chain to users
In many products, a more reasonable approach is:
- Keep the reasoning structure internal
- Show users only a concise explanation
Because what users usually need is:
- A clear conclusion
- Necessary reasons
Not a long scratchpad.
A more practical structured CoT pattern
The following example shows a style that is more suitable for Agents:
- Do not output a large block of free-form text
- Instead, split it into fixed slots
ticket = {
"question": "The order has not shipped yet. The item originally costs 80 yuan, gets 20% off, and then another 5 yuan is subtracted. What is the refund amount?",
"policy": "Unshipped orders can be refunded through the original payment method.",
}
def structured_reasoning(ticket):
facts = [
"The order has not shipped yet, so it can be refunded through the original payment method",
"The item originally costs 80 yuan, gets 20% off, and then another 5 yuan is subtracted",
]
calculation = ["80 * 0.8 = 64", "64 - 5 = 59"]
decision = "The refund amount should be 59 yuan, returned through the original payment method."
return {
"facts": facts,
"calculation": calculation,
"decision": decision,
}
result = structured_reasoning(ticket)
print(result)
Expected output:
{'facts': ['The order has not shipped yet, so it can be refunded through the original payment method', 'The item originally costs 80 yuan, gets 20% off, and then another 5 yuan is subtracted'], 'calculation': ['80 * 0.8 = 64', '64 - 5 = 59'], 'decision': 'The refund amount should be 59 yuan, returned through the original payment method.'}
The advantages of this format are:
- Easier to read
- Easier to test
- Easier to post-process
Common misconceptions
Misconception 1: CoT just means making the model more verbose
No. The core is:
- Making intermediate structure explicit
Misconception 2: All tasks should use CoT by default
Not true. Whether to enable it depends on whether the problem is truly multi-step.
Misconception 3: With CoT, the answer is always reliable
Also not true. Chain reasoning can improve stability, but it does not automatically eliminate all errors.
Summary
The most important thing in this section is not remembering the English name Chain-of-Thought,
but building a practical judgment:
When a problem depends on multi-step intermediate states, letting the model explicitly break down the steps often improves stability; but the value of CoT lies in structured intermediate process, not in endlessly lengthening the output.
Once you understand that clearly, the next time you see:
- ReAct
- Plan-and-Execute
- Self-checking and evaluation
it will be much easier to understand that they are continuing to organize reasoning on top of CoT.
Exercises
- Replace the discount problem in the example with your own multi-step problem, and compare
bad_direct_answerandchain_reason_answer. - Why do we say the core value of CoT lies in “explicit intermediate structure” rather than “longer output”?
- Think of a simple question that is not suitable for CoT, and explain why.
- If you were using CoT in a product, would you prefer free-form text or structured slots? Why?