9.2.2 LLM Reasoning Capability
When many people first encounter Agents, they naturally think of large models as:
- able to chat
- able to write
- able to call tools
But what really gives an Agent a “brain” is not just whether it can talk, but:
When faced with a complex problem, can it break the problem apart, keep track of intermediate states, and gradually reach a conclusion?
That is what reasoning capability is meant to solve.
Learning Objectives
- Understand that “knowledge retrieval” and “reasoning-based problem solving” are not the same thing
- Understand the three common task patterns of LLM reasoning
- Learn through a runnable example why “intermediate state” matters
- Understand why Agents cannot rely on tools alone and still need a reasoning layer
How This Section Connects to the Previous Agent Basics
If you just finished learning “What is an Agent?”, you can think of this section as:
- You already know that an Agent needs to take actions around a goal
- This section starts answering: what does it actually rely on to break down complex problems and maintain intermediate states?
So what matters most in this section is not “reasoning sounds advanced,” but:
- What exactly does the reasoning layer do in an Agent system?
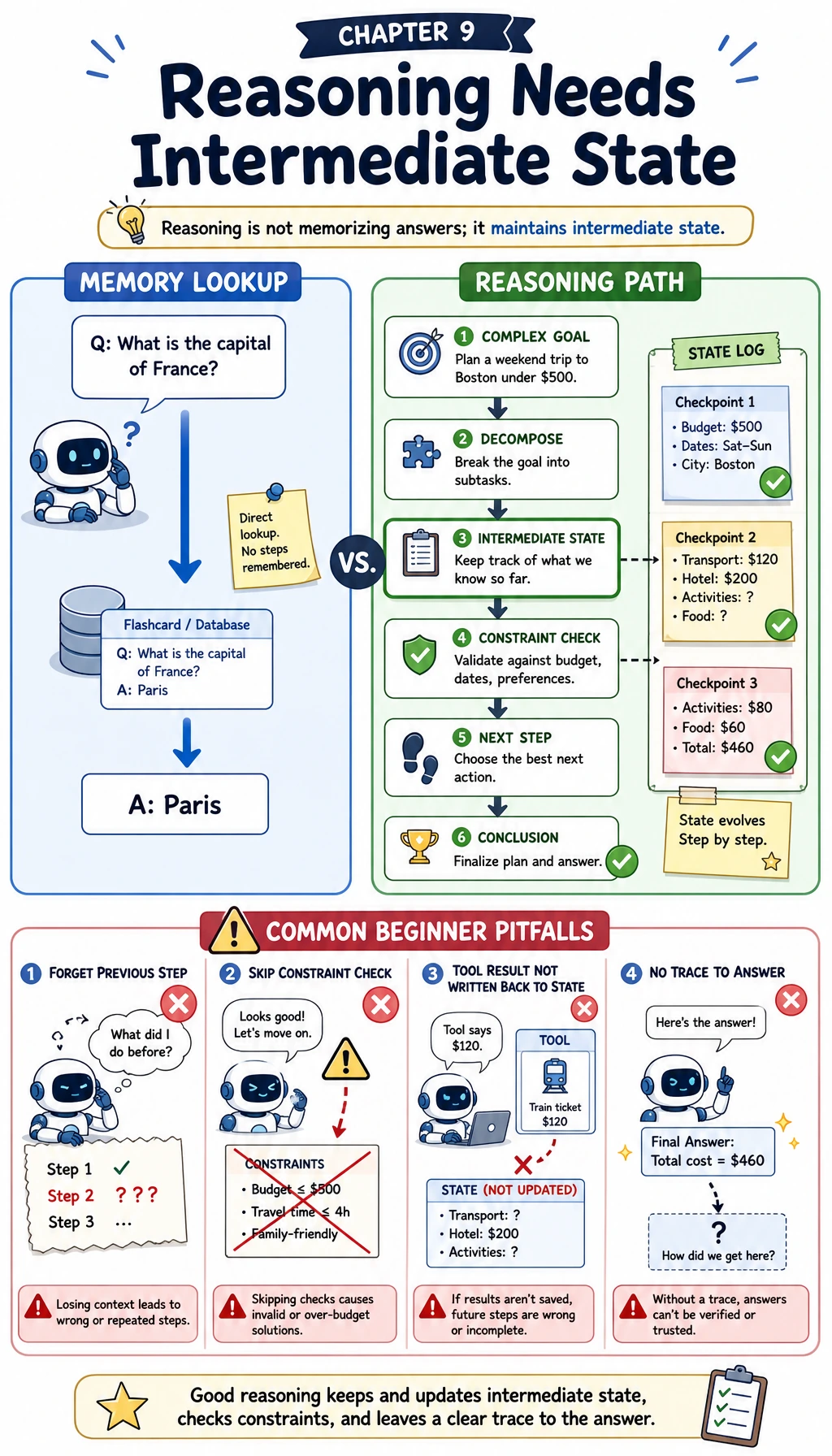
What Is “Reasoning,” and How Is It Different from “Remembering Answers”?
Remembering answers: like looking up an internal dictionary
If I ask:
- What is the capital of France?
The model is more like it is using a knowledge pattern it has already learned. This kind of question is closer to:
- memory
- retrieval
- pattern matching
Reasoning: the answer is not directly written in the question
If I ask:
- What is
3 * (4 + 2) - 5?
The model cannot rely only on “having memorized this formula.” It needs to do:
- Calculate the expression inside the parentheses first
- Then do multiplication
- Finally do subtraction
In other words:
The key to a reasoning problem is not whether the model has seen the exact question before, but whether it can maintain a correct chain of intermediate states.
When learning reasoning for the first time, what should you focus on most?
What you should focus on first is not terminology, but this sentence:
The hardest part of reasoning is not the final answer, but whether each intermediate step stays correct all the way through.
Once this idea is solid, later when you see:
- Chain-of-Thought
- ReAct
- Plan-and-Execute
you can naturally understand them as ways of helping the model preserve the chain of intermediate states.
An analogy: reasoning is like cooking, not just naming a dish
“Knowing what Kung Pao Chicken is” is more like knowledge. “Marinate the chicken, then stir-fry the aromatics, then add the sauce, then reduce it” is more like reasoning.
It requires the system to:
- know the order
- remember intermediate results
- avoid skipping steps
What Three Types of Problems Do LLM Reasoning Commonly Face?
Arithmetic and symbolic reasoning
For example:
- multi-step arithmetic
- date and time calculation
- unit conversion
The characteristics of these problems are:
- the conclusion depends on the steps
- if one step is wrong, everything that follows is wrong
Constraint satisfaction and comparative decision-making
For example:
- choosing a plan under budget, time, and inventory constraints
- scheduling
- route planning
These problems are not necessarily just arithmetic. They emphasize:
- multiple conditions must hold at the same time
- intermediate judgments must not contradict each other
State integration before and after tool use
This is the most common type in Agent scenarios.
For example:
- Check the weather first
- Then check the flight
- Finally decide whether to reschedule
The tool gives you external information, but turning that information into a conclusion still requires reasoning.
Why are these three types especially suitable as an entry point for learning Agents?
Because they are not “look it up and you’re done” problems. Instead, they require:
- breaking the task into steps
- saving intermediate results
- integrating external observations back in
That is exactly the core work of the reasoning layer in an Agent.
Let’s First Run a Real Example That Clearly Shows “Intermediate State”
The code below parses an expression into an abstract syntax tree, then evaluates it recursively while recording each step of the calculation.
It is not simulating the LLM itself, but it helps you build a very important intuition:
The core of a multi-step problem is not the final answer, but how intermediate states are passed along correctly.
import ast
import operator
OPS = {
ast.Add: ("+", operator.add),
ast.Sub: ("-", operator.sub),
ast.Mult: ("*", operator.mul),
ast.Div: ("/", operator.truediv),
}
def solve(node):
if isinstance(node, ast.Constant):
return node.value, []
if isinstance(node, ast.BinOp):
left_value, left_steps = solve(node.left)
right_value, right_steps = solve(node.right)
symbol, fn = OPS[type(node.op)]
result = fn(left_value, right_value)
step = f"{left_value} {symbol} {right_value} = {result}"
return result, left_steps + right_steps + [step]
raise TypeError(f"Unsupported node: {type(node)}")
expression = "3 * (4 + 2) - 5"
tree = ast.parse(expression, mode="eval").body
answer, steps = solve(tree)
print("expression:", expression)
print("steps:")
for step in steps:
print("-", step)
print("answer:", answer)
Expected output:
expression: 3 * (4 + 2) - 5
steps:
- 4 + 2 = 6
- 3 * 6 = 18
- 18 - 5 = 13
answer: 13
What is most worth learning from this code is not ast
What is truly worth taking away is:
- each step produces a clear intermediate result
- the next step depends on the previous one
- the final answer is only the last layer of state
This is very similar to how LLMs handle complex reasoning.
Why is intermediate state more important than the “final answer”?
Because if one intermediate step is wrong, even if you happen to get the final answer right, it is hard to reproduce the result reliably.
What a reasoning system should really pursue is:
- a dependable process
- errors that can be traced
not accidentally hitting the right answer once.
Why do Agents especially depend on this ability?
Because the problems Agents handle are usually not completed in one step. They may need to:
- read the requirement first
- then query data
- then compare constraints
- and finally choose an action
This is essentially maintaining a longer chain of intermediate states.
Why is this code more educational than just “getting the final answer right”?
Because it clearly shows you:
- how each step comes about
- what the next step depends on
- exactly where an error starts to propagate
And that is precisely what an Agent system needs most:
- a readable process
- checkable intermediate states
- traceable errors
Why Is LLM Reasoning Sometimes Strong, but Sometimes Suddenly Unstable?
It is good at patterned step-by-step structure
If the task can be organized into fairly clear steps, LLMs often perform well, for example:
- decomposing a problem
- explaining reasons
- generating candidate solutions
It can drift on long chains
Common issues include:
- missing steps
- repeating steps
- making mistakes in intermediate numbers
- conflicting constraints from beginning to end
In other words, LLM reasoning is not a “stable logic engine,” but more like:
- a language-based reasoner that is good at drafting steps
That is why many complex tasks need external tools
For example:
- use a calculator for precise numeric calculations
- use a database to check the real state
- use a rules engine to detect constraint conflicts
In an Agent, the reasoning layer often does not work alone, but cooperates with tools.
Why are “can reason” and “can chat” completely different things?
Because chatting is more like:
- fluent language
- natural style
while reasoning is more like:
- steps must be correct
- constraints must not conflict
- intermediate states must remain stable
This is why a model that seems “very good at talking” can still fail in complex multi-step tasks.
When Should You Turn on a “Stronger Reasoning Mode”?
When the answer requires multiple steps of derivation
If the problem clearly requires:
- step-by-step calculation
- sequential judgment
- condition filtering
then it is worth using a more explicit reasoning strategy.
When the cost of errors is high
For example:
- financial calculations
- configuration changes
- assisted medical advice
In these problems, “looks reasonable” is not enough. What is needed more is:
- a process that can be verified
When the problem depends on external observations
For example:
- check inventory first, then make a purchasing suggestion
- check flights first, then decide whether to reschedule
At this point, reasoning must be combined with tool-based observations.
The Most Common Misconceptions
Misconception 1: If the model is big enough, it will naturally reason well
Larger models usually bring a higher ceiling, but that does not mean all complex reasoning will be stable.
Misconception 2: Reasoning just means writing out more steps
No. Truly effective reasoning means:
- the steps depend on one another
- intermediate states can be reused
- the final answer is supported by the process
Misconception 3: If you have tools, you do not need reasoning
Tools only provide external capabilities. Deciding:
- when to call them
- which one to call
- how to integrate the results
still depends on reasoning.
Summary
The most important thing in this lesson is not to mystify “reasoning,” but to first build a clear judgment:
The essence of LLM reasoning capability is to maintain correct intermediate states in multi-step problems, and integrate external information, constraint conditions, and local results into a final conclusion.
Once you establish this understanding, when you later learn:
- CoT
- ReAct
- Plan-and-Execute
you will see that they are all helping the model complete this task more stably.
What You Should Take Away from This Lesson
- Reasoning is not “writing the answer longer,” but maintaining a correct chain of intermediate states
- Agents need reasoning because many tasks are not completed in a single step
- Tools provide capabilities, while reasoning organizes those capabilities and results
Exercises
- Replace the expression in the example with
12 / (3 + 1) + 7and see whether the step output matches your expectations. - Explain in your own words: why is the key to a reasoning problem in the “intermediate state” and not only the “final answer”?
- Think of an Agent task you have done, and identify at least two places where one step clearly depends on the result of the previous step.
- Why does “having tools” not mean “being able to reason”?