9.2.4 ReAct Framework
CoT solves this problem:
- Break the steps down first, then answer
But Agent often faces another kind of problem:
- Reasoning alone is not enough
- It must query, calculate, search, or inspect the external world
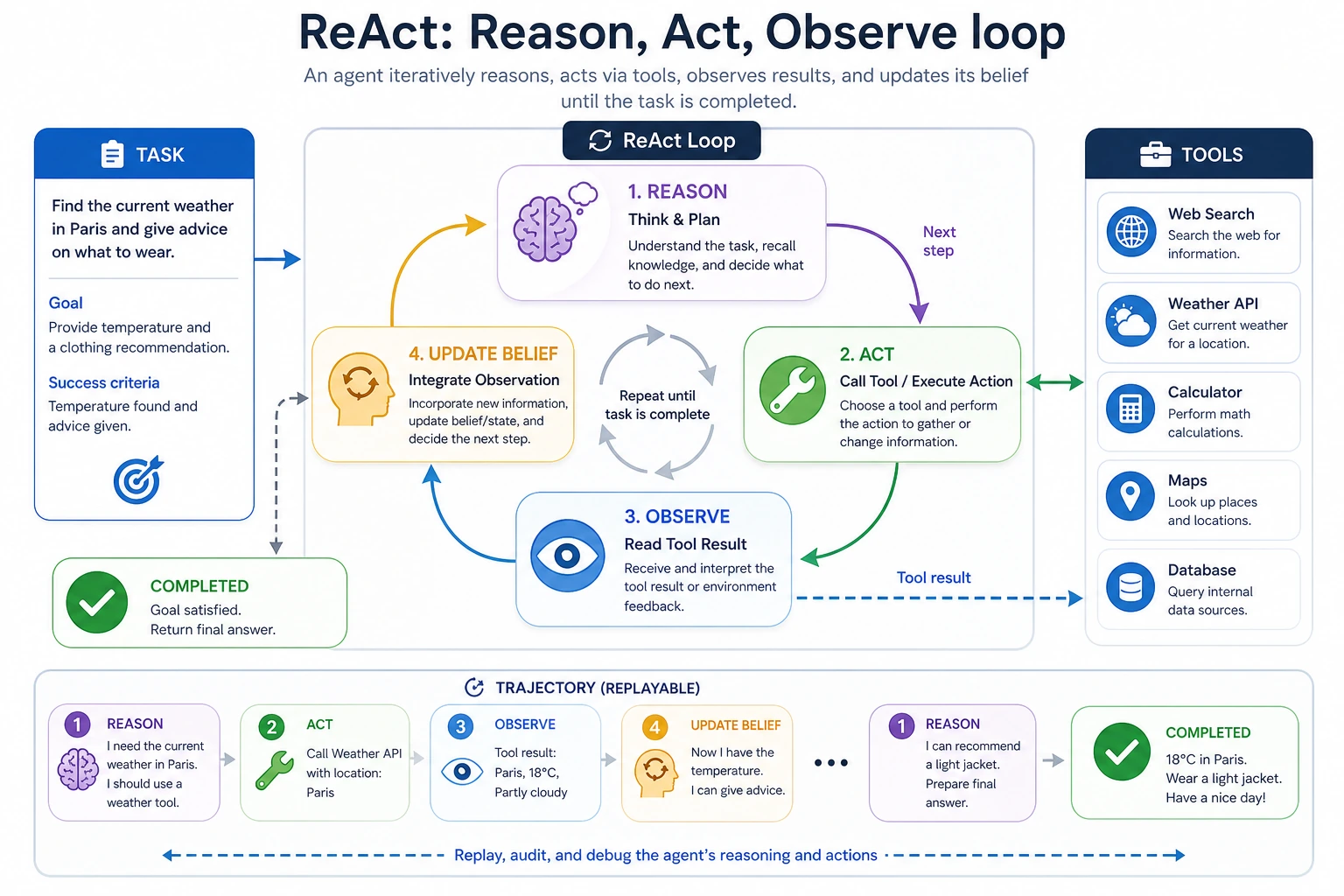
At this point, the system needs not just “thinking,” but also “acting.” The core idea of ReAct is to intertwine the two:
Think about the next step first, then call a tool to get an observation, and then continue thinking based on that observation.
Learning Objectives
- Understand the core ReAct loop:
Thought -> Action -> Observation - Understand how it differs from pure CoT
- Learn a minimal, runnable ReAct agent loop through an example
- Understand what kinds of problems ReAct is best for, and when it becomes cumbersome
Why is “thinking” alone not enough?
Because many answers are not in the model’s head
For example:
- What is the weather in Beijing today?
- What is the current status of a certain order?
- What is the exact sum of these two numbers?
These questions depend on:
- Real-time external information
- Precise tool capabilities
If the model only relies on itself to “guess,” it can lead to:
- Hallucinations
- Overconfidence
- Calculation errors
The essence of ReAct: think while getting new information
Its typical loop is:
ThoughtWhat information am I missing now?ActionWhich tool should I call?ObservationWhat did the tool return?- Enter the next round of thinking
This allows the Agent to do more than just “make up an answer in its head,” and instead gradually move closer to the real environment.
An analogy: like doing an investigation, not writing in isolation
Pure CoT is more like solving a problem on scratch paper. ReAct is more like doing an investigation:
- First think about what to check
- Gather evidence
- Then continue judging based on the evidence
The fundamental difference between ReAct and CoT
CoT focuses on “internal reasoning”
The core questions are:
- How to break down the steps
- How to maintain intermediate state
ReAct focuses on “reasoning + external interaction”
It adds another layer:
- When should it ask the outside world for information?
So ReAct is more like:
- CoT + Tool Loop
Why is this especially important for Agents?
Because Agents do more than static Q&A. They often need to:
- Query a knowledge base
- Call a database
- Perform calculations
- Execute commands
All of these require the system to continuously connect with the external world during reasoning.
First run a real minimal ReAct closed loop
The following example simulates a small e-commerce assistant. The user asks:
- What is the refund policy?
- For an order amount of
299 + 15, how much will be refunded in the end?
The Agent needs to:
- Check the refund policy first
- Then call the calculator
- Finally combine the information into an answer
import ast
import operator
OPS = {
ast.Add: operator.add,
ast.Sub: operator.sub,
ast.Mult: operator.mul,
ast.Div: operator.truediv,
}
def safe_calculate(expression):
def visit(node):
if isinstance(node, ast.Expression):
return visit(node.body)
if isinstance(node, ast.Constant) and isinstance(node.value, (int, float)):
return node.value
if isinstance(node, ast.BinOp) and type(node.op) in OPS:
return OPS[type(node.op)](visit(node.left), visit(node.right))
if isinstance(node, ast.UnaryOp) and isinstance(node.op, ast.USub):
return -visit(node.operand)
raise ValueError("unsupported_expression")
return visit(ast.parse(expression, mode="eval"))
def search_policy(topic):
policies = {
"refund": "Unshipped orders can be refunded directly. The amount will be returned to the original payment method, usually within 3 to 7 business days.",
}
return policies.get(topic, "No related policy found.")
def calculator(expression):
return str(safe_calculate(expression))
def policy(state):
trace = state["trace"]
question = state["question"]
if not any(item["action"] == "search_policy" for item in trace):
return {
"thought": "I need to confirm the refund policy first before answering the policy part.",
"action": "search_policy",
"args": {"topic": "refund"},
}
if not any(item["action"] == "calculator" for item in trace):
return {
"thought": "Now that I know the policy, I should calculate the refund amount 299 + 15.",
"action": "calculator",
"args": {"expression": "299 + 15"},
}
policy_text = next(item["observation"] for item in trace if item["action"] == "search_policy")
amount = next(item["observation"] for item in trace if item["action"] == "calculator")
return {
"thought": "I have enough information now, so I can provide the final answer.",
"action": None,
"answer": f"{policy_text} The estimated refund amount for this order is {amount} yuan.",
}
TOOLS = {
"search_policy": search_policy,
"calculator": calculator,
}
def run_react(question, max_steps=5):
state = {"question": question, "trace": []}
for _ in range(max_steps):
decision = policy(state)
if decision["action"] is None:
return state["trace"], decision["answer"]
tool_name = decision["action"]
observation = TOOLS[tool_name](**decision["args"])
state["trace"].append(
{
"thought": decision["thought"],
"action": tool_name,
"args": decision["args"],
"observation": observation,
}
)
return state["trace"], "Maximum steps reached, task not completed."
trace, answer = run_react("What is the refund policy? For an order amount of 299 + 15, how much will be refunded in the end?")
print("trace:")
for item in trace:
print(item)
print("\nfinal answer:")
print(answer)
Expected output:
trace:
{'thought': 'I need to confirm the refund policy first before answering the policy part.', 'action': 'search_policy', 'args': {'topic': 'refund'}, 'observation': 'Unshipped orders can be refunded directly. The amount will be returned to the original payment method, usually within 3 to 7 business days.'}
{'thought': 'Now that I know the policy, I should calculate the refund amount 299 + 15.', 'action': 'calculator', 'args': {'expression': '299 + 15'}, 'observation': '314'}
final answer:
Unshipped orders can be refunded directly. The amount will be returned to the original payment method, usually within 3 to 7 business days. The estimated refund amount for this order is 314 yuan.

Read the image as a trace ledger: the first observation supplies the refund policy, the second observation supplies the calculated amount, and the final answer combines both instead of repeating only the last tool output.
How should you read this code?
It is recommended to read it in this order:
- Start with
policyUnderstand how the agent decides the “next step” each round - Then look at
TOOLSUnderstand where external capabilities come from - Finally look at
run_reactUnderstand how the full loop gradually accumulates the trace
Why is trace so important?
Because ReAct does not answer in one shot, but progresses step by step.
With a trace, you can know:
- What it thought
- What it called
- What it saw
- Why it gave that final answer
This is crucial for debugging.
Why is ReAct often stronger than “calling a tool directly once”?
Because real problems are often not solved in a single step. The order of tool calls may depend on the result of the previous step.
For example here:
- First confirm the policy
- Then calculate the amount
- Then compose the answer
This is exactly the kind of structure ReAct is best at.
When is ReAct most useful?
Tasks that require multiple rounds of observation
For example:
- Search first, then calculate
- Check first, then compare
- Inspect the status first, then decide the next step
Tool call order is not fixed
If every task is strictly:
- Check A
- Check B
- Output
Then a normal workflow may be enough.
ReAct is more suitable when:
- The result of the current step affects the next choice
You need process traceability
Because ReAct naturally has:
- thought
- action
- observation
This makes it a good fit for:
- Debugging
- Replay
- Error analysis
What are the most common problems with ReAct?
The loop is too long
If the agent keeps:
- Thinking
- Acting
- Thinking again
- Acting again
Then it can become:
- Slow
- Expensive
- Prone to drifting off track
Choosing the wrong tool
ReAct does not guarantee the right tool is chosen each round. It may:
- Query the wrong knowledge source
- Call the same tool repeatedly
- Call a tool that is actually unnecessary
Failure to integrate the observation
Even if the tool returns the correct information, the agent may:
- Ignore key fields
- Misread the result
- Combine the information incorrectly in the end
This shows that the difficulty of ReAct is not only “whether there is a tool,” but also “whether the tool output can be understood.”
How can we make ReAct more stable in practice?
Make the action schema clear enough
The clearer the tool description is, the less likely the agent is to call tools incorrectly.
Limit the maximum number of steps
One of the simplest ways to avoid useless loops is to:
- Set
max_stepsexplicitly
Structure the observation
If the tool returns a messy block of natural language, the agent is more likely to misread it.
A more stable approach is usually to:
- Return structured fields
For example:
{"refund_days": "3-7", "channel": "original_payment"}
Common misconceptions
Misconception 1: ReAct just means “can call tools”
That is not accurate enough. The key idea of ReAct is:
- Reasoning and action alternate and progress together
Misconception 2: As long as there is a trace, it must be reliable
A trace is traceable, but it does not automatically guarantee correctness.
Misconception 3: All Agents should use ReAct
Not necessarily. If the process is highly fixed, an explicit workflow may be simpler and more stable.
Summary
The most important thing in this lesson is not to treat ReAct as a buzzword,
but to understand why it matters:
When a task requires thinking while also obtaining information from the external world, ReAct can organize “reasoning” and “acting” into a loop that gathers evidence step by step and gradually approaches the answer.
Once this understanding is clear, you will find it much easier to follow more complex Agent traces, tool strategies, and multi-step execution frameworks later on.
Exercises
- Add another tool to the example, such as
check_order_status, so the agent has one more step of judgment. - Why is ReAct more suitable for tasks where the “next action depends on the previous observation”?
- Why is ReAct more likely to make mistakes if the tool output is messy?
- Think of a task that is better suited to a fixed workflow and not very suitable for ReAct.