9.2.7 Reasoning Evaluation and Optimization
One of the most common mistakes in reasoning systems is:
- The process looks beautiful
- But the final answer is wrong
Or the other way around:
- The final answer is sometimes correct
- But the process is long, expensive, and completely unreproducible
So this section is here to answer:
How should we evaluate a reasoning system so we can tell whether it truly has ability, or is just “getting it right by chance sometimes”?
Learning Objectives
- Understand why reasoning systems cannot be judged only by final answer accuracy
- Understand why process quality, tool efficiency, and cost also need evaluation
- Learn common reasoning metrics through a runnable example
- Learn how to optimize in a targeted way based on evaluation results
Why is reasoning evaluation more complex than ordinary QA?
Because a reasoning system does not just output a single text
A reasoning Agent often also produces:
- multi-step trace
- tool call records
- intermediate states
- final answer
So this is not a single-point output problem, but a process-oriented system problem.
Looking only at final accuracy misses a lot of information
For example, two systems are both 80% correct:
- System A averages 3 steps and almost never uses tools unnecessarily
- System B averages 9 steps, often repeats searches, and has double the cost
If you only look at accuracy, you may think they are about the same; but in engineering terms, they are at completely different levels.
An analogy: not only whether you reached the destination, but also how you got there
If two cars both reach the destination:
- one drives there smoothly
- the other takes a winding route, brakes hard, and nearly causes an accident
You would not say they performed the same. The same applies to reasoning systems.
The four most common types of metrics for reasoning systems
Final outcome metrics
The most common ones are:
- answer accuracy
- exact match
- pass rate
These answer:
- Is the final conclusion correct?
Process quality metrics
For example:
- Were any critical steps missed?
- Are there contradictions?
- Is there any useless looping?
These answer:
- Is the process reliable?
Tool usage metrics
For example:
- tool success rate
- repeated call rate
- unnecessary call rate
These answer:
- Are tools being used properly?
Cost and efficiency metrics
For example:
- average number of steps
- average latency
- average token cost
These answer:
- Is the system worth deploying?
First, run a truly useful evaluation script
The code below compares the trace quality of two agents. It counts:
- final answer accuracy
- average number of steps
- tool success rate
- repeated tool call rate
agent_a = [
{
"id": "case_1",
"expected": "59",
"final_answer": "59",
"trace": [
{"tool": "calculator", "ok": True},
],
},
{
"id": "case_2",
"expected": "3-7 working days",
"final_answer": "3-7 working days",
"trace": [
{"tool": "search_policy", "ok": True},
],
},
]
agent_b = [
{
"id": "case_1",
"expected": "59",
"final_answer": "59",
"trace": [
{"tool": "search_policy", "ok": True},
{"tool": "calculator", "ok": True},
{"tool": "calculator", "ok": True},
],
},
{
"id": "case_2",
"expected": "3-7 working days",
"final_answer": "5-10 working days",
"trace": [
{"tool": "search_policy", "ok": False},
{"tool": "search_policy", "ok": True},
],
},
]
def evaluate_agent(cases):
accuracy = sum(case["final_answer"] == case["expected"] for case in cases) / len(cases)
avg_steps = sum(len(case["trace"]) for case in cases) / len(cases)
tool_calls = [item for case in cases for item in case["trace"]]
tool_success = sum(item["ok"] for item in tool_calls) / len(tool_calls)
repeated_tool_calls = 0
for case in cases:
tools = [item["tool"] for item in case["trace"]]
repeated_tool_calls += len(tools) - len(set(tools))
repeated_rate = repeated_tool_calls / len(cases)
return {
"accuracy": round(accuracy, 3),
"avg_steps": round(avg_steps, 3),
"tool_success": round(tool_success, 3),
"repeated_tool_calls_per_case": round(repeated_rate, 3),
}
print("agent_a:", evaluate_agent(agent_a))
print("agent_b:", evaluate_agent(agent_b))
Expected output:
agent_a: {'accuracy': 1.0, 'avg_steps': 1.0, 'tool_success': 1.0, 'repeated_tool_calls_per_case': 0.0}
agent_b: {'accuracy': 0.5, 'avg_steps': 2.5, 'tool_success': 0.8, 'repeated_tool_calls_per_case': 1.0}
What is the most important takeaway from this code?
The most important thing is not a formula, but the way of thinking it shows:
For the same system, you should at least look at answer quality, process length, and tool performance at the same time.
Only by looking at all three together can you know whether the system is truly stable or just occasionally getting the right answer.
Why does agent_b not necessarily look much worse at first glance, but is actually worse in engineering terms?
Because it may have:
- more steps
- more repeated tool calls
- a need for recovery after tool failures
Even if it gets some individual cases right in the end, the cost is still higher.
Why is repeated call rate worth tracking separately?
Because many Agent problems are not “completely incapable,” but rather:
- not decisive enough
- repeatedly trying the same tool
- doing many unnecessary actions
This directly slows the system down and increases cost.
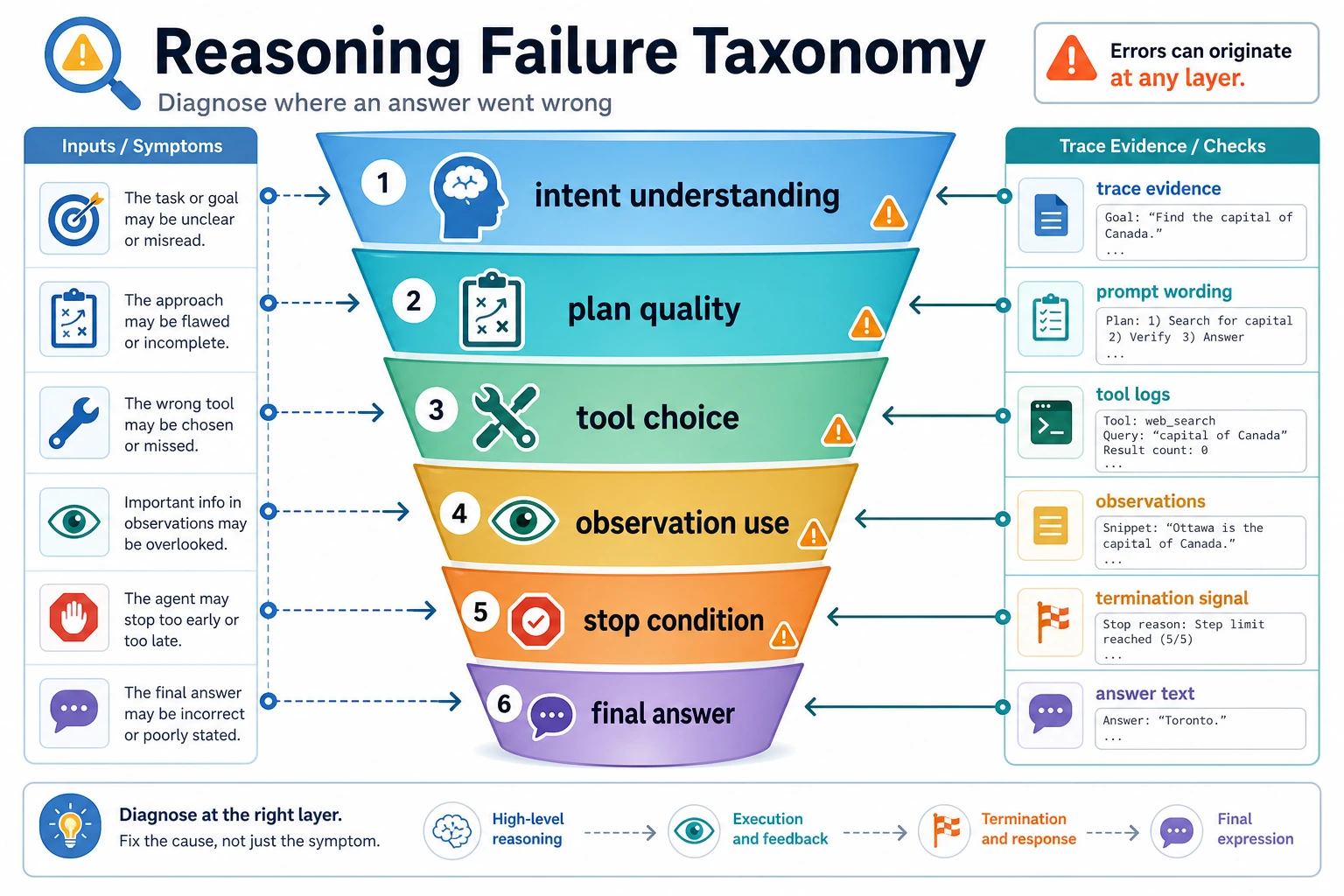
When evaluating, do not only ask “Was the answer wrong?” This diagram breaks failures down into intent, plan, tool, observation, stop condition, and final answer, making it easier to locate which layer went wrong.
Evaluation should not only ask “Was the answer correct?”
For answer-based tasks, look at accuracy
For example:
- math problems
- rule-based Q&A
- clear retrieval questions
For process-based tasks, look at whether the steps are reasonable
For example:
- Were any critical steps missed?
- Was the conclusion drawn too early?
- Was it checked before calculating?
For Agent tasks, look at whether the actions are worthwhile
For example:
- Were there unnecessary tool calls?
- Was there an endless loop after tool failure?
- Did it stop in time when enough information was available?
The timing of stopping is itself part of the capability.
After getting evaluation results, how should you optimize?
If accuracy is low
Prioritize checking:
- whether the problem was misunderstood
- whether the tool choice was wrong
- whether the observations were integrated incorrectly
If accuracy is acceptable but the number of steps is too high
Prioritize checking:
- whether tools are being called repeatedly
- whether it should stop earlier
- whether steps can be merged
If tool success rate is low
Prioritize checking:
- whether the schema is clearly defined
- whether parameter generation is stable
- whether observations are sufficiently structured
If performance differs a lot across task types
You should do bucketed analysis by task type. For example:
- arithmetic tasks
- policy retrieval tasks
- multi-constraint planning tasks
Only then can you make targeted improvements.
How should evaluation samples be designed?
Do not include only easy questions
Otherwise, the system will easily look like “it’s all pretty good.” You should deliberately include:
- questions that are easy to misjudge
- questions that require multi-step tool coordination
- questions that can easily lead to endless loops
It is best to cover failure modes
For example:
- keeps going when it should stop
- calls tools randomly when it should not
- cannot recover after a tool failure
Keep the fixed evaluation set for the long term
That way, every time you change the prompt, strategy, or tools, you can make a meaningful before / after comparison.
Common misconceptions
Misconception 1: If the final answer is correct, the system has no problems
Not necessarily. It may simply be:
- very inefficient in the process
- too expensive
- unstable
Misconception 2: More metrics are always better
Metrics are not a collection hobby. What matters is:
- can the metric explain the problem?
- can the metric guide optimization?
Misconception 3: You can iterate by instinct even without a fixed benchmark
If you rely only on subjective feeling, it is very easy to make the system more and more uncontrollable.
Summary
The most important thing in this section is not memorizing a few metric names, but building an evaluation loop:
A reasoning system should evaluate final answers, process quality, tool usage, and cost efficiency at the same time, and then make targeted improvements based on the specific weaknesses.
When you truly iterate using this loop, the Agent system can grow from a demo that “sometimes works” into a system that is explainable, improvable, and ready for production.
Exercises
- Add one more case to
agent_bin the example and see how the metrics change. - Why is “final answer accuracy” not enough to fully evaluate a reasoning Agent?
- Think about this: if your system often calls the same tool repeatedly, which layer would you inspect first?
- Design at least 3 core metrics for one of your Agent tasks, and explain why they are valuable.