A.9 学習リソース早見表
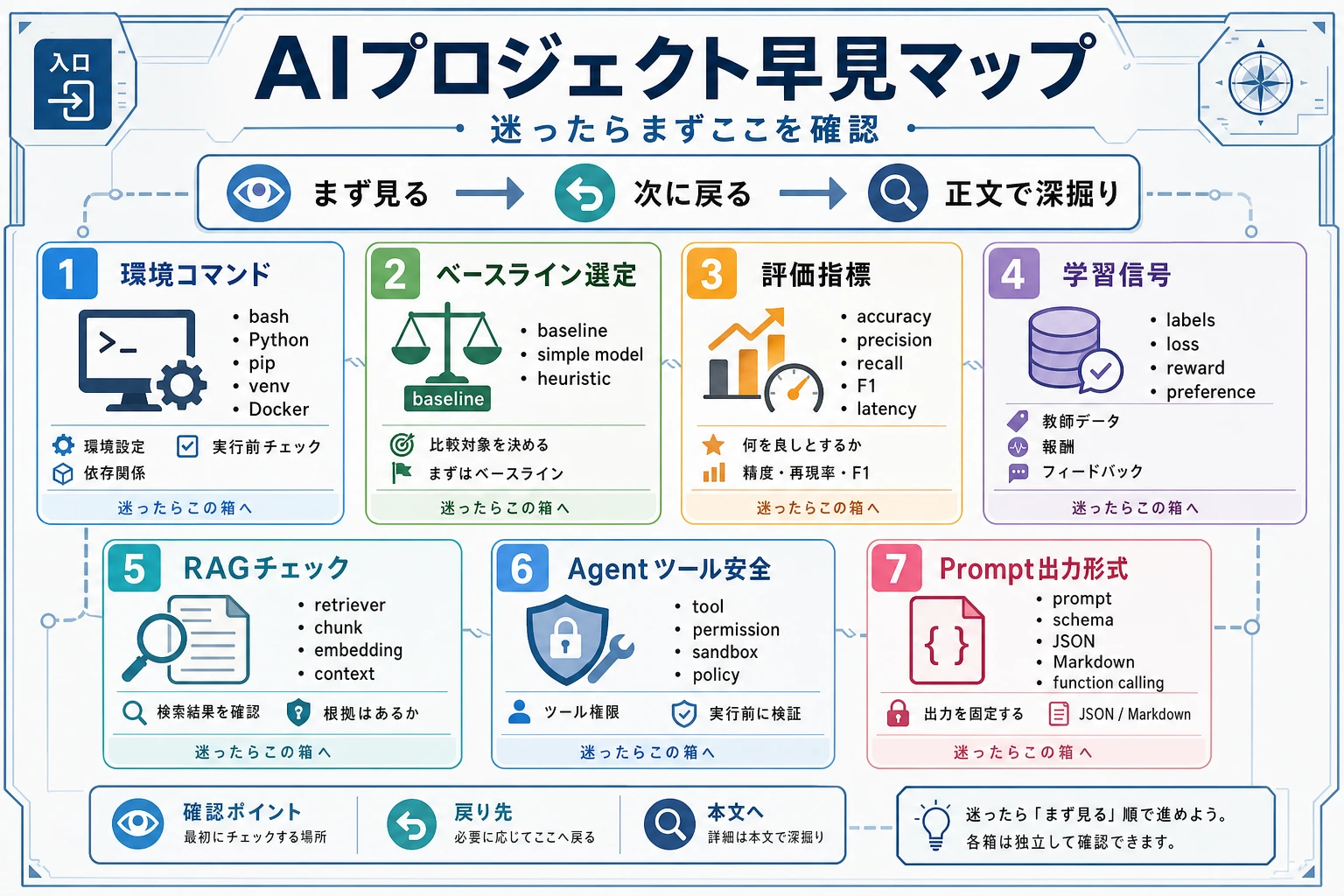
プロジェクト中に調べるページです。上から順に読む必要はありません。
python --versionwhich pythonpip --versionpip listpwdlsドキュメントサイト:
npm installnpm run startnpm run buildNVIDIA GPU:
nvidia-smiまずベースライン
Section titled “まずベースライン”| タスク | 最初に試すもの |
|---|---|
| 表形式の分類/回帰 | 線形モデルまたは木モデル |
| テキスト分類 | TF-IDF + LogisticRegression |
| 画像分類 | 転移学習 |
| 固有表現抽出 | ルール/辞書 baseline、その後系列モデル |
| 文書 Q&A | キーワード/BM25 検索、その後 RAG |
| Agent ツール利用 | 単一 Agent + 安全なツール 1 つ |
| タスク | 最初に見る指標 |
|---|---|
| クラスが均衡した分類 | Accuracy、F1 |
| 不均衡分類 | Precision、Recall、F1、混同行列 |
| 回帰 | MAE、RMSE、残差レビュー |
| 検索 / RAG | Hit@K、MRR、引用正確性、人手レビュー |
| Agent | 成功率、ツールエラー、コスト、trace レビュー |
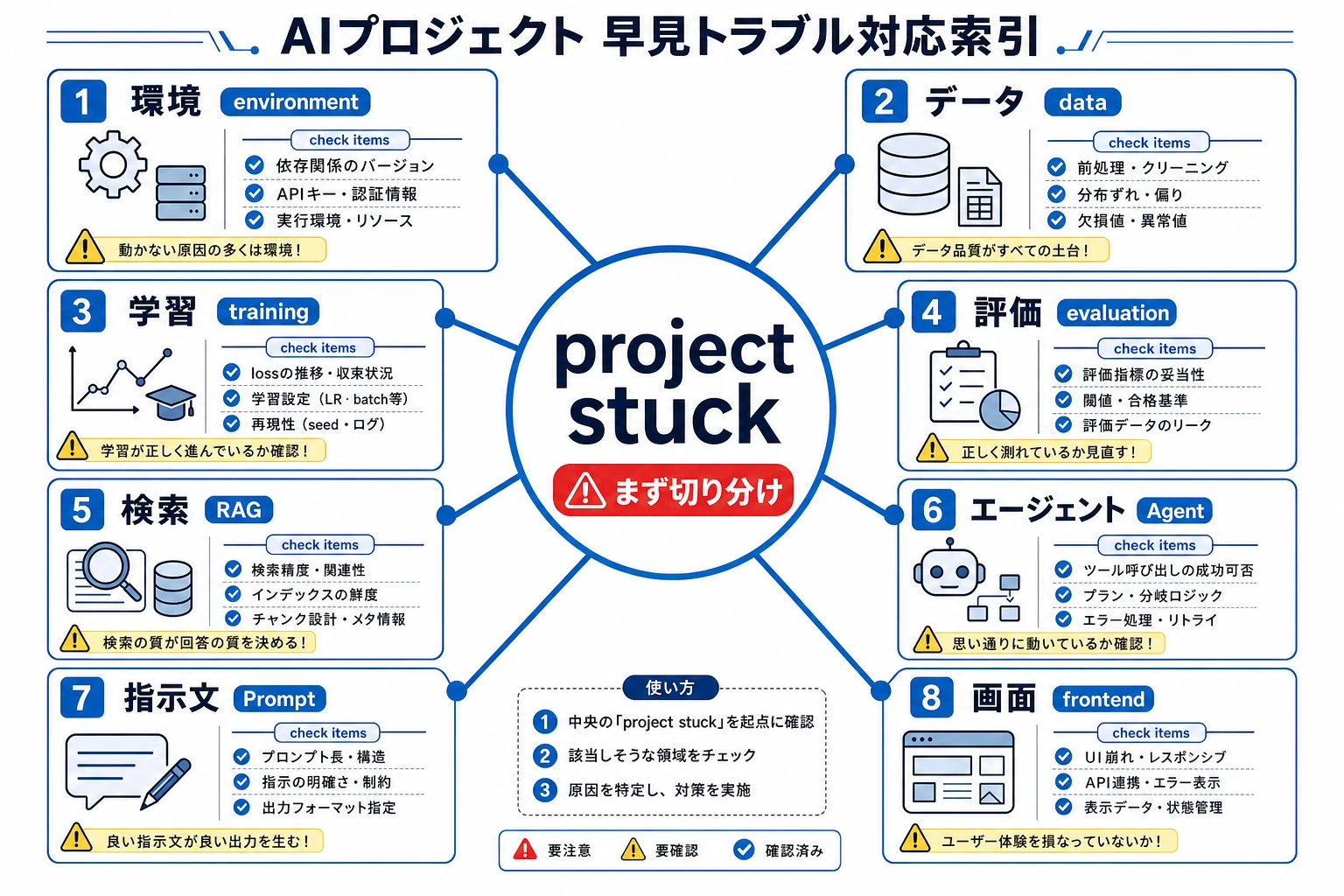
学習中の警告サイン
Section titled “学習中の警告サイン”| サイン | 先に確認 |
|---|---|
| loss が下がらない | ラベル、loss 関数、学習率、入力形式 |
| train は良いが validation が悪い | 過学習、データ漏洩、分布ずれ |
| accuracy が変わらない | 特徴が弱い、ラベルが誤り、モデルが学習していない |
| GPU OOM | batch size、入力長、モデルサイズ |
| 結果が不安定 | random seed、データ不足、分割の不一致 |
RAG チェックリスト
Section titled “RAG チェックリスト”- 文書は正しく分割されているか。
- 検索は正しい chunk を返すか。
- 回答に出典が含まれるか。
- 回答は本当に検索内容を使っているか。
- 権限フィルタと「答えられない」動作があるか。
Agent チェックリスト
Section titled “Agent チェックリスト”- 単発 Q&A から始める。
- ツールを 1 つ追加する。
- 厳密なパラメータ schema を追加する。
- ログと trace 再生を追加する。
- 権限境界と停止条件を追加する。
Prompt テンプレート
Section titled “Prompt テンプレート”あなたは ____ です。あなたのタスクは ____ です。入力:出力形式:制約:情報が不足している場合は明確にそう言ってください。最小訓練ループ
Section titled “最小訓練ループ”data = [(1.0, 2.0), (2.0, 4.0), (3.0, 6.0)]w = 0.0lr = 0.01
for epoch in range(3): total_loss = 0.0 for x, y in data: pred = w * x error = pred - y total_loss += error * error grad = 2 * error * x w -= lr * grad print(f"epoch={epoch} w={w:.3f} loss={total_loss:.3f}")期待される出力:
epoch=0 w=0.521 loss=48.630epoch=1 w=0.907 loss=26.580epoch=2 w=1.192 loss=14.528データ -> 予測 -> 損失 -> 勾配 -> パラメータ更新、の順に読みます。
このページを終えたら、この証拠カードを残します。
- 学習ギャップ
- 強化すべき概念、コードスキル、プロジェクトスキル、論文、またはデプロイスキル
- 資源選択
- 1つの主要なリソースと、それが現在のボトルネックに合う理由
- 時間枠
- プロジェクトに戻る前にどれだけ使うか
- リスク確認
- 証拠を作らずにリソースを集めること
- 期待される成果
- 読書後に作成する 1つのアーティファクトがある短いリソース計画