7.6.1 微調整ロードマップ:データ、LoRA、評価
微調整は、サンプルで訓練してモデルの振る舞いを変える方法です。安定したタスクパターン、繰り返し使う形式、ドメインの文体、行動習慣に向いています。非公開知識の不足を直す最初の手段ではなく、その場合は RAG が合うことが多いです。
まず意思決定ループを見る
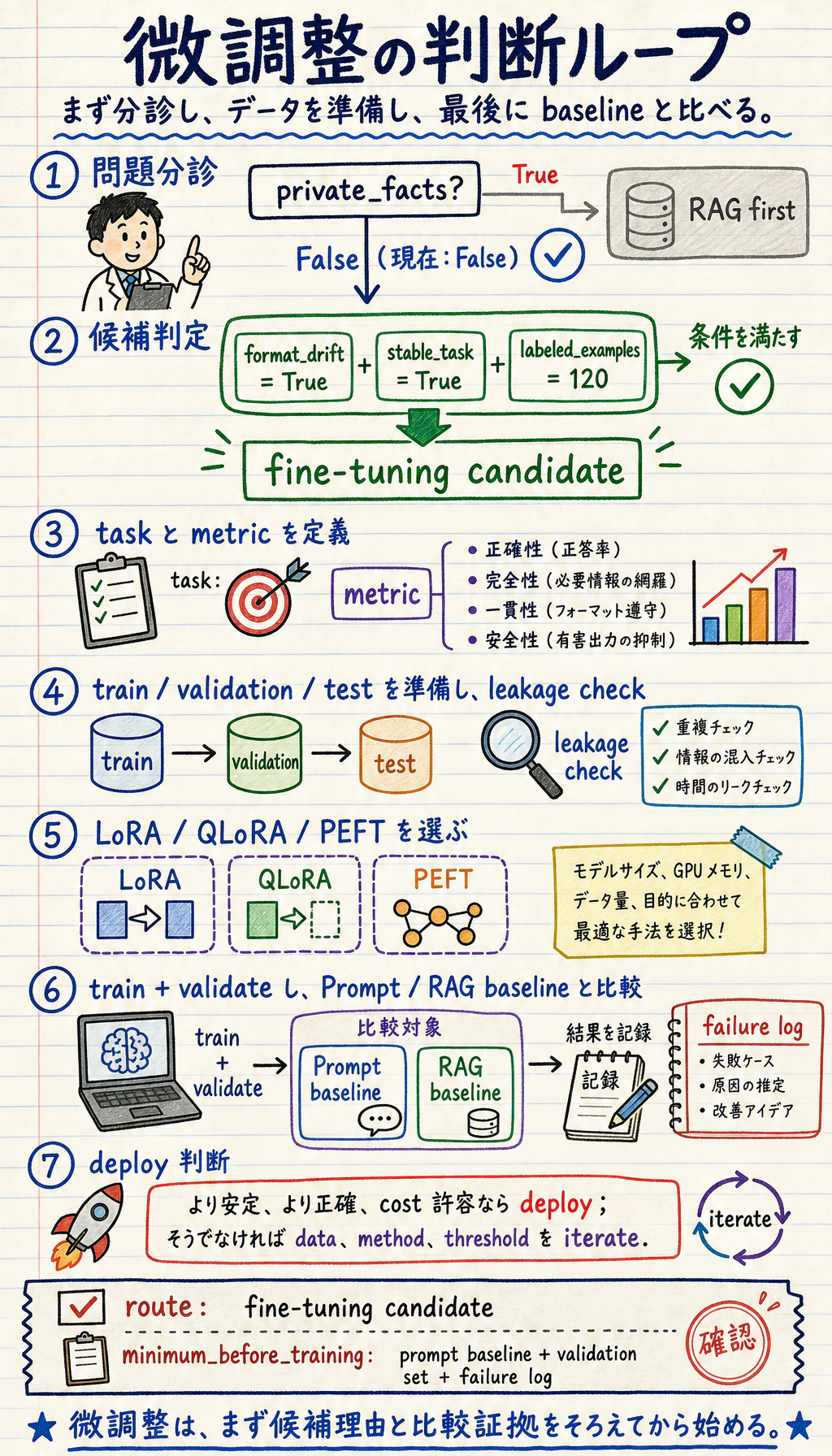
Section titled “まず意思決定ループを見る”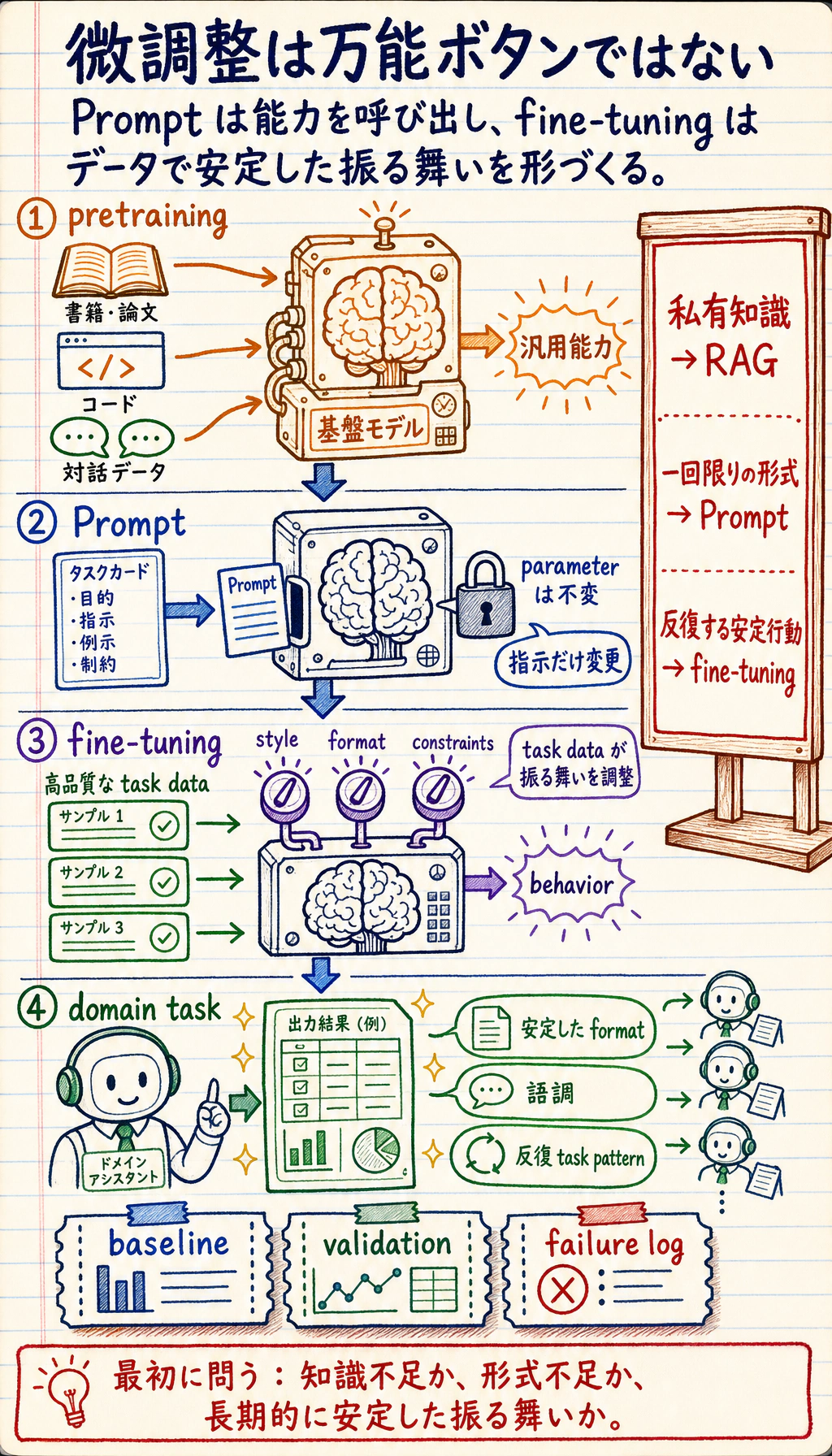
重要語:LoRA は low-rank adapter、QLoRA は量子化された LoRA、PEFT は parameter-efficient fine-tuning です。全重みを更新せず、少数の追加パラメータを訓練することでコストを下げます。
微調整ルートチェックを動かす
Section titled “微調整ルートチェックを動かす”訓練を始める前に、このチェックを動かします。Prompt ベースライン、検証セット、失敗ログがない微調整は、良くなったか判断しづらくなります。
case = { "private_facts": False, "format_drift": True, "stable_task": True, "labeled_examples": 120,}
if case["private_facts"]: route = "RAG first"elif case["format_drift"] and case["stable_task"] and case["labeled_examples"] >= 50: route = "fine-tuning candidate"else: route = "prompt baseline first"
print("route:", route)print("minimum_before_training:", ["prompt baseline", "validation set", "failure log"])期待される出力:
route: fine-tuning candidateminimum_before_training: ['prompt baseline', 'validation set', 'failure log']1 回に 1 つだけ値を変えて再実行します。たとえば private_facts を True にすると、判断はまず RAG に移るはずです。
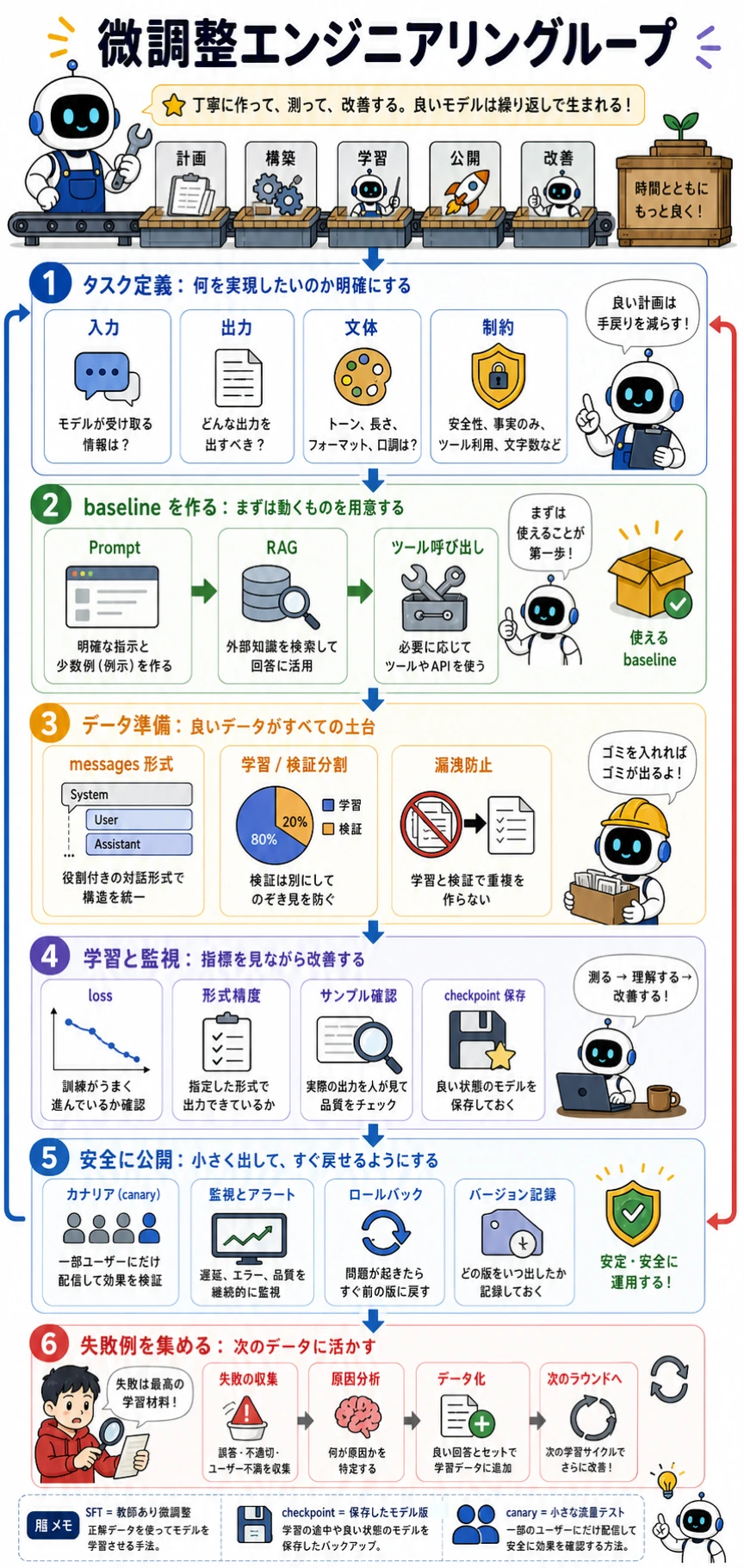
この順番で学ぶ
Section titled “この順番で学ぶ”| 手順 | 読む内容 | 実践アウトプット |
|---|---|---|
| 1 | 微調整概要 | Prompt、RAG、微調整をいつ使うか書き分ける |
| 2 | LoRA / QLoRA | どのパラメータを訓練し、なぜ安くなるか説明する |
| 3 | その他の PEFT | フル微調整だけが選択肢ではないと理解する |
| 4 | 微調整実践 | 訓練/検証サンプルと 1 つの実行コマンドを用意する |
| 5 | データラベリング | 形式、重複、リーク、境界例を点検する |
このページを終えたら、この証拠カードを残します。
- 判断
- なぜ prompt/RAG/ツールだけでは不十分か
- データ形状
- 指示、入力、出力、メタデータ
- 手法
- フル微調整、LoRA、QLoRA、または他の PEFT
- 評価セット
- 学習開始前の固定ケース
- リスク
- 過学習、スタイルのずれ、安全性低下、またはコスト
微調整を試す理由、比較対象のベースライン、訓練に使っていない検証セットを示せれば、この章は合格です。
出口ミニプロジェクトは、小さな instruction tuning 計画です。固定タスクを 1 つ選び、数十から数百件のサンプルを準備し、Prompt ベースラインを定義し、LoRA/QLoRA 実行後に形式安定性または精度を比較します。
確認の考え方と解説
- 合格レベルの答えでは、token、context、attention、prompt、生成挙動が1回の request-response path でどうつながるかを説明します。
- 証拠には、再現できる prompt または structured-output test を1つ残し、出力が通った理由または失敗した理由を書きます。
- prompt 設計、RAG、fine-tuning、alignment を切り分け、観察した問題を直す最も軽い方法を選べれば十分です。