9.1.1 Agent 基礎ロードマップ:目標、状態、行動
Agent はモデル名ではありません。目標に向かって、モデル、ツール、状態、記憶、フィードバックをまとめるシステムパターンです。
まず単一 Agent ループを見る
Section titled “まず単一 Agent ループを見る”
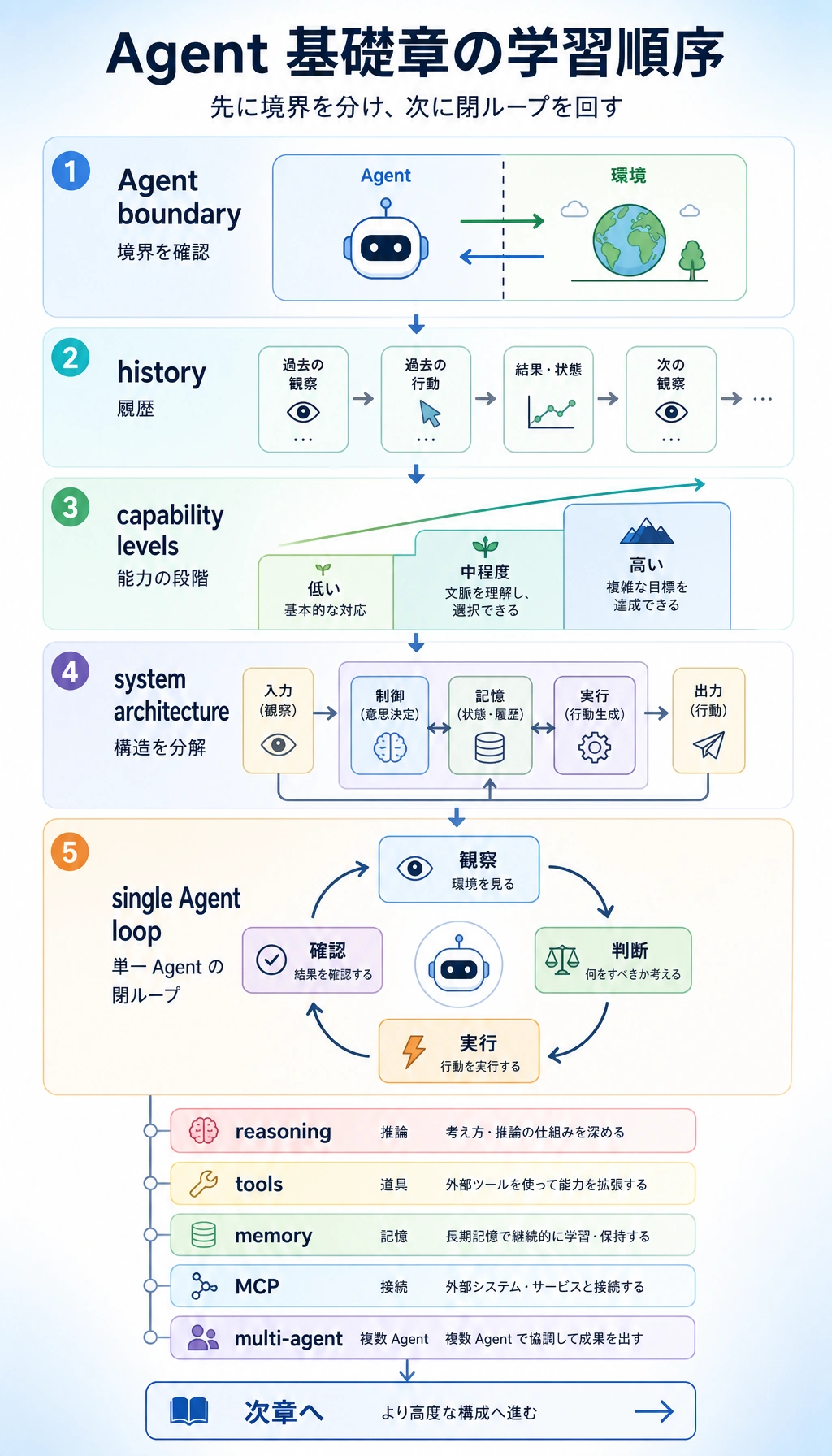
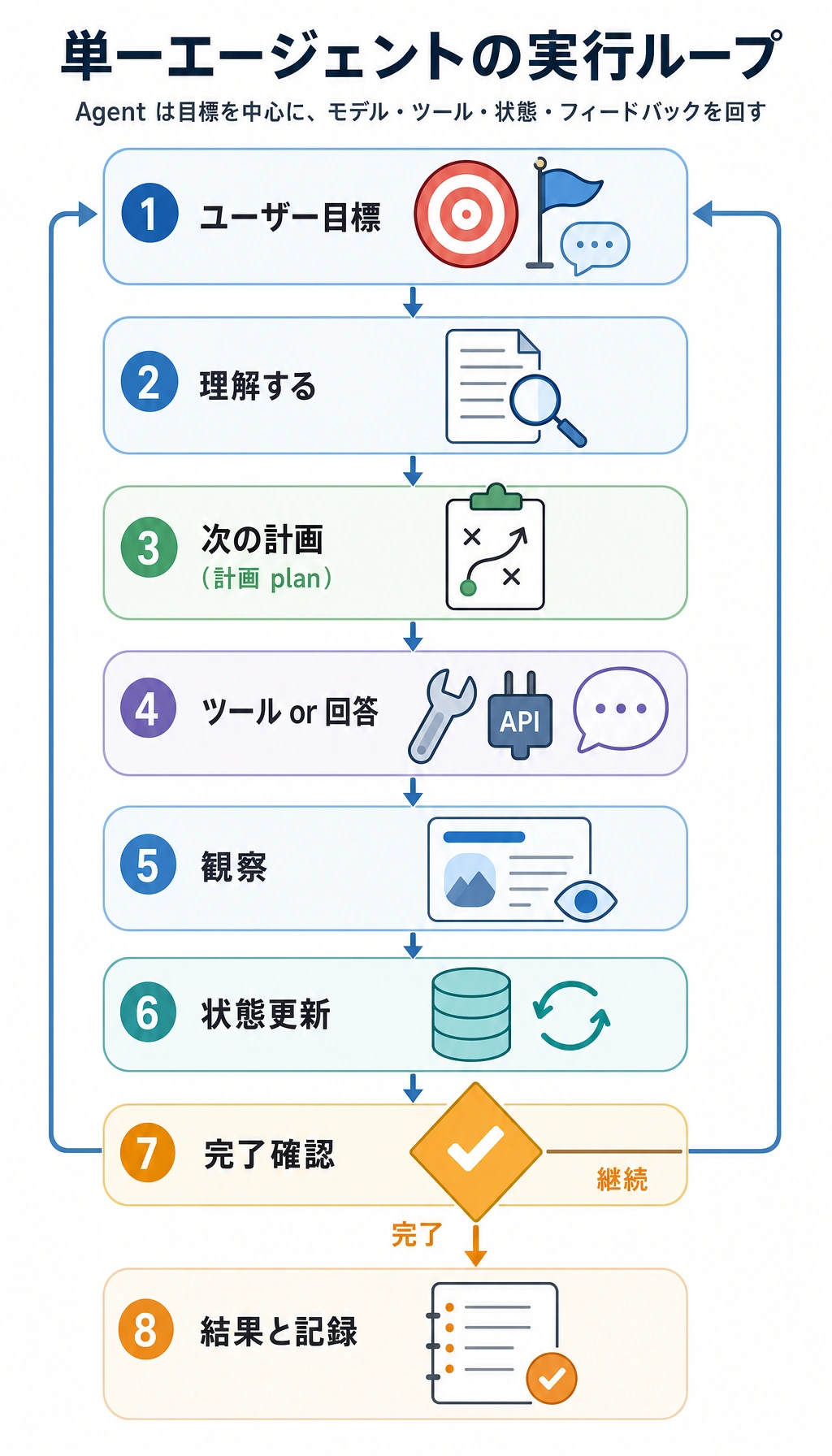
普通のチャットボットは 1 回答えます。ワークフローは固定手順を進みます。Agent は計画、行動、観察、状態更新を行い、目標が終わっていなければ続けます。
小さな Agent 状態ループを動かす
Section titled “小さな Agent 状態ループを動かす”このスクリプトはまだモデルを呼びません。Agent をデバッグできるようにする最小状態を示します。
goal = "summarize RAG citation rules"state = {"steps": [], "done": False}
for action in ["plan", "search_docs", "summarize"]: state["steps"].append(action)
state["done"] = True
print("goal:", goal)print("steps:", " -> ".join(state["steps"]))print("done:", state["done"])期待される出力:
goal: summarize RAG citation rulessteps: plan -> search_docs -> summarizedone: Trueデモが目標、状態、行動、観察、停止条件を示せないなら、まず LLM アプリと呼び、Agent とは呼ばないほうが正確です。
この順番で学ぶ
Section titled “この順番で学ぶ”| 手順 | 読む内容 | 実践アウトプット |
|---|---|---|
| 1 | Agent とは何か | チャットボット、ワークフロー、RAG アプリ、Agent を比較する |
| 2 | 発展史 | なぜ LLM が Agent システムを再び注目させたか理解する |
| 3 | 能力レベル | 回答、検索、ツール利用、計画、記憶、協調を同じ段階表に置く |
| 4 | システムアーキテクチャ | 目標、状態、プランナー、ツール、記憶、観察、実行器を描く |
| 5 | RL から Agent への突破 | 行動、報酬、フィードバック、計画をつなげる |
このページを終えたら、この証拠カードを残します。
- エージェント境界
- これが chatbot や固定ワークフローとどう違うか
- 目標/状態/行動
- 目標、現在の状態、次の行動、観測
- アーキテクチャ要素
- planner、tools、memory、guardrails、evaluator
- 失敗確認
- 自律性が高すぎる、あいまいな目標、状態不足、または trace がない
- 次の行動
- 追跡可能な最小の single-agent ループを構築する
単一 Agent ループを描き、マルチ Agent 協調の前に単一 Agent の安定性が必要な理由を説明できれば、この章は合格です。
出口ミニプロジェクトは研究アシスタント Agent の追跡記録です:1 つの目標、1 つの計画、少なくとも 1 つのツール判断、1 つの観察、1 つの停止条件、1 つの最終回答を残します。
確認の考え方と解説
- 合格レベルの答えでは、agent loop を goal、plan、tool call、observation、memory/state update、stop condition として説明します。
- 証拠には、最終回答だけでなく、別の開発者が確認できる trace を残します。
- tool schema、permission boundary、retry、evaluation case、人間レビューなど、安全性または信頼性の制御を1つ説明できれば十分です。