6.7.2 ハイパーパラメータ調整戦略
- 何でも同時に変えず、安定した順序で調整できる。
- PyTorch で小さな learning-rate sweep を実行できる。
- validation loss、validation accuracy、訓練の安定性を一緒に読める。
- 再利用できる表で実験 evidence を記録できる。
- learning rate、batch size、正則化、early stopping のどれを次に調整すべきか判断できる。
まずルートを見る
Section titled “まずルートを見る”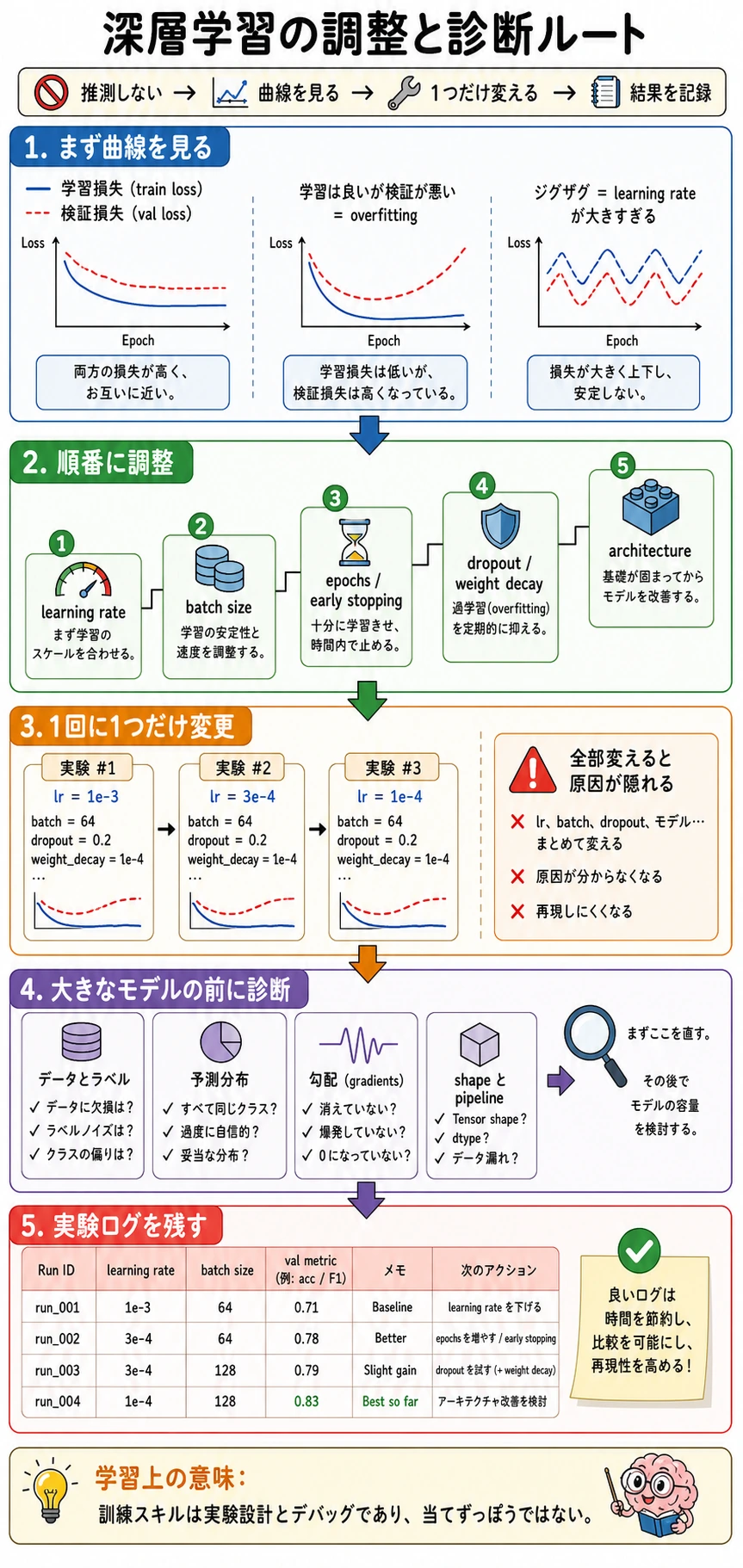
実践的な順序:
訓練を動かすlearning rate を調整するvalidation を見るoverfitting を抑える局所的に細かく詰める
最初からすべての knob を回さないでください。有用な調整実験は、1 つの質問に答えるべきです。
| 質問 | まず試すパラメータ | 見るもの |
|---|---|---|
| モデルはそもそも学習するか | learning rate | train loss の傾向 |
| 訓練が不安定か | learning rate、gradient clipping、batch size | spike や divergence |
| validation が training より悪いか | weight decay、dropout、augmentation、early stopping | generalization gap |
| 訓練が遅すぎるか | batch size、model size、precision | 時間とメモリ |
| deploy には重すぎるか | architecture、pruning、quantization | latency と size |
実験:Learning-Rate Sweep を走らせる
Section titled “実験:Learning-Rate Sweep を走らせる”この toy classification task は小さくてすぐ動きますが、調整の流れを学べます。
lr_sweep.py を作成します。
import torchfrom torch import nn
torch.manual_seed(11)
X = torch.randn(240, 2)y = ((X[:, 0] * 0.8 + X[:, 1] * -0.5) > 0).long()
train_x, val_x = X[:180], X[180:]train_y, val_y = y[:180], y[180:]
def run(lr): torch.manual_seed(123) model = nn.Sequential(nn.Linear(2, 8), nn.ReLU(), nn.Linear(8, 2)) opt = torch.optim.SGD(model.parameters(), lr=lr) loss_fn = nn.CrossEntropyLoss()
for _ in range(40): logits = model(train_x) loss = loss_fn(logits, train_y) opt.zero_grad() loss.backward() opt.step()
with torch.no_grad(): train_loss = loss_fn(model(train_x), train_y).item() val_logits = model(val_x) val_loss = loss_fn(val_logits, val_y).item() val_acc = (val_logits.argmax(dim=1) == val_y).float().mean().item()
return train_loss, val_loss, val_acc
results = []for lr in [1e-3, 1e-2, 1e-1, 1.0, 10.0]: train_loss, val_loss, val_acc = run(lr) results.append((lr, train_loss, val_loss, val_acc))
print("lr_sweep")for lr, train_loss, val_loss, val_acc in results: print( f"lr={lr:g} " f"train_loss={train_loss:.3f} " f"val_loss={val_loss:.3f} " f"val_acc={val_acc:.3f}" )
best = min(results, key=lambda row: row[2])print("best_lr:", best[0])実行します。
python lr_sweep.py期待される出力:
lr_sweeplr=0.001 train_loss=0.763 val_loss=0.733 val_acc=0.450lr=0.01 train_loss=0.675 val_loss=0.663 val_acc=0.533lr=0.1 train_loss=0.340 val_loss=0.373 val_acc=0.967lr=1 train_loss=0.053 val_loss=0.072 val_acc=0.983lr=10 train_loss=0.280 val_loss=0.291 val_acc=0.883best_lr: 1.0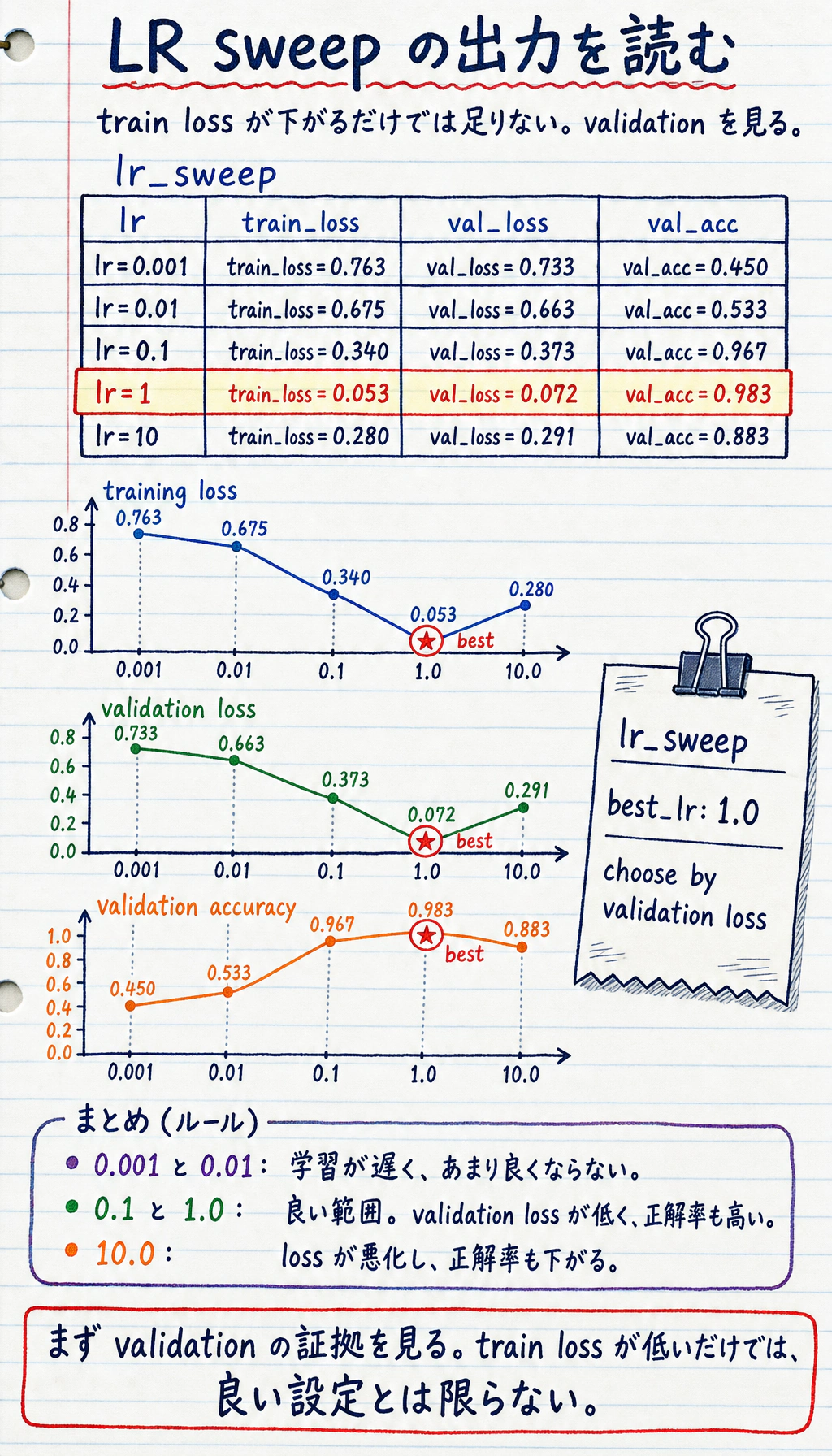
読み方:
0.001と0.01は、この budget では遅すぎます。0.1と1.0はよく学習しています。10.0はまだ訓練できますが悪化しているので、大きければよいわけではありません。- ここでは training loss ではなく validation loss で選びます。
次に何を調整するか
Section titled “次に何を調整するか”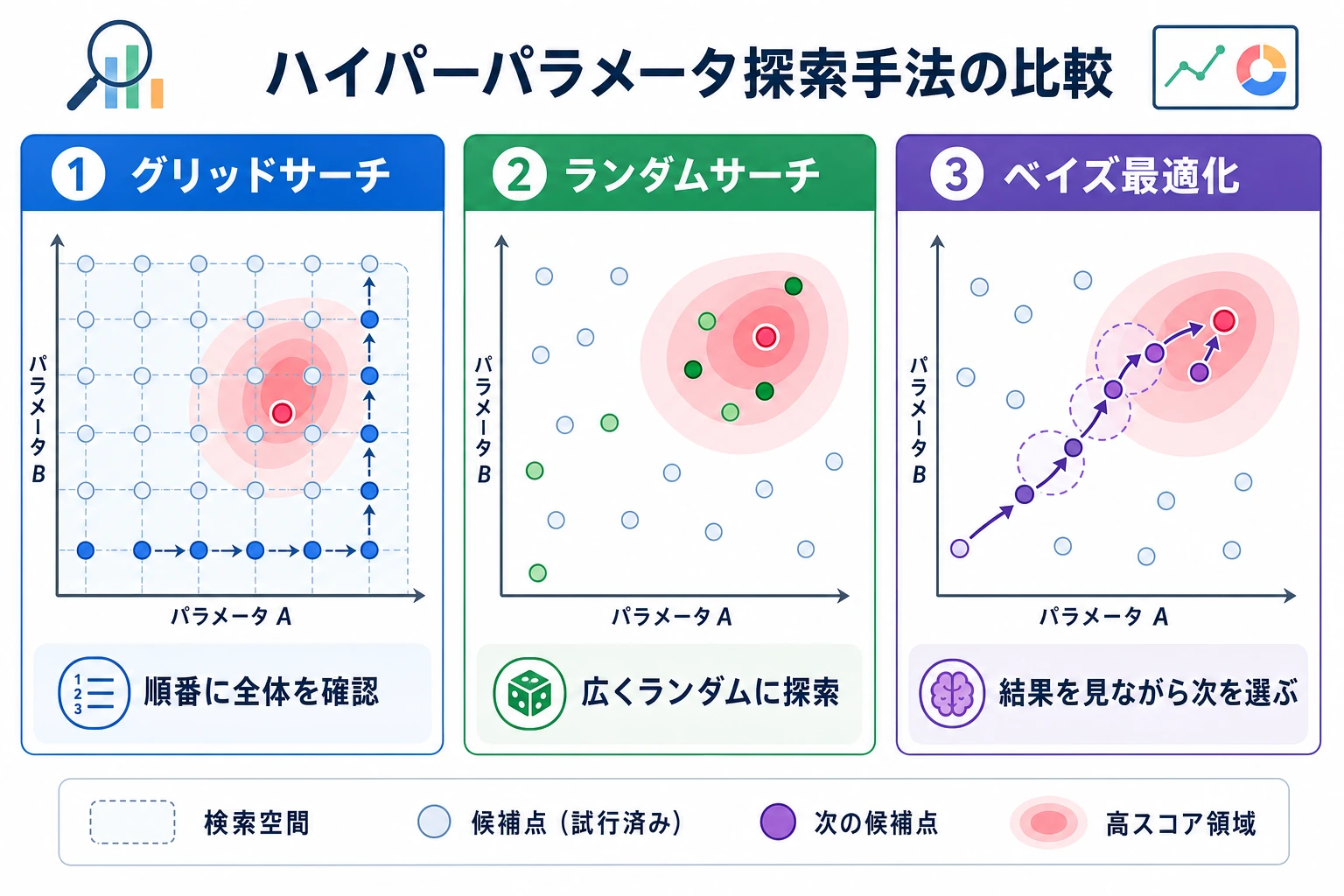
妥当な learning rate を見つけたら、次の順で進めます。
- Batch size:メモリ、速度、gradient noise を調整する。
- Epochs と early stopping:validation が伸びなくなったら止める。
- Weight decay と dropout:overfitting を抑える。
- Architecture size:loop が安定してから容量を変える。
- Optimizer details:必要に応じて betas、scheduler、warmup、momentum を調整する。
ルール:
まず広く探し、あとで近くを細かく詰める最小の実験ログ
Section titled “最小の実験ログ”小さな project でも log を残します。
| グループ | 記録する項目 |
|---|---|
| 識別情報 | experiment_id、code_version、data_version、seed |
| ハイパーパラメータ | lr、batch_size、optimizer、weight_decay、dropout、epochs |
| 結果 | best_val_metric、train_time、decision |
decision の例:
quick sweep では lr=1.0 が最も良い validation loss。次は lr=1.0 を固定し、batch_size=32 と 64 を比較する。tuning decision card を 1 つ残します。
- 質問
- どの単一変数がテストされたか?
- 固定済み
- データ分割、seed、モデル、optimizer の種類、学習予算
- 変更点
- 学習率の値
- 選択指標
- 検証損失または検証精度
- 最良設定
- 速い探索で lr=1.0
- 次の実験
- 一度に多くの設定を変えず、ローカルな微調整を1つ行う
診断パターン
Section titled “診断パターン”| パターン | ありそうな原因 | 次の実験 |
|---|---|---|
| train loss が動かない | LR が低い、モデルが小さい、label が悪い | LR を上げる、data を確認する、モデルを大きくする |
| train loss が発散する | LR が高い、gradient が不安定 | LR を下げる、clipping を入れる |
| train は良いが validation が悪い | overfitting または leakage | 正則化を足し、split を確認する |
| validation が良くなった後で悪化する | best epoch の後に overfitting | early stopping |
| seed で結果が大きく変わる | 訓練が不安定、または data が少ない | 3 seed で mean/std を出す |
よくある間違い
Section titled “よくある間違い”| 間違い | 直し方 |
|---|---|
| LR、batch size、optimizer、model を同時に変える | 1 実験で主変数を 1 つに絞る |
| training metric で選ぶ | validation metric で選ぶ |
| runtime を無視する | 時間とメモリも記録する |
| lucky seed を信じる | 重要な run は複数 seed で繰り返す |
| data が汚いまま調整する | label、leakage、preprocessing を先に確認する |
- sweep に
lr=0.3とlr=3.0を追加してください。どちらが良い領域に近いですか。 - training budget を
40step から10step に変えてください。best LR は変わりますか。 - 各 LR を 2 つの seed で実行し、
seed列を追加してください。 - LR sweep の後に行う次の実験を 1 文で書いてください。
- 1 つの実験が 1 つの質問に答える形だと、なぜ調整が簡単になるのか説明してください。
参考実装と解説
- 多くの場合
lr=0.3の方が使える領域に近く、lr=3.0は発散や振動を起こしやすいです。最終判断は検証曲線で行います。 - 予算が短いと、大きめの学習率が良く見えることがあります。長い予算では安定性も重要です。
- seed を増やすと平均とばらつきを見られます。1 回だけの良い結果に引っ張られにくくなります。
- 次の実験は具体的に書きます。例:
0.03から0.3の間を細かく調べ、各設定を 2 seed で走らせる。 - 1 回の実験で 1 つの問いに答えると、結果の原因を追いやすく、記録も再現しやすくなります。
- 調整は制御された実験設計であり、勘ではありません。
- Learning rate は多くの場合、最初に試す knob です。
- 判断は validation の evidence で行います。
- Log があれば、実験は再現しやすく解釈しやすくなります。
- まず広く調整し、あとで局所的に詰めます。