8.4.6 Long Context、RAG、Memory の選び方
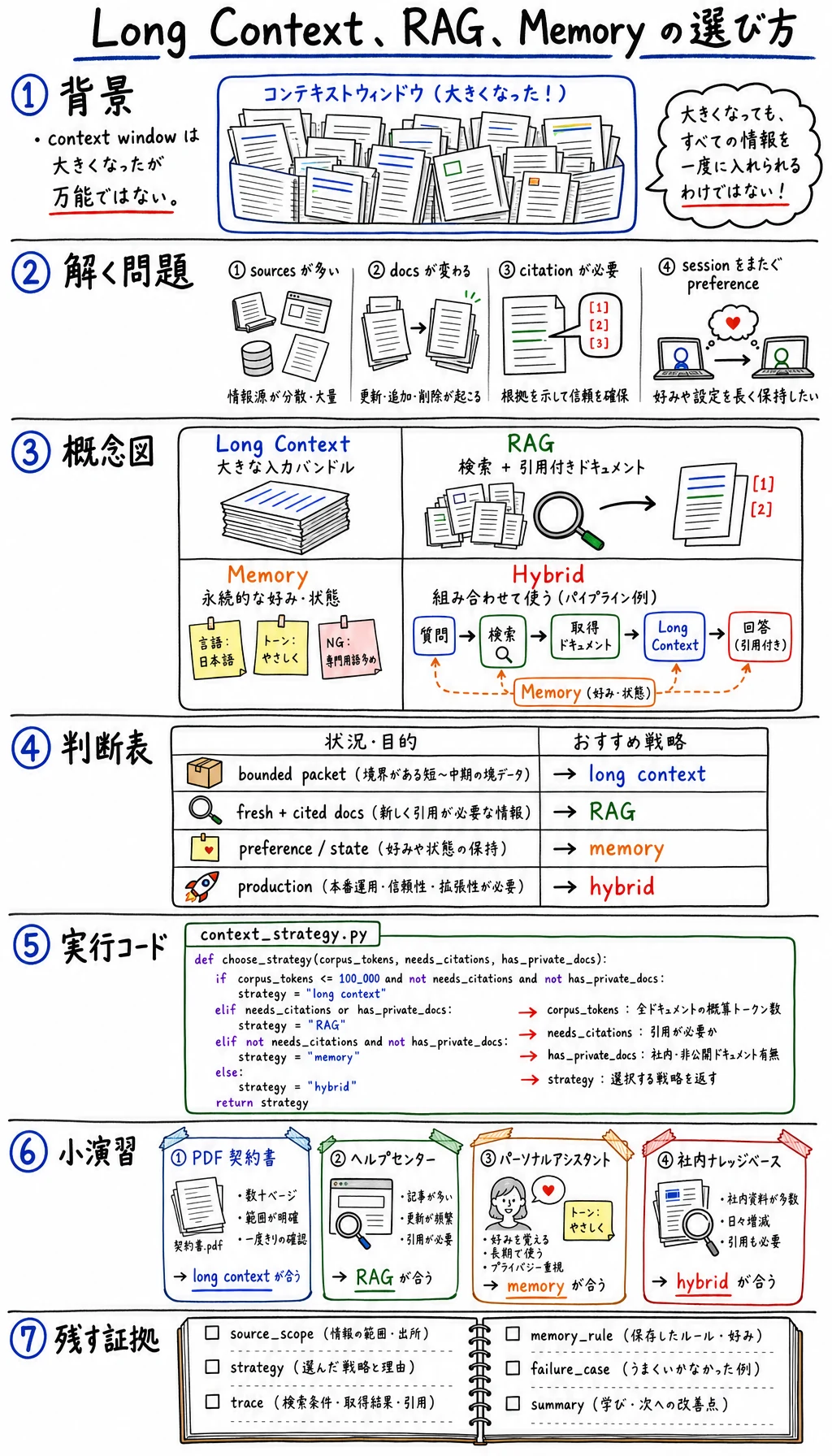
Long-context model、RAG system、Agent memory は、同じ痛みを別々の角度から解きます。つまり、モデルが必要な情報を必要なタイミングで得ることです。よくある失敗は、どれか一つを万能だと思うことです。
このレッスンでは判断ルールを作ります。GPT-4.1 や Claude 1M context のように大きなコンテキストが現実的になると、資料を直接入れられる場面が増えます。それでも検索、引用、権限制御、メモリの整理は不要になりません。
なぜ登場したのか
Section titled “なぜ登場したのか”長文脈モデルが強くなる前は、「モデルにもっと文書を読ませたい」とき RAG が標準解でした。RAG は有効ですが、chunking、embedding、indexing、ranking、citation、freshness の問題も増えます。
Long context はトレードオフを変えます。
- より多くのソースを直接 prompt に入れられる。
- 小さく境界のあるコーパスでは検索基盤を減らせる。
- 場合によっては prompt 全体をレビューしやすい。
ただし新しい問題もあります。
- token が増えるとコストと遅延が上がる。
- 重要な証拠が埋もれる。
- 継続的なユーザー嗜好を毎回 prompt に入れるべきではない。
- private / regulated documents にはアクセス制御が必要。
Memory は第三の軸です。何をセッションをまたいで保存するべきでしょうか。
| 技術 | 保持するもの | 得意なこと | 主なリスク |
|---|---|---|---|
| Long context | 多数のファイルや文章を含む大きな prompt | 一回限りの深い読解、コードレビュー、文書比較、議事録分析 | コスト、遅延、注意の希釈 |
| RAG | 検索された chunk | 新しい知識、引用、大規模ライブラリ、ユーザー別権限 | chunking ミス、検索ミス、古い index |
| Memory | 永続的な事実、嗜好、状態 | ユーザーやプロジェクトの継続性 | 古い記憶、機密、隠れた仮定 |
| Hybrid | Context + retrieval + memory | 本番の assistant や agent | trace がないとデバッグ困難 |
| タスクが必要とするもの | 優先 | 理由 |
|---|---|---|
| 境界が明確で model limit 内に収まる資料 | Long context | 部品が少なく trace しやすい |
| 多数の文書、頻繁な更新、引用 | RAG | 検索、source metadata、freshness が重要 |
| セッションをまたぐ嗜好や状態 | Memory | 毎回貼り直すべきではない |
| private documents のユーザー別権限 | RAG + access filter | 検索時点で認可が必要 |
| 数週間動く複雑な Agent | Hybrid | Memory が状態、RAG が証拠、context が現在タスクを持つ |
実行できる演習: Context Strategy を選ぶ
Section titled “実行できる演習: Context Strategy を選ぶ”context_strategy.py を作り、Python 3.10 以上で実行します。
import jsonfrom pathlib import Path
project = { "corpus_tokens": 180_000, "changes_weekly": True, "needs_citations": True, "has_user_preferences": True, "has_private_docs": True, "model_context_limit": 1_000_000,}
def choose_strategy(info): can_fit = info["corpus_tokens"] < info["model_context_limit"] * 0.6 if info["needs_citations"] or info["changes_weekly"] or info["has_private_docs"]: base = "RAG" elif can_fit: base = "long_context" else: base = "RAG"
memory = "project_memory" if info["has_user_preferences"] else "no_persistent_memory"
if base == "RAG" and can_fit: pattern = "hybrid: retrieve first, then pack the most useful evidence into context" elif base == "long_context": pattern = "long context: pack bounded sources and keep a prompt manifest" else: pattern = "RAG: index corpus, retrieve with metadata, cite sources"
return {"base": base, "memory": memory, "pattern": pattern}
plan = { "strategy": choose_strategy(project), "evidence_to_keep": [ "source manifest", "retrieved chunks or packed files", "citation table", "latency and cost note", "memory write/delete rule", ],}
Path("context_strategy.json").write_text(json.dumps(plan, indent=2), encoding="utf-8")print(json.dumps(plan, indent=2))期待される出力:
{ "strategy": { "base": "RAG", "memory": "project_memory", "pattern": "hybrid: retrieve first, then pack the most useful evidence into context" }, "evidence_to_keep": [ "source manifest", "retrieved chunks or packed files", "citation table", "latency and cost note", "memory write/delete rule" ]}コードを一行ずつ読む
Section titled “コードを一行ずつ読む”corpus_tokens と model_context_limit は資料が入るかを見ます。ただし、入ることと入れるべきことは同じではありません。
needs_citations、changes_weekly、has_private_docs は RAG 方向に判断を押します。source metadata、更新、認可が必要だからです。
has_user_preferences は memory を有効にします。Memory は文書倉庫ではなく、小さな永続状態レイヤーです。
pattern は最終設計を説明します。強い実用システムの多くは hybrid です。最も良い証拠を検索し、それを長文脈で深く推論させます。
project を変更して再実行します。
| シナリオ | 変更 | 期待される方向 |
|---|---|---|
| 1つの PDF 契約レビュー | corpus_tokens=80_000, changes_weekly=False, needs_citations=True | citation table つき long context / hybrid |
| 製品ヘルプセンター | corpus_tokens=8_000_000, changes_weekly=True | RAG |
| 個人執筆アシスタント | has_user_preferences=True, needs_citations=False | Memory + current prompt |
| 社内 knowledge base | has_private_docs=True | access filter つき RAG |
context strategy を選んだら、このパケットを残します。
- Source Scope
- 使ってよい文書や memory
- Strategy
- long_context, RAG, memory, hybrid
- Why Not Other
- 採用しなかった選択肢と理由
- Trace
- packed files または retrieved chunks
- Memory Rule
- memory の作成、更新、削除ルール
- Failure Case
- この戦略が失敗する例
Long context は一部の検索基盤を減らせますが、RAG や memory を置き換えるものではありません。境界のある読解には long context、検索と統制された証拠には RAG、継続状態には memory、本番では hybrid を選びます。
理解チェック
「context が多い」ことと「証拠が良い」ことの違いを説明し、source size、freshness、citation、privacy、latency、persistence から戦略を選べれば合格です。