7.0 学習チェックリスト:大モデル原理、Prompt、微調整
このページは印刷用チェックリストとして使います。詳しい説明が必要なときは、第 7 章入口ページ に戻ってください。
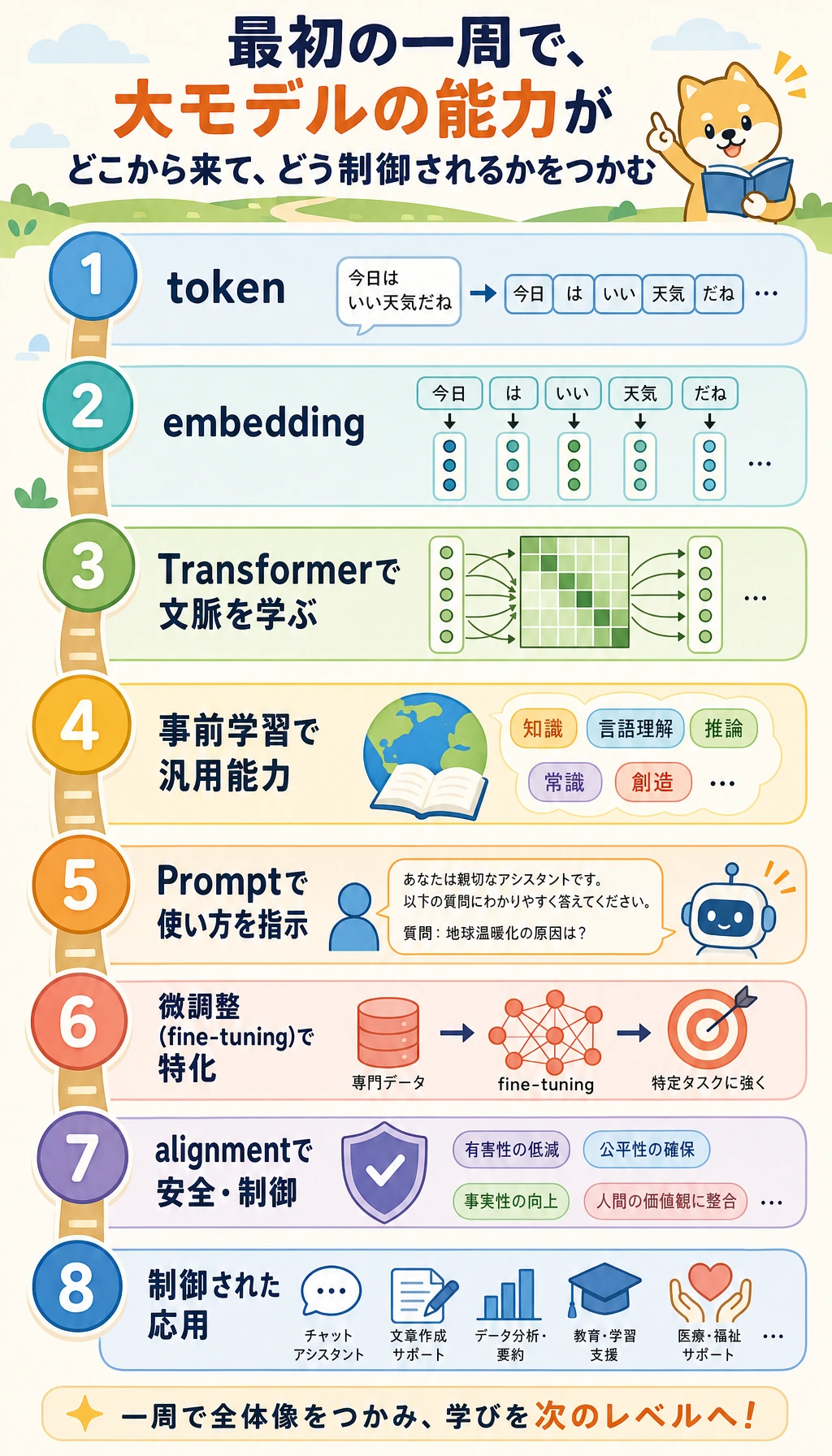
2時間の初回通読
Section titled “2時間の初回通読”| 時間 | やること | ここまで言えたら止める |
|---|---|---|
| 20 分 | 入口ページの「Token から回答まで」の図を見る | 「文章は token、ベクトル、文脈になり、次の token 予測へ進む。」 |
| 25 分 | 7.1 をざっと読み、tokenizer の例を1つ動かす | 「Token 数はコストとコンテキスト制限に影響する。」 |
| 25 分 | 7.2 と LLM 発展史をざっと読む | 「規模、データ、Transformer、整合がモデル能力を変えた。」 |
| 30 分 | 入口ページの Prompt テストスクリプトを動かす | 「固定ケースで Prompt 版を比較できる。」 |
| 20 分 | 手法選択表を読む | 「Prompt、RAG、ツール、検証を確認する前に微調整へ急がない。」 |
必ず残す証拠
Section titled “必ず残す証拠”| 証拠 | 最小版 |
|---|---|
prompts/ | 1つのタスクに対する3つの Prompt 版 |
prompt_eval_cases.csv | 少なくとも5つの固定入力と簡単なスコア列 |
structured_output_schema.json | 必須フィールドと許可する値の型 |
failure_cases.md | 少なくとも3つの失敗出力と推定原因 |
gpu_train_log.txt | 7.4.5 GPU を借りて手作り GPT-2 を学習する の device: cuda 学習ログ |
llm_stage_workshop_output.txt | 7.8.4 実践:第 7 章フルワークショップ の出力 |
README.md | 実行方法、通った点、失敗した点、次に試すこと |
| ゲート | 合格条件 |
|---|---|
| Prompt 比較 | 同じケース、変更する変数は1つ、出力とスコアを保存する。 |
| 構造化出力 | parser が欠落フィールドや型違いを拒否する。 |
| 失敗分析 | 各失敗に、指示、入力、スキーマ、知識不足、安全性のいずれかの推定原因がある。 |
| 手法選択 | 決定表が、Prompt、RAG、微調整、ツール、Agent のどれを先に使うか説明している。 |
| 手作り GPT-2 | CUDA GPU で mini GPT-2 を動かし、embedding、attention、loss、generate の位置を説明できる。 |
期待される結果:第 7 章のフォルダに、Prompt 版、固定評価ケース、parser/schema チェック、失敗メモ、device: cuda の mini GPT-2 学習ログ、ワークショップ出力、手法選択を説明する README がそろっている状態です。
章を出る前の質問
Section titled “章を出る前の質問”- token、embedding、attention、コンテキストウィンドウ、事前学習、Prompt、微調整、整合を、定義の丸写しではなく自分の言葉で説明できますか?
- 毎回1つの Prompt 変数だけを変え、同じ入力ケースで結果を比べられますか?
- JSON らしく見える文章を信じるのではなく、JSON 出力を検証できますか?
- 情報不足のとき、長い Prompt ではなく RAG が必要になる場面を説明できますか?
- 繰り返す振る舞いの適応が、微調整を検討する理由になる場面を説明できますか?
- GPU Notebook を開く、または借りて、
device: cudaで mini GPT-2 を動かし、loss と生成文を保存できますか?
確認の考え方と解説
- これらは1つの流れとして考えます。token と embedding は表現層、attention は文脈の中で注目先を分配する仕組み、context window は一度に見られる範囲、pretraining は基礎モデルの構築、Prompt は今回の指示、微調整はデータで振る舞いを変える方法、整合は出力を有用かつ安全に保つ考え方です。
- 同じケースを保ったまま Prompt 変数を1つだけ変え、出力とスコアの両方を保存すると、印象ではなく再現できる比較になります。
- schema か parser で構造、必須フィールド、型を検証します。解析に失敗したら、正しいとみなさずに拒否します。
- 文書にある新しい事実、私的な事実、引用可能な事実に答えが依存するなら、長い Prompt ではなく RAG を使います。
- 同じ振る舞いが高品質な例で何度も繰り返され、Prompt と検証だけでは足りないときに、微調整を検討します。
答えがすべて「はい」なら、第 8 章へ進みます。第 8 章では、この考え方を実際の LLM アプリと RAG システムにつなげます。
このページを終えたら、この証拠カードを残します。
- プロンプト版数
- 1つのタスクに対して少なくとも3つの版
- 評価ケース
- スコアと失敗メモ付きの固定入力
- スキーマ確認
- 構造化出力が解析され検証される
- 手法選択
- Prompt/RAG/微調整/ツールの判断が記録されている
- 手作り記録
- mini GPT-2 の GPU 学習ログ、環境情報、生成サンプル
- 退出証拠
- ワークショップ出力と README のメモ