9.3.9 実践:マルチツール協調 Agent
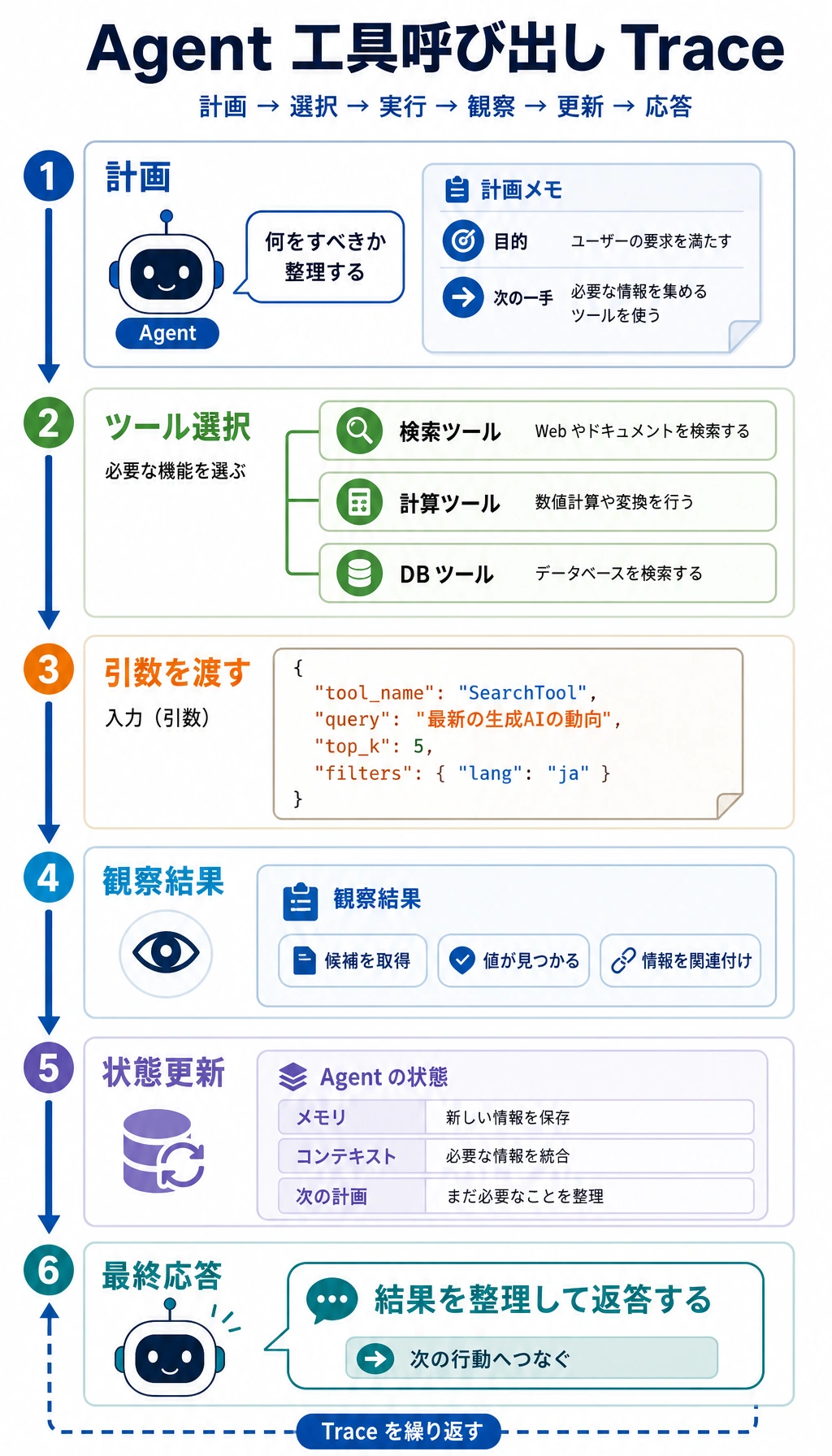
- マルチツール Agent と単一ツール Agent の主な違いを理解する
- 完全な「発見 -> 選択 -> 実行 -> 統合 -> 出力」の流れを理解する
- マルチツール協調で状態管理がなぜ重要かを理解する
- 最小構成のプロジェクトでマルチツール Agent を見せる方法を学ぶ
マルチツール協調はどこが難しいのか?
Section titled “マルチツール協調はどこが難しいのか?”難しさは「ツールが増える」だけではない
Section titled “難しさは「ツールが増える」だけではない”本当に難しいのは、たいてい次の3層です。
- 順番
- 中間状態の受け渡し
- エラー後の処理
たとえば返金シーンでは、次のようになります。
- 注文状態が分からないと、ポリシー判断を誤る可能性がある
- 注文金額が分からないと、返金額を計算できない
- ツールが失敗したら、最終回答も変える必要がある
たとえるなら、ひとり走ではなくリレー
Section titled “たとえるなら、ひとり走ではなくリレー”単一ツールのタスクは、ひとりで動作を完了するようなものです。
マルチツールのタスクは、リレー競走に近いです。
- 前の走者の結果を次の走者に渡す
- どこかでバトンを落とすと、その後に影響が出る
だからマルチツールシステムで一番怖いのは「状態がバラバラになること」
Section titled “だからマルチツールシステムで一番怖いのは「状態がバラバラになること」”毎回のやり取りで、今どこまで分かっているのかがはっきりしていないと、
システムはすぐに次のような状態になります。
- 同じツールを繰り返し呼ぶ
- 重要な情報を見落とす
- 最後の統合を間違える
この実践例は何を解決するのか?
Section titled “この実践例は何を解決するのか?”最小限だけれど完全な返金チケットアシスタントを作ります。
ユーザーの質問は次のようなものです。
- この注文はまだ返金できますか?
- だいたい何円戻りますか?
- いつ着金しますか?
このタスクには、少なくとも次の3種類のツールが必要です。
get_order_statussearch_refund_policycalculator
しかも、これらには明確な順番があります。
- まず注文状態を見る
- 次にポリシーに当てはめる
- それから金額を計算する
まずは完全な流れの例を動かしてみる
Section titled “まずは完全な流れの例を動かしてみる”次のコードでは、以下をまとめて示します。
- ツール登録
- 状態追跡
- 判断戦略
- 複数ラウンドの実行
- 最終回答
import astimport operator
OPS = { ast.Add: operator.add, ast.Sub: operator.sub, ast.Mult: operator.mul, ast.Div: operator.truediv,}
def safe_calculate(expression): def visit(node): if isinstance(node, ast.Expression): return visit(node.body) if isinstance(node, ast.Constant) and isinstance(node.value, (int, float)): return node.value if isinstance(node, ast.BinOp) and type(node.op) in OPS: return OPS[type(node.op)](visit(node.left), visit(node.right)) if isinstance(node, ast.UnaryOp) and isinstance(node.op, ast.USub): return -visit(node.operand) raise ValueError("unsupported_expression")
return visit(ast.parse(expression, mode="eval"))
TOOLS = { "get_order_status": lambda order_id: { "order_id": order_id, "status": "未発送", "amount": 299, "shipping_fee": 15, }, "search_refund_policy": lambda keyword: { "policy_text": "未発送の注文はそのまま返金申請できます。返金は元の支払い方法に戻され、通常 3〜7 営業日で着金します。" }, "calculator": lambda expression: { "result": safe_calculate(expression) },}
def decide_next_action(state): if "order_info" not in state: return {"tool": "get_order_status", "arguments": {"order_id": state["order_id"]}}
if "policy" not in state: return {"tool": "search_refund_policy", "arguments": {"keyword": "返金"}}
if "refund_amount" not in state: order = state["order_info"] expression = f"{order['amount']} + {order['shipping_fee']}" return {"tool": "calculator", "arguments": {"expression": expression}}
return None
def apply_observation(state, tool_name, observation): if tool_name == "get_order_status": state["order_info"] = observation elif tool_name == "search_refund_policy": state["policy"] = observation["policy_text"] elif tool_name == "calculator": state["refund_amount"] = observation["result"]
def build_final_answer(state): order = state["order_info"] if order["status"] != "未発送": return "この注文は現在、直接返金の条件を満たしていません。詳細対応のため、有人サポートにご連絡ください。"
return ( f"注文 {state['order_id']} の現在の状態は{order['status']}です。" f"{state['policy']} " f"予想返金額は {state['refund_amount']} 円です。" )
def run_agent(order_id, max_steps=5): state = {"order_id": order_id, "trace": []}
for _ in range(max_steps): decision = decide_next_action(state) if decision is None: return state["trace"], build_final_answer(state)
tool_name = decision["tool"] observation = TOOLS[tool_name](**decision["arguments"])
state["trace"].append( { "tool": tool_name, "arguments": decision["arguments"], "observation": observation, } )
apply_observation(state, tool_name, observation)
return state["trace"], "最大ステップ数に達しました。タスクは完了していません。"
trace, answer = run_agent("ORD-1001")print("trace:")for item in trace: print(item)print("\nanswer:")print(answer)期待される出力:
trace:{'tool': 'get_order_status', 'arguments': {'order_id': 'ORD-1001'}, 'observation': {'order_id': 'ORD-1001', 'status': '未発送', 'amount': 299, 'shipping_fee': 15}}{'tool': 'search_refund_policy', 'arguments': {'keyword': '返金'}, 'observation': {'policy_text': '未発送の注文はそのまま返金申請できます。返金は元の支払い方法に戻され、通常 3〜7 営業日で着金します。'}}{'tool': 'calculator', 'arguments': {'expression': '299 + 15'}, 'observation': {'result': 314}}
answer:注文 ORD-1001 の現在の状態は未発送です。未発送の注文はそのまま返金申請できます。返金は元の支払い方法に戻され、通常 3〜7 営業日で着金します。 予想返金額は 314 円です。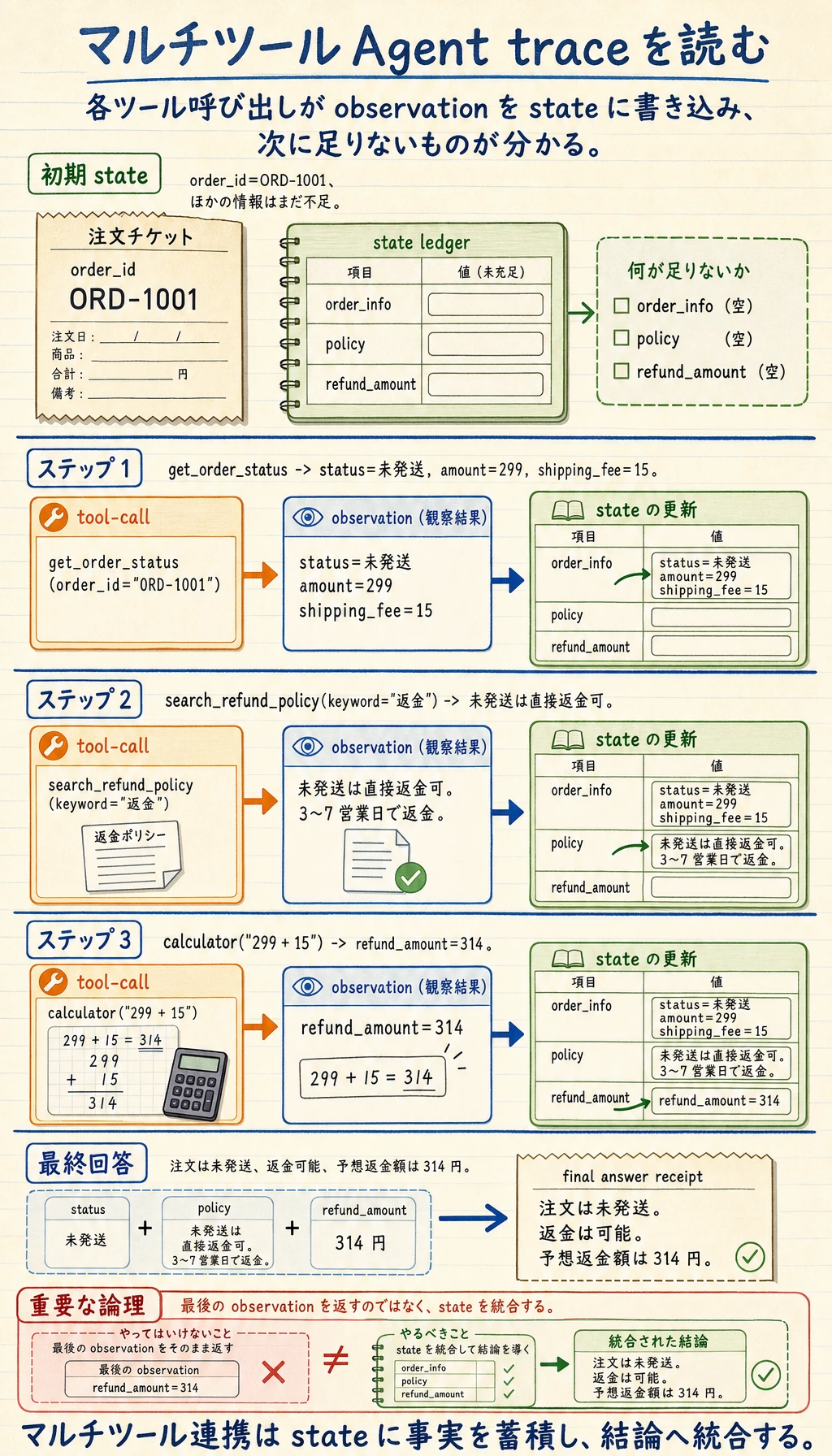
このコードと前の分散サンプルとの最大の違いは何か?
Section titled “このコードと前の分散サンプルとの最大の違いは何か?”これはもう、次のような単独ツールのデモではありません。
- 単一ツールデモ
そうではなく、次の要素をきちんと表しています。
- 判断の順番
- 状態の蓄積
- 複数ツールの連携
- 最終的な統合
つまり、すでに実際のマルチツール Agent の骨組みにかなり近いです。
なぜ state がそんなに重要なのか?
Section titled “なぜ state がそんなに重要なのか?”毎回ツールを呼んだあとに、システムは次を把握していなければならないからです。
- いま何が分かっているか
- 何がまだ足りないか
- 次にどこを補うべきか
統一された状態がなければ、
マルチツール協調はほぼ確実に崩れます。
なぜ最終回答は最後の observation をそのまま返さないのか?
Section titled “なぜ最終回答は最後の observation をそのまま返さないのか?”マルチツールシステムの目的は、たいてい単一のツール出力をそのまま言い直すことではないからです。
本当にやりたいのは、次のことです。
- 複数の observation をまとめて、ユーザーに分かる結論にする
ここにこそ、Agent レイヤーの価値があります。
この種のシステムはどこで失敗しやすいのか?
Section titled “この種のシステムはどこで失敗しやすいのか?”ツールの順番を間違える
Section titled “ツールの順番を間違える”たとえば、注文状態を確認する前に、
返金額を調べたり、いきなり結論を出したりしてしまうことです。
中間状態を保存していない
Section titled “中間状態を保存していない”すると次の問題が起こります。
- 同じツールを何度も調べる
- 結果の上書きに失敗する
- 次のステップで前の結果が使えない
あるツールが失敗したのに、システムが成功したふりを続ける
Section titled “あるツールが失敗したのに、システムが成功したふりを続ける”これはマルチツールシステムで特に危険なバグです。
たとえば次のようなことが起こります。
- ポリシーが見つからない
- でもシステムが適当な返金ルールを作ってしまう
そのため、失敗時の流れも設計の一部として考える必要があります。
このデモをどうやって作品に育てるか?
Section titled “このデモをどうやって作品に育てるか?”第1段階:ツールをもっと本物にする
Section titled “第1段階:ツールをもっと本物にする”たとえば、次のような mock を本物に置き換えます。
- mock の注文状態
- mock のポリシー文書
これを次のように変更します。
- データベース検索
- ドキュメント検索
第2段階:失敗処理を追加する
Section titled “第2段階:失敗処理を追加する”たとえば次のようなケースです。
- ツールのタイムアウト
- 注文が存在しない
- ポリシーがヒットしない
このとき、システムにははっきりした逃げ道が必要です。
第3段階:評価セットを追加する
Section titled “第3段階:評価セットを追加する”次のようなケースを用意できます。
- 返金可能な注文
- 返金不可の注文
- 金額の境界ケース
- ツール失敗のケース
こうすると、システムはただ「動く」だけでなく、
「テストできる」ものになります。
第4段階:トレース を可視化する
Section titled “第4段階:トレース を可視化する”ツール呼び出しの軌跡を見えるようにすると、
このプロジェクトは作品集のデモとしてとても使いやすくなります。
このページを終えたら、この証拠カードを残します。
- ツール契約
- 名前、説明、入力スキーマ、出力スキーマ
- 権限
- ツールが読み取りまたは変更を許可されている範囲
- 呼び出しトレース
- 引数、結果、エラー、再試行、またはフォールバック
- 失敗確認
- 間違ったツール、不適切な引数、危険な操作、または観測不足
- 安全対策
- 検証、確認、サンドボックス化、レート制限、またはロールバック
よくある誤解
Section titled “よくある誤解”誤解1:マルチツールとは、複数の関数を順番につなぐだけ
Section titled “誤解1:マルチツールとは、複数の関数を順番につなぐだけ”それだけでは不十分です。
本当に難しいのは次の点です。
- 順番の判断
- 状態の受け渡し
- エラーからの復旧
誤解2:ツールが増えれば増えるほど Agent は強くなる
Section titled “誤解2:ツールが増えれば増えるほど Agent は強くなる”ツールが増えるほど、次の難しさも増します。
- 選択の難しさ
- 状態管理の複雑さ
誤解3:最後の答えが人間らしければシステムは良い
Section titled “誤解3:最後の答えが人間らしければシステムは良い”マルチツールシステムでは、むしろ次を見たほうが大切です。
- トレース は妥当か
- ツールは本当に必要だったか
- observation は正しく統合されたか
この節で一番大事なのは、「3つの関数を連続で呼べるデモ」を作ることではありません。 マルチツール Agent の核心を理解することです。
マルチツール協調の本質は、共有状態を軸にして複数の外部能力を正しい順番で組み立て、失敗や不確実性があってもシステムを制御可能に保つことです。
この理解がしっかりしていれば、
その先のもっと複雑なものも、たとえば次のようなものでも、問題の本質が見えてきます。
- 企業向けアシスタント
- リサーチ Agent
- コード Agent
- この例に
notify_userツールを追加して、返金条件を満たした場合にだけ通知を送るようにしてください。 - なぜマルチツール Agent の核心は「ツールが多いこと」ではなく、「状態管理が安定していること」なのですか?
search_refund_policyが空の結果を返したら、この流れをどう変えますか?- 考えてみましょう。このデモの中で、作品集に載せるのに最も向いている部分はどこですか?
プロジェクト参考とレビュー観点
notify_userは、ポリシー証拠と eligibility decision がそろい、最終 state が返金条件を満たす場合にだけ実行します。- 核心は state management です。Agent は policy evidence、user input、tool output、decision、そして副作用がすでに起きたかどうかを覚える必要があります。
search_refund_policyが空なら、no-evidence state にし、確認質問をし、承認済み fallback source を試すか、人間へ渡します。推測してはいけません。- ポートフォリオでは、trace、state transition、tool contract、失敗処理、guardrails 追加前後の動作比較を見せるとよいです。