6.1.2 移行:古典機械学習から深層学習へ
- 第5ステーションと第6ステーションが「分断」なのか「発展」なのかを見分ける
- なぜ従来の ML の次にニューラルネットワークを学ぶ必要があるのかを理解する
- ニューラルネットワークと従来モデルが「データ、損失、最適化、評価」で共通する骨組みを理解する
- 後のニューロン、逆伝播、PyTorch の学習ループにつながる心の橋を作る
まず地図を1枚つくろう
Section titled “まず地図を1枚つくろう”多くの初心者は、第5ステーションを終えると次の2つの典型的な疑問を持ちます。
- 線形回帰、ロジスティック回帰、木モデルで十分いろいろできるのに、なぜ深層学習を学ぶ必要があるの?
- 第6ステーションに入ったら、どうして急に層、勾配、逆伝播、PyTorch など新しい用語が増えるの?
より安定した理解のしかたは、まずこの進化の線を見ることです。
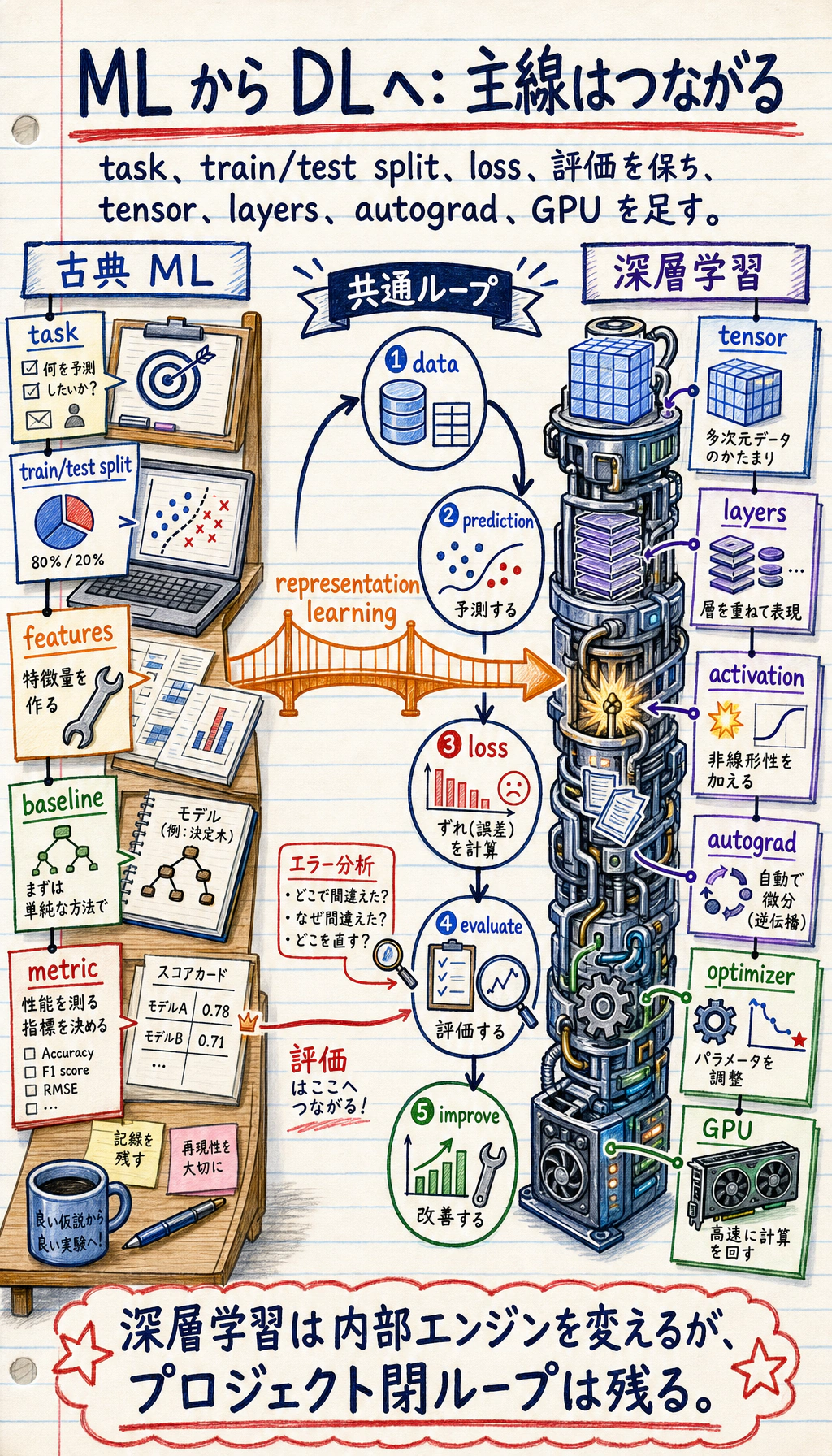
つまり、第6ステーションは第5ステーションをひっくり返すものではなく、第5ステーションで作ったモデリングの考え方をさらに前へ進めるものです。
一、第5ステーションで実際に学んだこと
Section titled “一、第5ステーションで実際に学んだこと”第5ステーションで本当に身につけたのは、単なるモデル名ではなく、次のモデリングの主線です。
- まずタスクの種類を判断する
- まず baseline を作る
- 次に指標を選ぶ
- それから改善する
- 最後に誤り分析と振り返りをする
これらは第6ステーションに入っても消えません。
第6ステーションで本当に新しくなるのは、「評価がなくなる」ことではない
Section titled “第6ステーションで本当に新しくなるのは、「評価がなくなる」ことではない”深層学習に入ると、別のロジックになると思ってしまう人が多いです。 でも、そうではありません。第6ステーションでも次のことは続きます。
- 学習用データと検証用データを分ける
- loss と指標を見る
- 過学習を防ぐ
- 誤り分析を行う
本当に新しくなるのは、モデルの表現力と学習方法です。
二、なぜ従来の ML の次にニューラルネットワークを学ぶのか
Section titled “二、なぜ従来の ML の次にニューラルネットワークを学ぶのか”古典的な機械学習はとても強力ですが、自然な限界もあります。
従来の ML は「手作業の表現」に強く依存する
Section titled “従来の ML は「手作業の表現」に強く依存する”第5ステーションでは、次のようなことを何度もやりました。
- 特徴量を手で作る
- エンコード、スケーリング、選択を行う
- 問題をモデルが学びやすい形に整える
これはとても重要ですが、同時に1つの制約も生みます。
- モデルの上限が、特徴設計の能力に引っ張られやすい
深層学習は「表現を自動で学ぶ」ことを重視する
Section titled “深層学習は「表現を自動で学ぶ」ことを重視する”深層学習の最も強い点は、素朴にいうと次のように理解できます。
「どう予測するか」だけでなく、「入力をどう表現するか」も学ぶ。
たとえば:
- 画像では、CNN がエッジ、テクスチャ、局所パターンを自分で学ぶ
- テキストでは、ニューラルネットワークが単語ベクトルや文脈表現を自分で学ぶ
- シーケンスでは、モデルが時間依存関係や注意の関係を自分で学ぶ
これが、第6ステーションで本当に補われる能力です。
| 問題 | 第5ステーションでよくある方法 | 第6ステーションでよくある方法 |
|---|---|---|
| 画像分類 | まず特徴を手作業で取り出してから分類器に入れる | CNN に特徴をそのまま学ばせる |
| テキスト分類 | TF-IDF / 手作業の統計特徴量 | ネットワークに embedding と文脈を学ばせる |
| 複雑な非線形関係 | 木モデルやアンサンブルを試す | 多層ネットワークで複雑な関数を直接表現する |
これは第6ステーションが必ずしも第5ステーションを「置き換える」という意味ではありません。むしろ次のように考えるのが正しいです。
- データがシンプルで、サンプルが少なく、表形式タスクに強いなら、第5ステーションの方法は今でもとても価値がある
- データが複雑で、非構造化で、特徴量を手で作りにくいなら、第6ステーションの方法の強みがどんどん大きくなる
三、第5ステーションと第6ステーションの共通骨格は実は変わらない
Section titled “三、第5ステーションと第6ステーションの共通骨格は実は変わらない”第6ステーションでは新しい用語がたくさん出てきますが、1回の学習の骨格は、実は第5ステーションと同じ線上にあります。
flowchart LR A["入力データ X"] --> B["モデルが予測 y_hat を出す"] B --> C["損失 loss を計算する"] C --> D["loss に基づいてパラメータを更新する"] D --> E["検証用データで結果を見る"]
style A fill:#e3f2fd,stroke:#1565c0,color:#333 style E fill:#e8f5e9,stroke:#2e7d32,color:#333第5ステーションと対応させると、こんな感じです。
| 第5ステーション | 第6ステーション |
|---|---|
| 線形モデル / 木モデル | ニューラルネットワーク |
| 指標と損失 | 指標と損失 |
fit() の中で学習が完了する | 学習ループをより明示的に見る |
| ハイパーパラメータ調整と評価 | ハイパーパラメータ調整と評価 |
つまり、第6ステーションでいちばん大きく変わるのは「学習があるかどうか」ではなく、次の点です。
- 学習の流れを、より目に見える形でたどれるようになる
四、なぜ第6ステーションで勾配と逆伝播を強調するのか
Section titled “四、なぜ第6ステーションで勾配と逆伝播を強調するのか”第5ステーションでは、多くのモデルの学習の細部はライブラリの中に隠れていました。 第6ステーションでは、次のことをもっと直接的に扱うようになります。
- パラメータが多い
- モデルが何層もある
- 何度も更新を繰り返す必要がある
そのため、本当に理解する必要があるのは次の点です。
- 損失はどうやって作られるのか
- 勾配は何を表しているのか
- なぜパラメータが更新されるのか
逆伝播は、まず一言で覚えてよい
Section titled “逆伝播は、まず一言で覚えてよい”最初は微分の式を急いで覚えなくても大丈夫です。まずはこの一文で十分です。
順伝播は「結果を計算する」、逆伝播は「各パラメータをどう変えるべきかを計算する」。
これは、第6ステーション全体の中心になる考え方です。
第5ステーションの最適化の考え方は、すでに土台になっている
Section titled “第5ステーションの最適化の考え方は、すでに土台になっている”第5ステーションで、あなたはすでに次のものを見ています。
- 線形回帰の損失
- 勾配降下法
- 正則化
- 交差検証と過学習
なので、第6ステーションはゼロから始めるのではなく、これらをより明示的にしていく段階です。
- モデルがより深くなる
- パラメータが増える
- 学習ループがよりはっきり見える
五、なぜ第6ステーションで PyTorch を導入するのか
Section titled “五、なぜ第6ステーションで PyTorch を導入するのか”第5ステーションでは、scikit-learn は新人にとても向いています。流程がひとまとめに封装されているからです。
しかし深層学習に入ると、次のことがもっと必要になります。
- ネットワーク構造を自分で定義する
- 順伝播と逆伝播を自分で制御する
- 学習ループをより柔軟に組み立てる
- GPU、より大きなモデル、より複雑なデータと組み合わせる
これが PyTorch が登場する理由です。
まず sklearn と PyTorch の役割を分けて考える
Section titled “まず sklearn と PyTorch の役割を分けて考える”| ツール | 得意なこと |
|---|---|
scikit-learn | 古典 ML、統一インターフェース、素早い baseline |
PyTorch | 深層学習、柔軟なネットワーク定義、明示的な学習ループ |
だから、これらを「どちらが置き換えるか」で考えないでください。代わりに、次のように考えるのがよいです。
- 第5ステーションでは
sklearnで機械学習のワークフローを作る - 第6ステーションでは
PyTorchで深層学習の学習過程を開く
最も重要な橋渡しの理解
Section titled “最も重要な橋渡しの理解”すでに第5ステーションで次のものを理解しているなら、
- データ
- モデル
- 損失
- 評価
第6ステーションで新しく学ぶのは、実は1つだけです。
モデルのパラメータが、どうやって更新されるのかを、より明示的に制御する方法。
六、第6ステーションに入る前に、まず覚えておきたいこと
Section titled “六、第6ステーションに入る前に、まず覚えておきたいこと”- 第6ステーションは第5ステーションを否定するのではなく、その上に成り立っている
- 深層学習の最大の新能力は、表現を自動で学ぶこと
- 第5ステーションと第6ステーションの学習骨格は本質的に同じ
PyTorchは難しくするためではなく、学習過程をより制御しやすくするためにある
七、第6ステーションに入った後の、いちばん安定した学習順序
Section titled “七、第6ステーションに入った後の、いちばん安定した学習順序”もし第5ステーションから来たばかりなら、次の順番で進むのがおすすめです。
-
まず 6.1.1 学習前ガイド:この章でニューラルネットワーク基礎は何を学ぶのか を読む ニューロン、順伝播、逆伝播、オプティマイザといった言葉の位置を先にそろえます。
-
次に 6.1.3 ニューロンから多層パーセプトロンへ を読む まず「1つのニューロンが何をしているのか」を理解します。
-
それから 6.2.1 学習前ガイド:この章で PyTorch は何を学ぶのか に進む そして学習フローを
Tensor / Autograd / Module / DataLoader / Training Loopでつなげます。
この順番のほうが、最初から複雑なネットワーク構造に飛び込むよりずっと安定しています。
この節でいちばん持ち帰ってほしいこと
Section titled “この節でいちばん持ち帰ってほしいこと”もし1文だけ持ち帰るなら、これを覚えてください。
第6ステーションは「別の授業」ではなく、第5ステーションで学んだモデリングの主線が、より強い表現力とより明示的な学習過程へ自然に広がったものです。
だから、いちばん大切な収穫は次の点です。
- なぜ従来の ML の後に深層学習が必要なのかがわかる
- 深層学習で本当に新しくなる能力が何かがわかる
- なぜ逆伝播と PyTorch が出てくるのかがわかる
- 第5ステーションと第6ステーションが、実は同じモデリング骨格を共有しているとわかる
次へ進む前に、5 行の橋渡しメモを書きます。
- 旧スキル
- sklearn モデルを学習・評価できる。
- 同じ骨組み
- data → model → loss/metric → improvement → error analysis.
- 新しい能力
- ニューラルネットワークは、最終予測ルールだけでなく表現も学習する。
- 新しい制御
- PyTorch は forward、backward、optimizer、device、checkpoint のロジックを公開する。
- 次の行動
- 小さな neural network を1回実行し、loss が変わる理由を説明する。
このメモが自分の言葉で説明できれば、第 6 章は最初からやり直しではなく、既存のモデリング手順の拡張として読めます。
期待される結果
Section titled “期待される結果”このページの出力は Python ファイルではなく、心の中のモデルです。
I can explain what stays the same from sklearn to PyTorch.I can explain what becomes more explicit in PyTorch.I can point to one reason representation learning matters.I can describe why Chapter 6 prepares me for Transformer and LLMs.この4行をまだ説明できないなら、CNN、RNN、Transformer の名前へ進む前に、この橋渡しを読み直します。
レビュー観点と通過基準
- 合格する bridge note は、第5ステーションと同じ骨格を保ちます。data、model、loss または metric、improvement、error analysis です。
- そのうえで、第6ステーションで明示的になるものを言います。forward pass、backward pass、optimizer step、device choice、checkpoint です。
- 小さな neural network を 1 つ実行または読解し、representation learning がどの行で起きているかを指摘します。「model が deep になった」だけなら、まだ区別が曖昧です。
- tool を選ぶ前に、その問題が sklearn の単純さを必要とするのか、PyTorch の制御力を必要とするのか判断できれば、このページは完了です。