6.3.4 古典的な CNN アーキテクチャ
- LeNet、AlexNet、VGG、ResNet がそれぞれ何を貢献したかを説明できる。
- 「この設計は何を解決したのか」と考えながら古典的アーキテクチャを読める。
- 大きな kernel と、小さな kernel の積み重ねを比較できる。
- 最小の residual block を実装できる。
- 現代の CNN 実践でも残っている考え方を判断できる。
まず進化の流れを見る
Section titled “まず進化の流れを見る”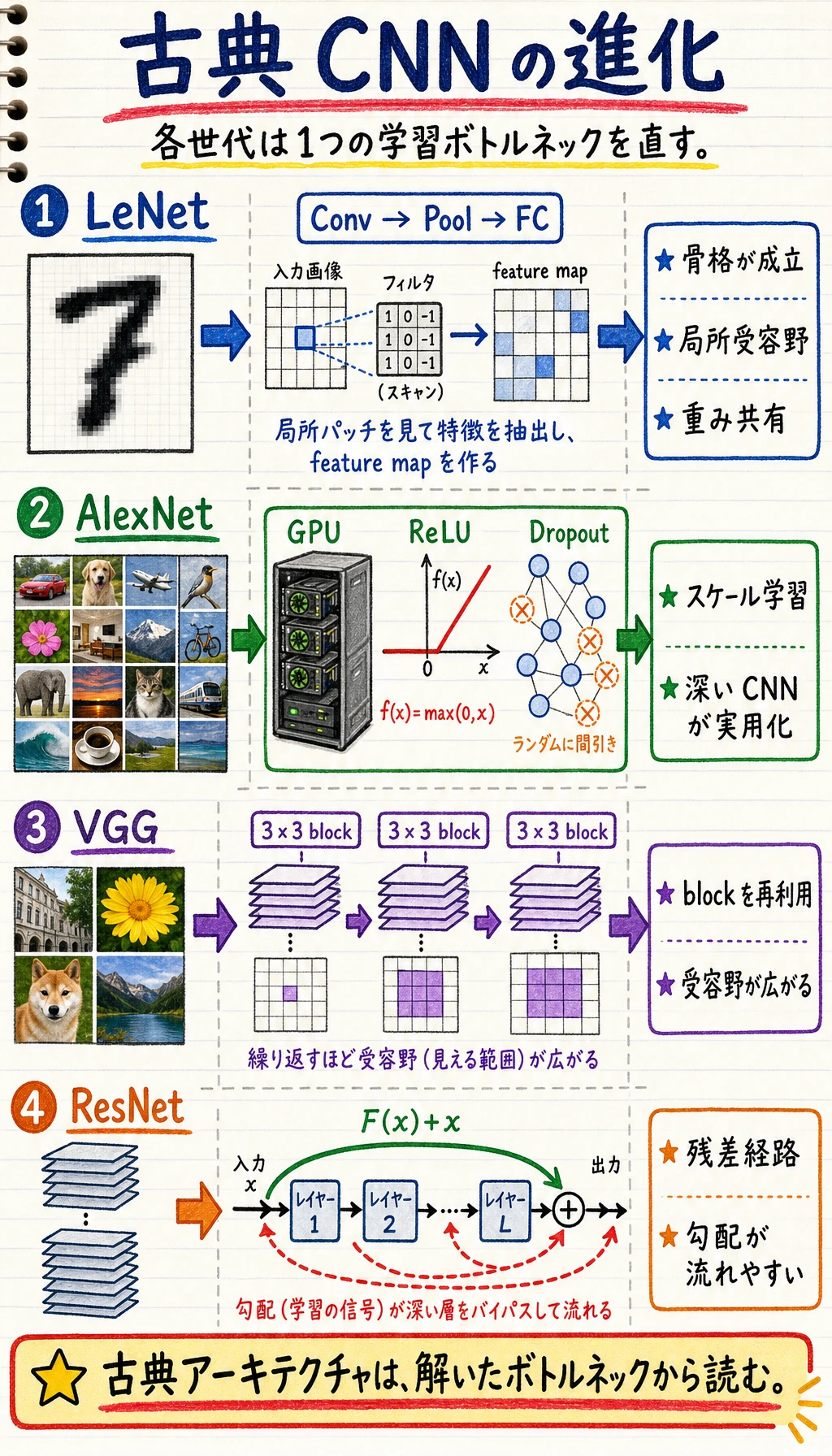
タイムラインは次のように読みます。
| アーキテクチャ | 覚えること | 主な学び |
|---|---|---|
| LeNet | 初期の CNN 骨格 | 畳み込みと pooling で画像認識できる |
| AlexNet | スケールと GPU 学習 | データ、計算資源、学習テクニックがそろうと深い CNN は強い |
| VGG | 繰り返しの 3 x 3 block | 小さな kernel でも大きな受容野をきれいに作れる |
| ResNet | residual path | とても深いネットワークには、勾配と情報が流れやすい経路が必要 |
重要なのは、今日これらのモデルをそのままコピーすることではありません。これらが答えた設計上の問いを引き継ぐことです。
LeNet:CNN の骨格
Section titled “LeNet:CNN の骨格”LeNet は古いモデルですが、骨格は今でも見慣れた形です。
長く残っている考え方は 3 つあります。
- 局所パターンを抽出する前に画像を flatten しない。
- pooling で局所反応を圧縮する。
- 後ろの層で高レベル特徴を使って分類する。
LeNet を理解すると、多くの画像分類器の最小構造が見えるようになります。
AlexNet:スケールが CNN を説得力あるものにした
Section titled “AlexNet:スケールが CNN を説得力あるものにした”AlexNet が重要だったのは、複数の要素を同時に組み合わせたからです。
- より大きなデータセット。
- より深い CNN。
- GPU 学習。
- 最適化を速くする ReLU。
- 正則化のための Dropout。
実践的な学びは、アーキテクチャだけでは勝てないということです。データ、計算資源、学習の安定性、正則化が一緒に噛み合う必要があります。
経験者にとっては、これは CNN 史における最初のシステム的な教訓です。モデル品質は、1 つの賢い層ではなく、積み重なった仕組みで決まります。
VGG:小さな kernel と繰り返し block
Section titled “VGG:小さな kernel と繰り返し block”VGG は、次のシンプルなレシピを広めました。
なぜ大きな kernel を 1 つ使わず、小さな kernel を重ねるのでしょうか。
- 層を重ねることで受容野を広げられる。
- 各層で非線形性を追加できる。
- パラメータ数を制御しやすい。
- 繰り返し block は読みやすく再現しやすい。
実験 1:kernel のパラメータ数を比べる
Section titled “実験 1:kernel のパラメータ数を比べる”この比較だけで全てが決まるわけではありませんが、役に立つ直感になります。
from torch import nn
def count_params(module): return sum(p.numel() for p in module.parameters() if p.requires_grad)
one_large_kernel = nn.Conv2d(16, 16, kernel_size=7, padding=3)three_small_kernels = nn.Sequential( nn.Conv2d(16, 16, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(16, 16, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(16, 16, kernel_size=3, padding=1),)
print("kernel_param_lab")print("one 7x7 conv :", count_params(one_large_kernel))print("three 3x3 conv:", count_params(three_small_kernels))期待される出力:
kernel_param_labone 7x7 conv : 12560three 3x3 conv: 6960この設定では、3 x 3 を積み重ねるほうがパラメータが少なく、畳み込みの間に非線形性も入れられます。VGG 風の考え方が、きれいな baseline になった理由です。
実験 2:VGG 風 block を実行する
Section titled “実験 2:VGG 風 block を実行する”import torchfrom torch import nn
vgg_block = nn.Sequential( nn.Conv2d(3, 16, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(16, 16, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(2),)
x = torch.randn(2, 3, 32, 32)y = vgg_block(x)
print("vgg_block_lab")print("input:", tuple(x.shape))print("output:", tuple(y.shape))期待される出力:
vgg_block_labinput: (2, 3, 32, 32)output: (2, 16, 16, 16)読み方:
- 2 つの
3 x 3畳み込みが feature を続けて洗練する。 - pooling が高さと幅を半分にする。
- 出力 channel は
16になる。
ResNet:深さを学習可能にする
Section titled “ResNet:深さを学習可能にする”深いネットワークは理論上より表現力がありますが、実際には最適化が難しくなることがあります。ResNet の中心アイデアは residual connection です。
output = learned_change(x) + x各 block にまったく新しい表現を強制するのではなく、入力に対する変化を学ばせます。もし block がまだ有用な変化を学べていなくても、shortcut が情報を前へ運びます。
実験 3:Residual Block を実装する
Section titled “実験 3:Residual Block を実装する”import torchfrom torch import nn
class ResidualBlock(nn.Module): def __init__(self, channels): super().__init__() self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) self.relu = nn.ReLU() self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x): identity = x out = self.relu(self.conv1(x)) out = self.conv2(out) out = out + identity return self.relu(out)
block = ResidualBlock(8)x = torch.randn(2, 8, 16, 16)y = block(x)
print("residual_block_lab")print("input:", tuple(x.shape))print("output:", tuple(y.shape))期待される出力:
residual_block_labinput: (2, 8, 16, 16)output: (2, 8, 16, 16)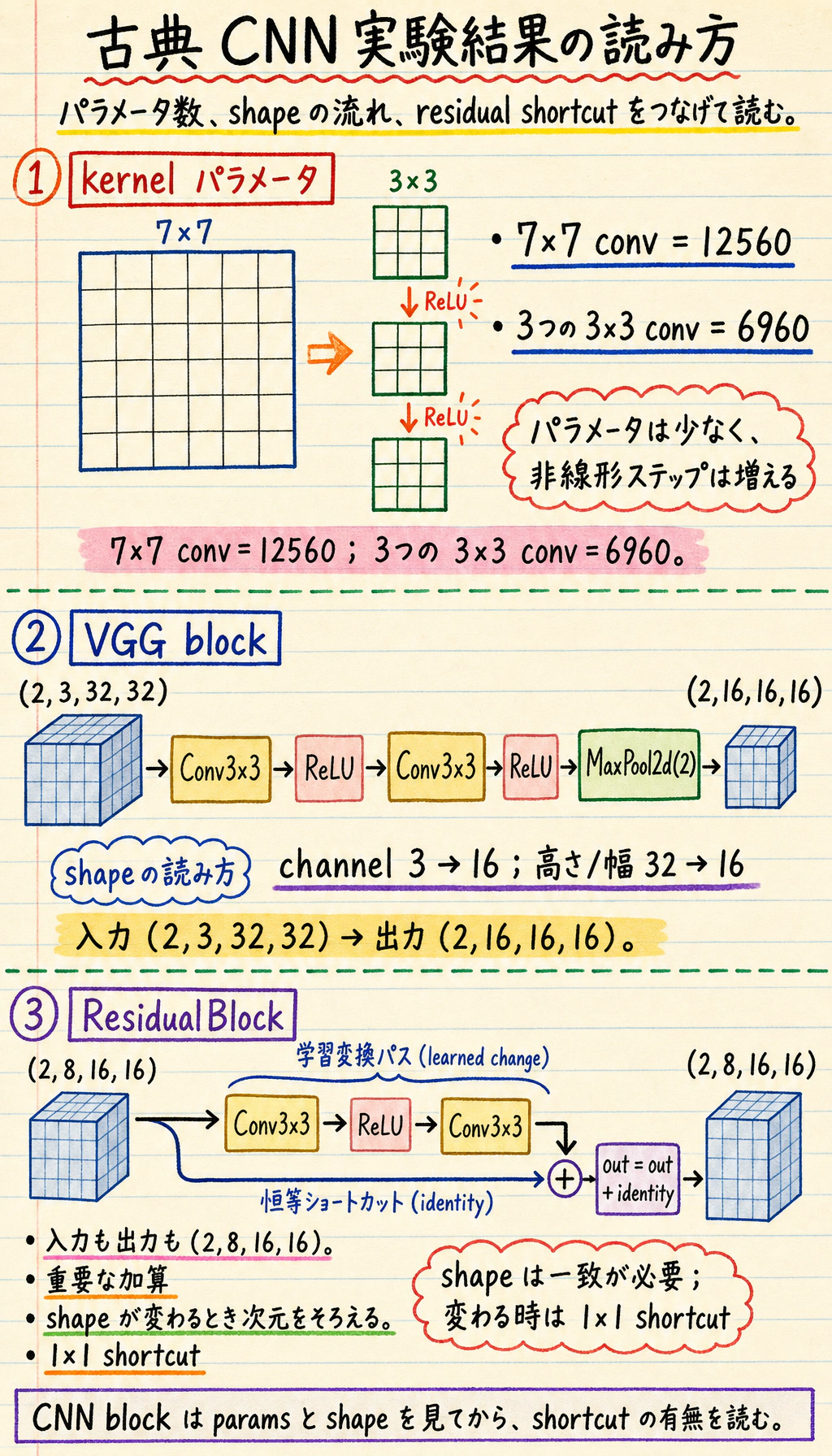
最も重要な行はこれです。
out = out + identityこの加算は要素ごとの加算なので、shape が一致していなければなりません。実際の ResNet 変種では、channel 数や空間サイズが変わるとき、shortcut 側に 1 x 1 畳み込みを使って次元をそろえます。
アーキテクチャ図の読み方
Section titled “アーキテクチャ図の読み方”新しい CNN アーキテクチャを見たら、次の問いを立てます。
| 質問 | なぜ重要か |
|---|---|
| 最初の段階で空間サイズをどう下げるか | 早すぎる圧縮は細部を失う |
| channel はどこで増えるか | channel は特徴の多様性を保存する |
| block は繰り返されているか | 繰り返し block は拡張しやすい |
| shortcut path はあるか | shortcut は最適化と情報流を助ける |
| classifier head はどう作られているか | Flatten と GAP ではパラメータコストが違う |
正確な層数を暗記するより、この読み方のほうが実用的です。
今日でも重要なこと
Section titled “今日でも重要なこと”現代のプロジェクトで LeNet や AlexNet から始めることは少ないかもしれません。それでも考え方は残っています。
- LeNet:feature extractor と classifier の分担。
- AlexNet:データ、計算資源、活性化、正則化をシステムとして見ること。
- VGG:単純な block の繰り返し。
- ResNet:residual path を基本的な設計道具として使うこと。
現代的な CNN backbone やハイブリッドなビジョンモデルでも、名前や block が新しく見えるだけで、これらの考え方を受け継いでいることが多いです。
アーキテクチャ記憶カードを 1 つ作ります。
- LeNet の要点
- 畳み込み特徴抽出器 + 分類ヘッド
- AlexNet の要点
- スケール、GPU、ReLU、正則化
- VGG の要点
- 小さな3x3ブロックの繰り返し
- ResNet の要点
- ショートカット経路で深い層を学習可能にする
- コードの手がかり
- residual block は out + identity を使う
これは、実務で本当に覚える価値のある歴史の粒度です。現代的な backbone を読む前に、すべての layer 数を暗記する必要はありません。
よくあるミス
Section titled “よくあるミス”| ミス | よりよい見方 |
|---|---|
| モデル名を暗記する | 各モデルが解決したボトルネックを覚える |
| VGG を「層が多いだけ」と見る | 本質は小さな kernel block の繰り返し |
| ResNet を「とても深いだけ」と見る | 本質は深さを学習可能にしたこと |
| 古典モデルをそのままコピーする | 多くの場合、現代的な事前学習 backbone から始める |
| 計算コストを無視する | アーキテクチャ選択はデータ規模とデプロイ制約に合わせる |
- LeNet、AlexNet、VGG、ResNet をそれぞれ一文で要約する。
ResidualBlock(8)をResidualBlock(16)に変え、入力 tensor も更新する。- VGG 風 block から
3 x 3畳み込みを 1 つ削除する。何が変わり、何が変わらないか。 - channel 数が違うと
out + identityが失敗する理由を説明する。 - 現代的な CNN backbone を 1 つ選び、どの古典的アイデアをまだ使っているかを確認する。
参考実装と解説
- LeNet は畳み込みによる視覚認識の原型、AlexNet は大規模深層 CNN、VGG は小さな畳み込みの積み重ね、ResNet は residual connection による深層化です。
ResidualBlock(16)にするなら、入力 tensor の channel も 16 にする必要があります。畳み込みと残差加算の両方で shape が合う必要があります。3 x 3畳み込みを 1 つ削ると、パラメータ数と非線形変換の回数が減ります。padding/stride が同じなら空間サイズは多くの場合変わりません。out + identityは要素ごとの加算なので、shape が完全に一致する必要があります。channel が違う場合は projection や1 x 1畳み込みで合わせます。- 現代的な CNN でも、局所畳み込み、channel 拡張、正規化、residual connection、GAP head などの古典的アイデアが残っています。
- 古典的な CNN は、名前のリストではなく設計の進化です。
- LeNet は骨格、AlexNet はスケール、VGG は小さな block の反復、ResNet は深さの学習しやすさを示しました。
- 小さな kernel の積み重ねは、パラメータ効率と表現力を両立しやすい。
- Residual connection は情報を保ち、最適化を助けます。
- 実用的な力は、アーキテクチャの背後にある設計動機を読むことです。