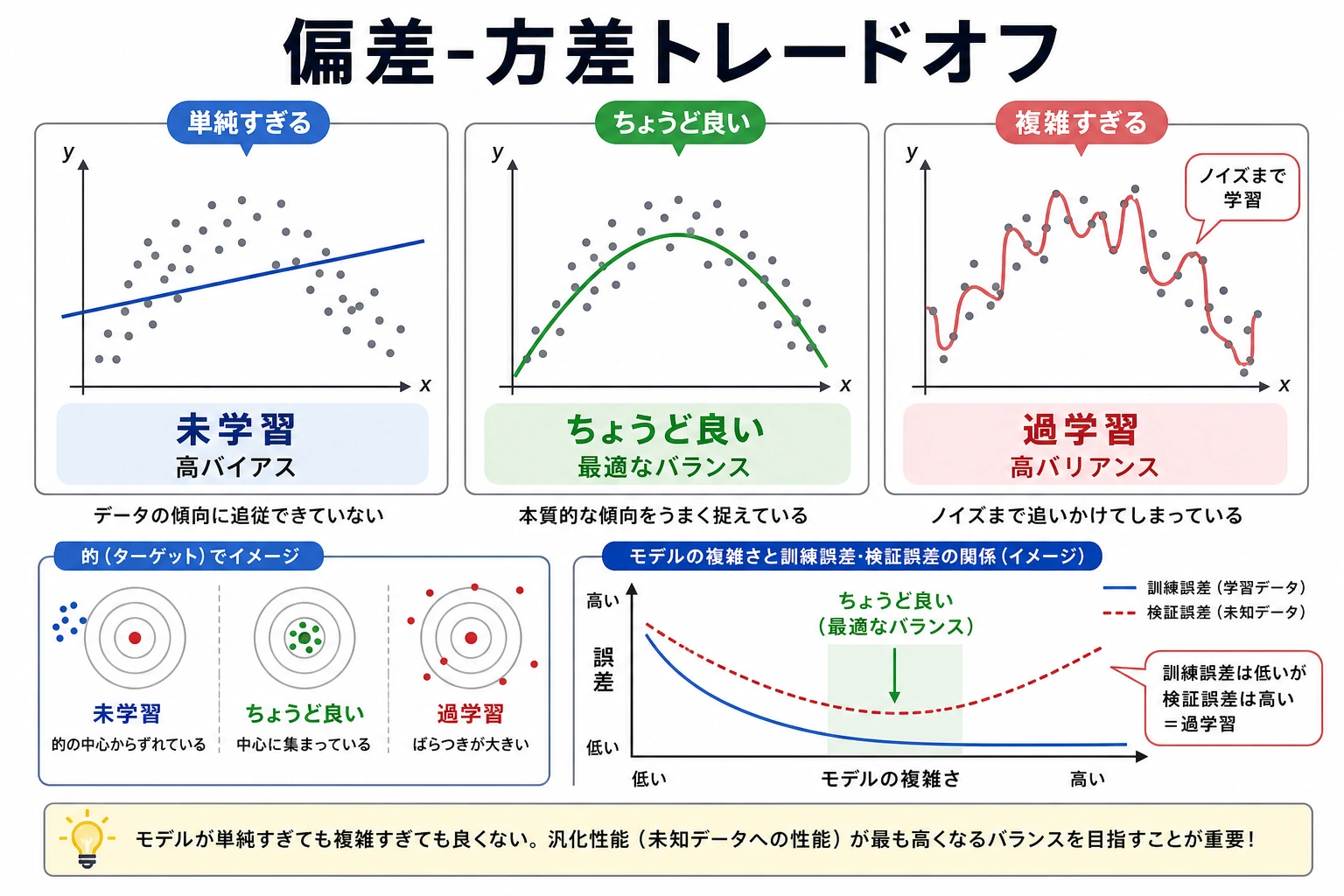
5.4.4 バイアス・バリアンスのトレードオフ
この節では、決定木を使って次を確認します。
- モデル複雑度が train/test score をどう変えるか;
- train-test gap からアンダーフィットとオーバーフィットを見分ける方法;
- 学習曲線で、データ追加が効きそうかどうかを見る方法;
- high bias と high variance で取るべき行動。
セットアップ
Section titled “セットアップ”python -m pip install -U scikit-learn numpy完全な実験を実行する
Section titled “完全な実験を実行する”bias_variance_lab.py を作成します。
import numpy as npfrom sklearn.datasets import load_breast_cancerfrom sklearn.metrics import accuracy_scorefrom sklearn.model_selection import learning_curve, train_test_splitfrom sklearn.tree import DecisionTreeClassifier
X, y = load_breast_cancer(return_X_y=True)X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25, random_state=42, stratify=y)
print("complexity_lab")for depth in [1, 3, 5, None]: model = DecisionTreeClassifier(max_depth=depth, random_state=42) model.fit(X_train, y_train) train_acc = accuracy_score(y_train, model.predict(X_train)) test_acc = accuracy_score(y_test, model.predict(X_test)) gap = train_acc - test_acc print( f"max_depth={str(depth):<4} " f"train={train_acc:.3f} test={test_acc:.3f} gap={gap:.3f} " f"leaves={model.get_n_leaves()}" )
print("learning_curve_lab")model = DecisionTreeClassifier(max_depth=3, random_state=42)train_sizes, train_scores, val_scores = learning_curve( model, X, y, cv=5, train_sizes=[0.2, 0.4, 0.6, 0.8, 1.0], scoring="accuracy",)for size, train_mean, val_mean in zip(train_sizes, train_scores.mean(axis=1), val_scores.mean(axis=1)): print(f"train_size={size:<3} train={train_mean:.3f} cv={val_mean:.3f} gap={train_mean - val_mean:.3f}")実行します。
python bias_variance_lab.py期待される出力:
complexity_labmax_depth=1 train=0.923 test=0.923 gap=-0.001 leaves=2max_depth=3 train=0.977 test=0.944 gap=0.032 leaves=7max_depth=5 train=0.995 test=0.937 gap=0.058 leaves=15max_depth=None train=1.000 test=0.923 gap=0.077 leaves=18learning_curve_labtrain_size=91 train=0.989 cv=0.847 gap=0.142train_size=182 train=0.986 cv=0.870 gap=0.116train_size=273 train=0.978 cv=0.903 gap=0.075train_size=364 train=0.975 cv=0.917 gap=0.057train_size=455 train=0.974 cv=0.919 gap=0.055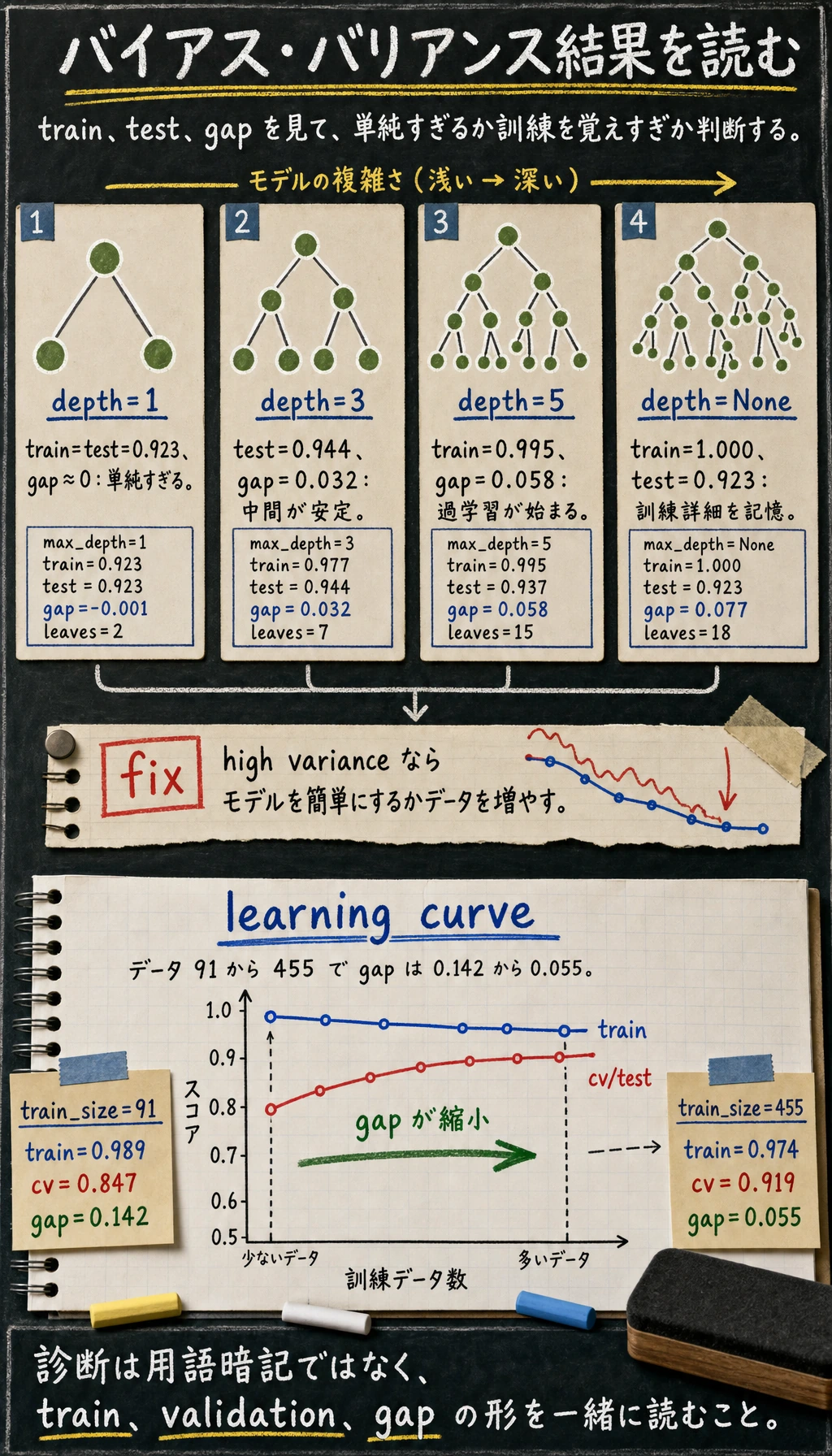
複雑度の実験を読む
Section titled “複雑度の実験を読む”max_depth が大きいほど、木は複雑になります。
max_depth=1 train=0.923 test=0.923 gap=-0.001 leaves=2max_depth=None train=1.000 test=0.923 gap=0.077 leaves=18max_depth=1 は単純です。train と test は近いですが、スコアは最高ではありません。これは high bias、つまりモデルが単純すぎる状態かもしれません。
max_depth=None は訓練データを完全に覚えますが、test accuracy は下がります。これは high variance、つまり訓練の細部に合わせすぎて汎化できない状態です。
実用上は中間がよく効くことが多いです。
max_depth=3 train=0.977 test=0.944 gap=0.032訓練データで満点ではありませんが、よりよく汎化しています。
学習曲線は、訓練データが増えると何が起きるかを示します。
train_size=91 train=0.989 cv=0.847 gap=0.142train_size=455 train=0.974 cv=0.919 gap=0.055データが増えると、検証スコアが上がり、gap が小さくなっています。これは、追加データが役立つ可能性を示します。ただし、特徴量や調整による改善余地も残っています。
| パターン | ありそうな問題 | 試すこと |
|---|---|---|
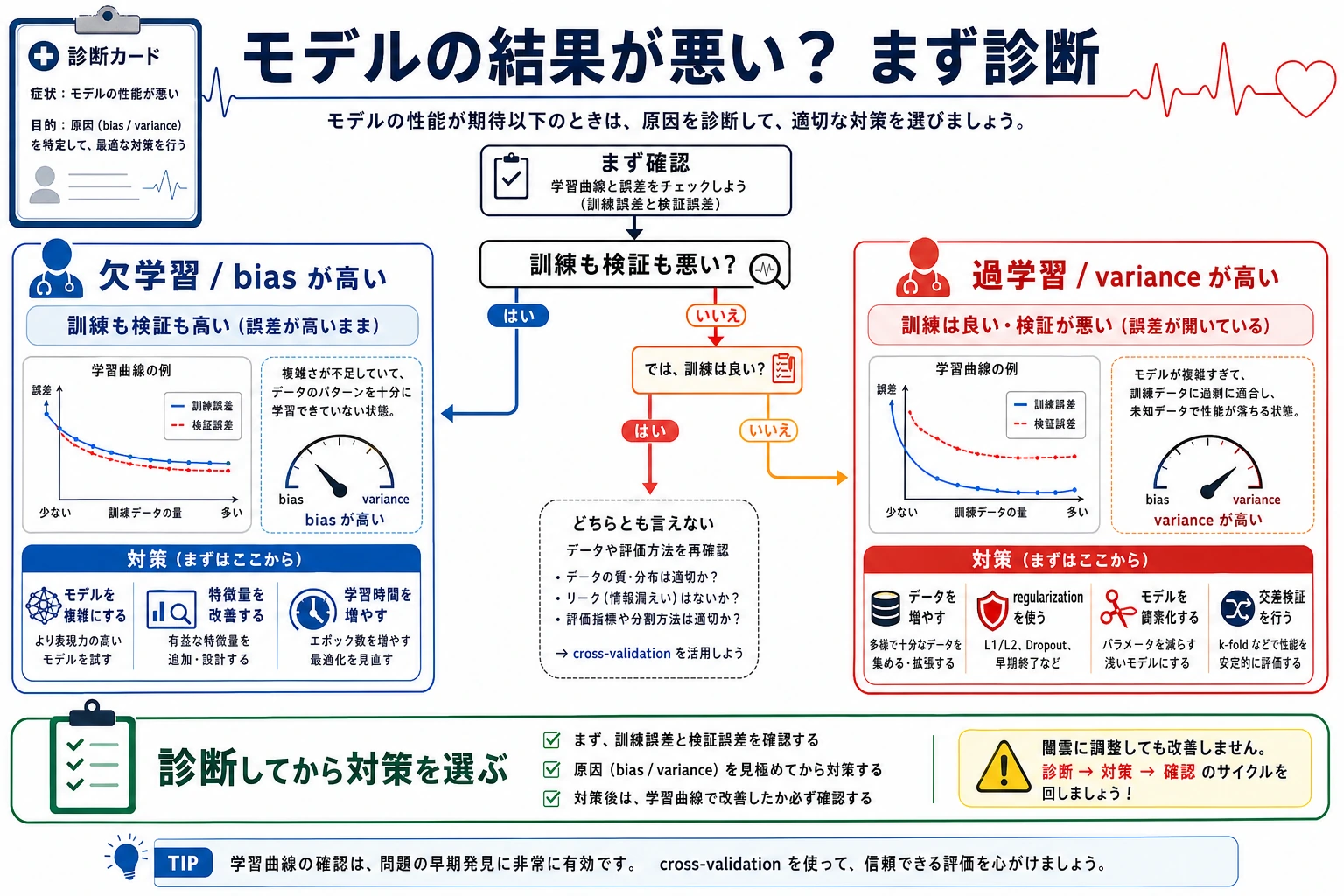
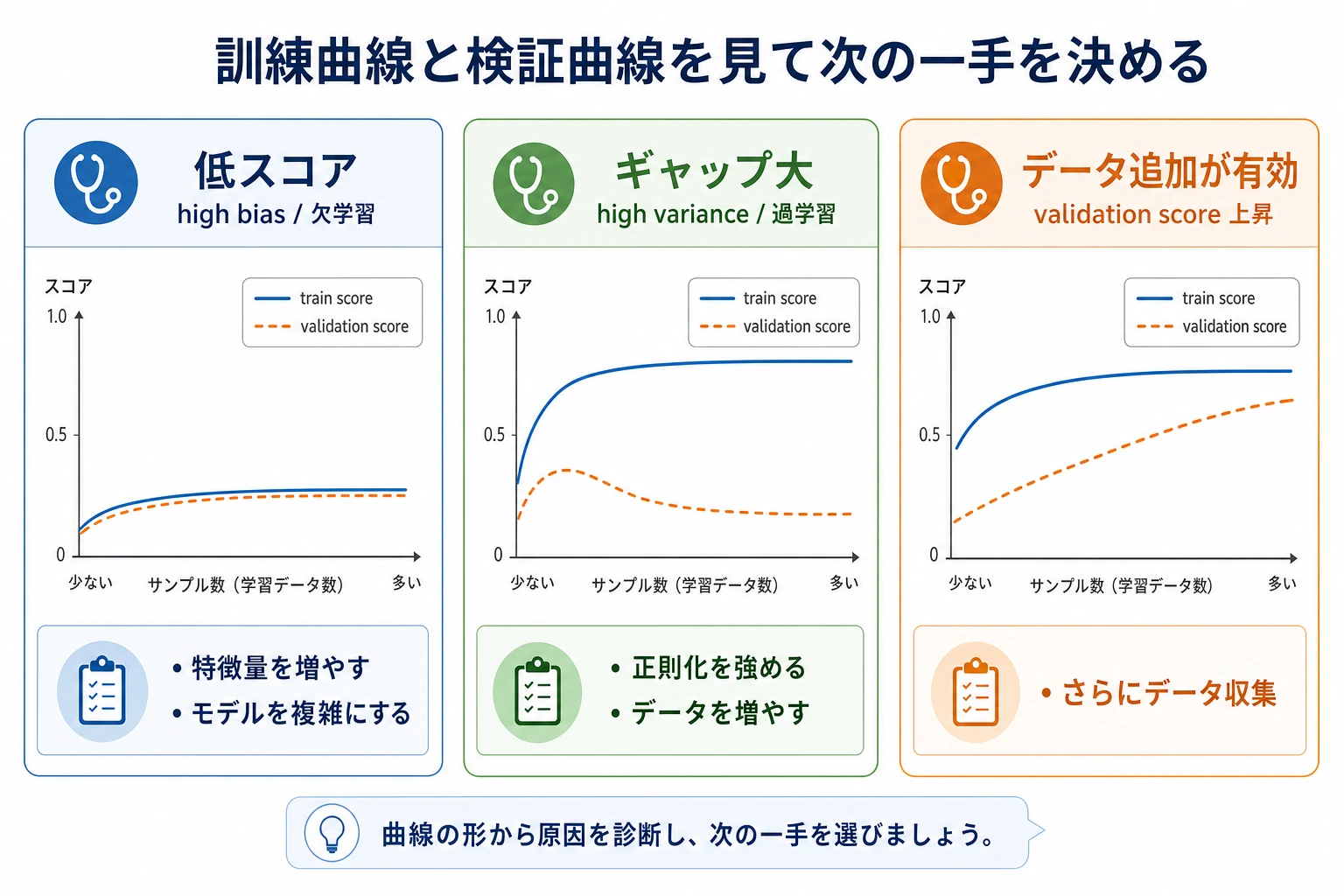
| train 低い、validation 低い | high bias / アンダーフィット | より表現力のあるモデル、良い特徴量、弱い正則化 |
| train 高い、validation 低い | high variance / オーバーフィット | モデルを単純にする、正則化を強める、データを増やす |
| train 高い、validation 高い | 良いフィット | final holdout で確認し、ドリフトを監視 |
| validation が fold ごとに大きく揺れる | 不安定またはセグメント差 | fold を調べ、データ追加や頑健なモデルを検討 |
1 つの指標だけで診断しないでください。train score、validation score、gap、そしてミスが特定セグメントに集中していないかを見ます。
実用的な対処
Section titled “実用的な対処”high bias のとき:
- 有用な特徴量を追加する;
- より表現力のあるモデルを使う;
- 強すぎる正則化を弱める;
- 反復型モデルなら学習を長くする。
high variance のとき:
- モデル複雑度を下げる;
- 正則化を強める;
- より多様で代表的なデータを集める;
- クロスバリデーションと final holdout を使う;
- バリアンスを下げる集成モデルを検討する。
このページを終えたら、この evidence card を残します。
- 評価設定
- 分割、交差検証、指標、ベースライン、比較対象
- 結果
- スコア表、曲線、confusion matrix、検証結果、または検索結果
- 判断
- データ、特徴量、モデル、閾値、またはハイパーパラメータを変えるかどうか
- 失敗確認
- リーク、不安定な検証、誤った指標、またはテストセットでのチューニング
- 期待される成果
- 次のモデリング判断を支える評価記録
よくあるトラブル
Section titled “よくあるトラブル”| 症状 | よくある原因 | 修正 |
|---|---|---|
| train も validation も悪い | モデルがパターンを表現できない | 特徴量またはモデルクラスを改善する |
| train は満点、validation は悪い | オーバーフィット | 深さ制限、枝刈り、正則化 |
| データ追加で validation が上がる | バリアンスまたはデータ不足 | より代表的なデータを集める |
| データ追加が効かない | high bias またはラベルノイズ | 特徴量、ラベル、モデルを改善する |
| validation が fold ごとに跳ねる | データが不均一 | セグメント分布を確認する |
- 木に
min_samples_leaf=5を追加してください。gap はどう変わりますか? max_depth=2, 4, 6, 8を試してください。test accuracy はどこで最大になりますか?- 木をロジスティック回帰に置き換えてください。問題は bias と variance のどちらに近いですか?
- 複雑度実験を 1 回の test split ではなく 5-fold CV に変えてください。
- 最良の木の誤分類を確認してください。特定クラスに集中していますか?
参考実装と解説
min_samples_leaf=5は小さな葉を作りにくくするため、train/test gap は縮まりやすいです。両方のスコアが下がるなら単純にしすぎています。- test accuracy は中間の深さで最大になることが多いです。浅すぎると underfitting、深すぎると訓練 accuracy だけ上がって overfitting します。
- ロジスティック回帰は bias の確認に使えます。木だけ訓練で高くテストで悪いなら variance、両方低いなら特徴量やモデル族が弱い可能性があります。
- 5-fold CV は 1 回の分割より安定して複雑度を比較できます。平均スコアが高く、ばらつきも許容できる深さを選びます。
- 誤分類が特定クラスに集中するなら、そのクラスの特徴不足、ラベル曖昧さ、クラス不均衡を疑います。散らばっているなら残るノイズの影響かもしれません。
合格チェック
Section titled “合格チェック”次を説明できれば、この節はクリアです。
- high bias は、モデルが単純すぎるか信号が足りない状態;
- high variance は、モデルが訓練の細部に敏感すぎる状態;
- train-validation gap は実用的な診断手がかり;
- 学習曲線は追加データが効くかを示す;
- 対処は用語ではなく、観察されたパターンで決める。