2.3.2 プロジェクト:Webスクレイパー
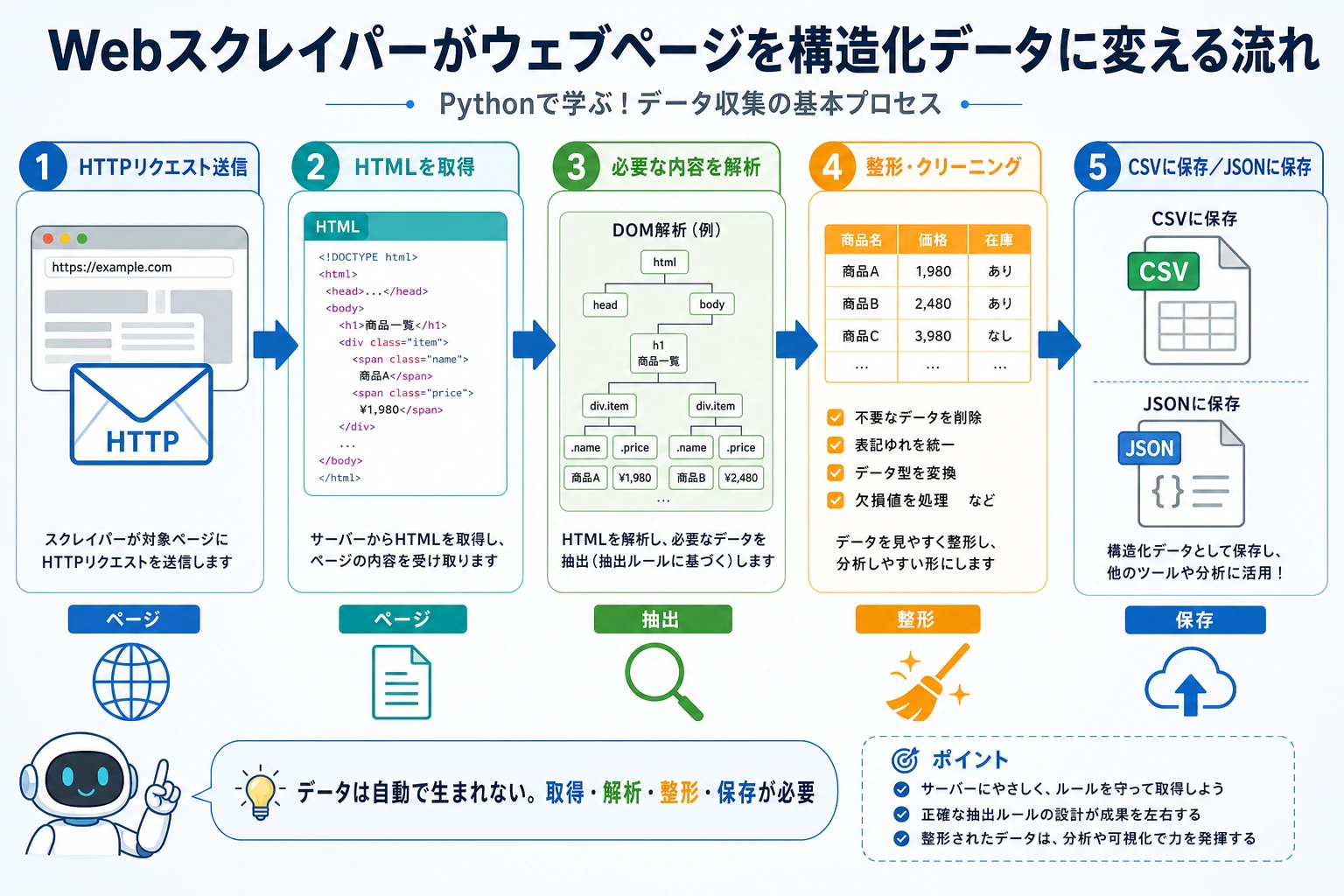
プロジェクトの位置づけ
Section titled “プロジェクトの位置づけ”このプロジェクトでは、Python を使ってはじめてインターネットからデータを取得します。HTTP リクエスト、HTML 解析、データの整理、ファイル保存をつなげて学びます。実際のデータは、何もないところから出てくるのではなく、収集して、整理して、構造化する必要があることを理解しましょう。
プロジェクトの目標
Section titled “プロジェクトの目標”- HTTP リクエストと Web ページ構造の基本を理解する
requestsライブラリを使って HTTP リクエストを送る方法を学ぶBeautifulSoupを使って HTML を解析する方法を学ぶ- 実用的な Web データ収集ツールを作る
プロジェクトの概要
Section titled “プロジェクトの概要”Webスクレイパー(Web Scraper)は、Web ページからデータを自動で抽出するプログラムです。たとえば、次のような用途があります。
- 求人サイトから求人情報を集める
- ニュースサイトから記事タイトルを取得する
- EC サイトから商品価格を取得する
- AI モデルの学習用データを集める
ここでは、Web ページの情報を取得して、構造化データとして保存できるスクレイパーを作ります。
事前知識:HTTP と HTML
Section titled “事前知識:HTTP と HTML”HTTP リクエストとは?
Section titled “HTTP リクエストとは?”ブラウザで URL を入力して Enter を押すと、ブラウザはサーバーに HTTP リクエスト を送ります。するとサーバーは Web ページの内容(HTTP レスポンス)を返します。
あなたのブラウザ → HTTP リクエスト → サーバーあなたのブラウザ ← HTTP レスポンス ← サーバー(HTML を返す)Python の requests ライブラリを使うと、ブラウザと同じようにリクエストを送って、Web ページの内容を取得できます。
HTML とは?
Section titled “HTML とは?”HTML(HyperText Markup Language)は、Web ページの「骨組み」です。簡単な HTML ページの例を見てみましょう。
<html><head> <title>サンプルページ</title></head><body> <h1>私のサイトへようこそ</h1> <p class="intro">これは紹介文です。</p> <ul> <li>項目 1</li> <li>項目 2</li> <li>項目 3</li> </ul> <a href="https://example.com">ここをクリック</a></body></html>スクレイパーの役割は、これらの HTML タグから必要なデータを取り出すことです。
第1ステップ:依存ライブラリをインストールする
Section titled “第1ステップ:依存ライブラリをインストールする”pip install requests beautifulsoup4| ライブラリ | 役割 |
|---|---|
requests | HTTP リクエストを送って、Web ページの内容を取得する |
beautifulsoup4 | HTML を解析して、データを取り出す |
第2ステップ:HTTP リクエストを送る
Section titled “第2ステップ:HTTP リクエストを送る”import requests
# GET リクエストを送るresponse = requests.get("https://httpbin.org/get")
# レスポンスの状態を確認するprint(f"ステータスコード: {response.status_code}") # 200 は成功を表すprint(f"文字コード: {response.encoding}")
# レスポンス内容を確認するprint(response.text[:200]) # テキスト内容(最初の 200 文字)
# レスポンスのステータスコードの意味# 200: 成功# 404: ページが見つからない# 403: アクセス禁止# 500: サーバーエラーリクエストヘッダーを追加する(ブラウザをまねる)
Section titled “リクエストヘッダーを追加する(ブラウザをまねる)”サイトによっては、リクエストがブラウザから来たものかを確認することがあります。その場合は User-Agent を設定します。
headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) " "AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/120.0.0.0 Safari/537.36"}
response = requests.get("https://example.com", headers=headers)print(response.status_code)リクエスト例外を処理する
Section titled “リクエスト例外を処理する”import requests
def fetch_page(url: str) -> str | None: """安全に Web ページの内容を取得する""" try: response = requests.get(url, headers=headers, timeout=10) response.raise_for_status() # ステータスコードが 200 でない場合は例外を送出 response.encoding = response.apparent_encoding # 文字コードを自動判定 return response.text except requests.ConnectionError: print(f"❌ {url} に接続できません") except requests.Timeout: print(f"❌ リクエストがタイムアウトしました: {url}") except requests.HTTPError as e: print(f"❌ HTTP エラー: {e}") return None第3ステップ:HTML を解析する
Section titled “第3ステップ:HTML を解析する”from bs4 import BeautifulSoup
html = """<html><body> <h1>Python コース一覧</h1> <div class="course-list"> <div class="course"> <h2 class="title">Python 入門</h2> <span class="price">¥99</span> <span class="rating">4.8</span> </div> <div class="course"> <h2 class="title">Python 応用</h2> <span class="price">¥199</span> <span class="rating">4.6</span> </div> <div class="course"> <h2 class="title">Python AI 実践</h2> <span class="price">¥399</span> <span class="rating">4.9</span> </div> </div></body></html>"""
# BeautifulSoup オブジェクトを作成するsoup = BeautifulSoup(html, "html.parser")
# 1つの要素を探すtitle = soup.find("h1")print(title.text) # Python コース一覧
# 一致する要素をすべて探すcourses = soup.find_all("div", class_="course")for course in courses: name = course.find("h2", class_="title").text price = course.find("span", class_="price").text rating = course.find("span", class_="rating").text print(f"{name} - {price} - 評価: {rating}")
# 出力:# Python 入門 - ¥99 - 評価: 4.8# Python 応用 - ¥199 - 評価: 4.6# Python AI 実践 - ¥399 - 評価: 4.9BeautifulSoup のよく使うメソッド
Section titled “BeautifulSoup のよく使うメソッド”# タグ名で検索するsoup.find("h1") # 最初の h1 を探すsoup.find_all("p") # すべての p を探す
# class で検索するsoup.find("div", class_="content")soup.find_all("span", class_="price")
# id で検索するsoup.find("div", id="main")
# CSS セレクタ(より強力)soup.select("div.course h2") # div.course の下にあるすべての h2soup.select("ul > li") # ul の直下の子要素である lisoup.select("a[href]") # href 属性を持つすべての a タグ
# テキストと属性を取得するtag = soup.find("a")print(tag.text) # リンクテキストprint(tag.get("href")) # href 属性値print(tag["href"]) # 上と同じ第4ステップ:完全なプロジェクト実践
Section titled “第4ステップ:完全なプロジェクト実践”プロジェクト:名言サイトをスクレイピングする
Section titled “プロジェクト:名言サイトをスクレイピングする”ここでは、スクレイピング練習用のサイト quotes.toscrape.com を使います。
"""Webスクレイパープロジェクト:名言を取得する対象サイト:https://quotes.toscrape.com"""
import requestsfrom bs4 import BeautifulSoupimport jsonimport time
def scrape_quotes(max_pages: int = 5) -> list[dict]: """名言データを取得する""" all_quotes = [] base_url = "https://quotes.toscrape.com"
for page in range(1, max_pages + 1): url = f"{base_url}/page/{page}/" print(f"第 {page} ページを取得中: {url}")
try: response = requests.get(url, timeout=10) response.raise_for_status() except requests.RequestException as e: print(f" ❌ リクエストに失敗しました: {e}") continue
soup = BeautifulSoup(response.text, "html.parser") quotes = soup.find_all("div", class_="quote")
if not quotes: print(" これ以上データはありません") break
for quote in quotes: text = quote.find("span", class_="text").text author = quote.find("small", class_="author").text tags = [tag.text for tag in quote.find_all("a", class_="tag")]
all_quotes.append({ "text": text, "author": author, "tags": tags })
print(f" ✅ {len(quotes)} 件の名言を取得しました") time.sleep(1) # サーバーに負荷をかけないよう、少し待つ
return all_quotes
def save_to_json(data: list[dict], filename: str = "quotes.json") -> None: """JSON ファイルとして保存する""" with open(filename, "w", encoding="utf-8") as f: json.dump(data, f, ensure_ascii=False, indent=2) print(f"\n💾 {len(data)} 件のデータを {filename} に保存しました")
def save_to_csv(data: list[dict], filename: str = "quotes.csv") -> None: """CSV ファイルとして保存する""" import csv with open(filename, "w", newline="", encoding="utf-8") as f: writer = csv.DictWriter(f, fieldnames=["text", "author", "tags"]) writer.writeheader() for item in data: item_copy = item.copy() item_copy["tags"] = ", ".join(item["tags"]) writer.writerow(item_copy) print(f"💾 {filename} に保存しました")
def analyze_quotes(quotes: list[dict]) -> None: """データを分析する""" print("\n📊 データ分析:") print(f" 名言の総数: {len(quotes)}")
# 著者ごとの名言数を集計する author_count = {} for q in quotes: author = q["author"] author_count[author] = author_count.get(author, 0) + 1
# 件数の多い順に並べる sorted_authors = sorted(author_count.items(), key=lambda x: x[1], reverse=True) print(f" 著者数: {len(sorted_authors)}") print(f"\n 名言が最も多い著者 5 人:") for author, count in sorted_authors[:5]: print(f" {author}: {count} 件")
# タグを集計する all_tags = {} for q in quotes: for tag in q["tags"]: all_tags[tag] = all_tags.get(tag, 0) + 1
sorted_tags = sorted(all_tags.items(), key=lambda x: x[1], reverse=True) print(f"\n 人気のタグ 10 個:") for tag, count in sorted_tags[:10]: print(f" #{tag}: {count} 回")
def main(): print("=== 名言スクレイパー ===\n")
# データを取得する quotes = scrape_quotes(max_pages=5)
if not quotes: print("データを取得できませんでした") return
# データを保存する save_to_json(quotes) save_to_csv(quotes)
# データを分析する analyze_quotes(quotes)
if __name__ == "__main__": main()スクレイピングの注意点
Section titled “スクレイピングの注意点”課題 1:エラー再試行機能
Section titled “課題 1:エラー再試行機能”リクエストが失敗したとき、数秒待って自動で再試行する機能をスクレイパーに追加しましょう(最大 3 回)。
課題 2:複数ページの自動ページ送り
Section titled “課題 2:複数ページの自動ページ送り”「次のページ」ボタンを自動で検出して、次のページがなくなるまで取得し続けるようにしましょう。
課題 3:データの重複排除
Section titled “課題 3:データの重複排除”同じデータを複数回取得した場合、自動で重複を取り除くようにしましょう。
課題 4:コマンドライン引数
Section titled “課題 4:コマンドライン引数”sys.argv または argparse を使って、コマンドラインから取得ページ数と出力ファイル名を指定できるようにしましょう。
python scraper.py --pages 10 --output data.jsonプロジェクト参考とレビュー観点
- リクエストループの外側にリトライとバックオフを追加し、3 回失敗したら停止します。リトライ回数を見えるようにして、ネットワーク問題を追いやすくします。
- 「次のページ」リンクを検出して、次がなくなるまでたどります。ループ対策をしたいなら訪問済み URL を記録します。
- 重複排除には、quote の本文 + author のような安定キー、または対象サイトが提供する一意 ID / URL を使います。
- ページ数と出力先に
argparse引数を追加し、ハードコードではなくコマンドラインから再利用できるようにします。 - 自己チェック: HTML を取得できること、一時的なネットワークエラーを処理できること、JSON/CSV を出力できること、重複行がないことを確認します。
プロジェクトの自己チェックリスト
Section titled “プロジェクトの自己チェックリスト”- HTTP リクエストを正常に送ってレスポンスを取得できる
- HTML を解析して目的のデータを取り出せる
- データを JSON および/または CSV 形式で保存できる
- 適切なエラー処理がある(ネットワーク異常、解析異常)
- リクエストの間に待機時間がある(
time.sleep) - コード構成が分かりやすく、関数の役割分担が明確
- 簡単なデータ分析と集計ができる
バージョン別の進め方
Section titled “バージョン別の進め方”| バージョン | 目標 | 重点成果物 |
|---|---|---|
| 基本版 | 最小構成の一連の流れを動かす | 入力・処理・出力ができ、サンプルを 1 つ以上残す |
| 標準版 | 画面で見せられるプロジェクトにする | 設定、ログ、エラー処理、README、スクリーンショットを追加する |
| チャレンジ版 | ポートフォリオ品質に近づける | 評価、比較実験、失敗例の分析、次の改善方針を追加する |
まずは基本版を完成させることをおすすめします。最初から全部を盛り込もうとしないでください。バージョンを 1 つ上げるたびに、「何が新しくできるようになったか」「どうやって確認したか」「まだ何が課題か」を README に書きましょう。
このページを終えたら、この evidence card を残します。
- プロジェクト目標
- CLI、スクレイパー、API、AI API 呼び出し、または統合 Python ワークショップの対象
- 実行コマンド
- プロジェクトの起動に使った正確なコマンド
- 成果物
- 出力ファイル、API 応答、JSON レコード、スクリーンショット、または README メモ
- 失敗確認
- 依存関係、ネットワーク、パース、ルート、入力検証、または API キーの問題
- 期待される成果
- 実行結果と1件の失敗例を含む再現可能なミニプロジェクトフォルダ