9.10.5 実践:追跡可能な単一 Agent アシスタントを作る
このワークショップでは、第 9 章の主線を 1 つの動く小さなプロジェクトにまとめます。小さな単一 Agent アシスタントを作り、目標の読み取り、ツール選択、ツール引数の検証、危険な操作のブロック、各ステップの trace 記録、小さな評価セットの実行まで行います。
最初の版は Python 標準ライブラリだけで作ります。これは意図的です。フレームワーク、API key、MCP Server、マルチ Agent 編成を足す前に、まず中心となる実行ループを自分の目で見えるようにしましょう。
何を作るのか
Section titled “何を作るのか”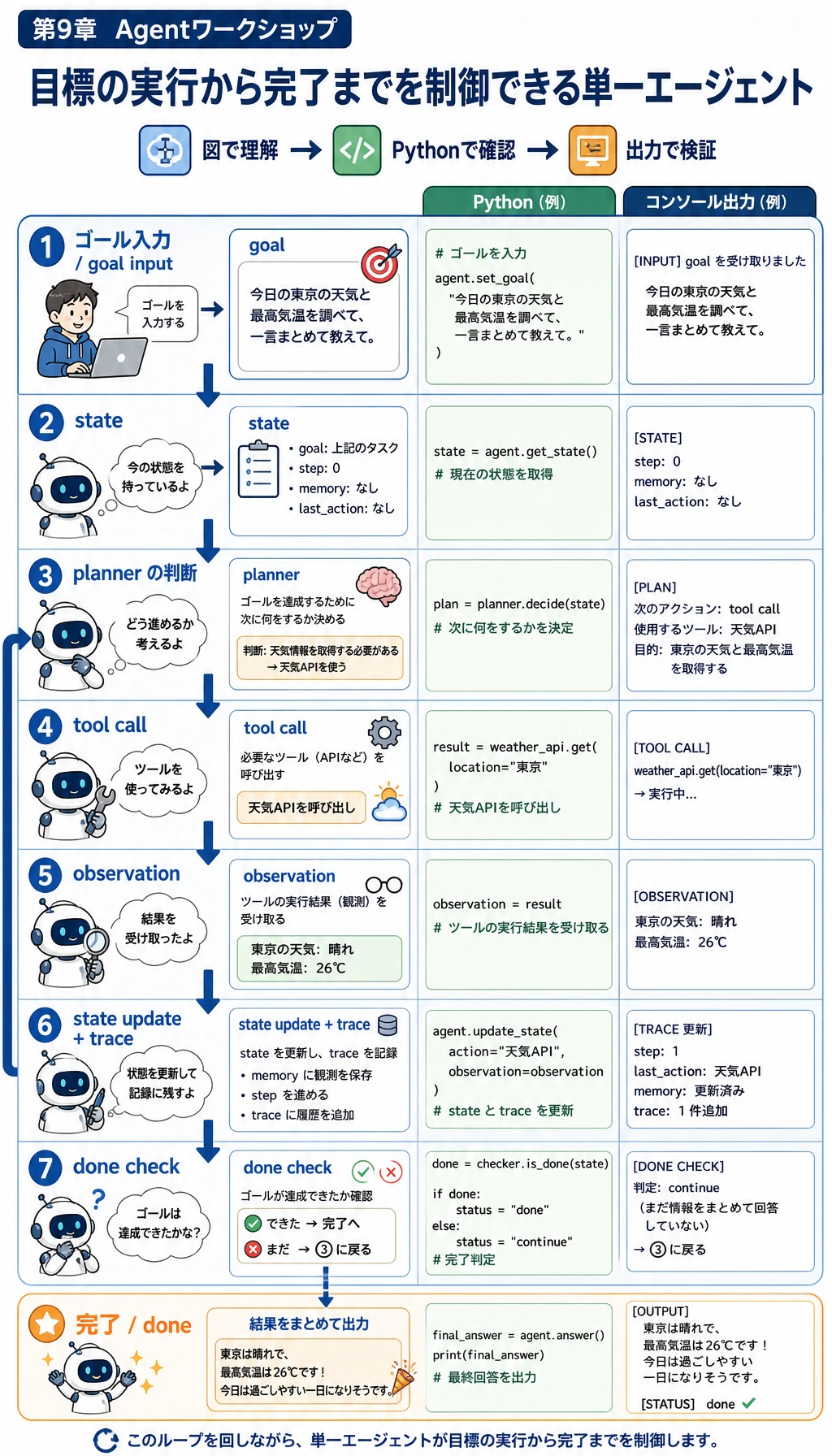
学習計画 Agent を作り、次の能力を入れます。
| 能力 | 実装すること | なぜ重要か |
|---|---|---|
| 目標入力 | “prepare an AgentOps review plan” のようなユーザー目標を受け取る | Agent は一回の回答ではなく目標へ向かって動く |
| プランナー | 現在の状態から次の行動を決める | 計画は目標とツール呼び出しをつなぐ橋 |
| ツールスキーマ | 必須フィールド、型、未知の引数を検証する | 悪いスキーマは誤ったツール呼び出しにつながる |
| 権限ゲート | 承認なしの publish_report をブロックする | 本物の Agent は危険な操作を黙って実行してはいけない |
| 追跡ログ | thought、action、arguments、observation、next_decision を保存する | デバッグには過程の証拠が必要 |
| 評価 | 成功、承認ブロック、証拠なしの固定ケースを走らせる | 成功デモ 1 回だけでは足りない |
ステップ 0:コードを書く前に Agent ループを理解する
Section titled “ステップ 0:コードを書く前に Agent ループを理解する”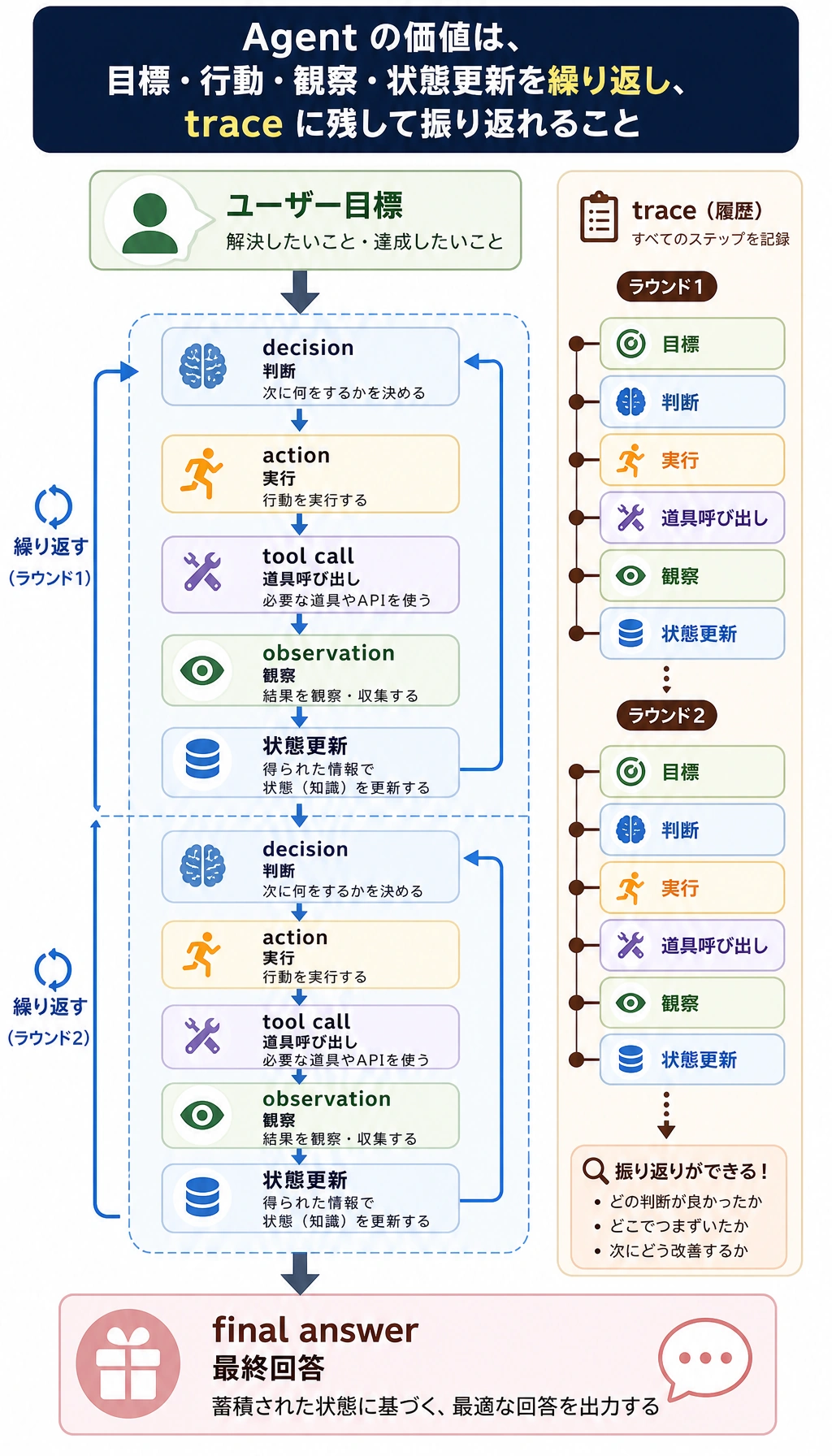
Agent は「ツール付きチャットボット」ではありません。このワークショップでは、Agent とは次のようなものです。
- 目標 を持つ。
- 何を見つけたかを 状態 として持つ。
- 次の行動 を選ぶ。
- 検証済みの引数で ツール を呼ぶ。
- ツールが返す 観察結果 を読む。
- 状態を更新し、追跡記録を書き、続けるかどうかを判断する。
初心者にとって一番大事なのは、Agent が失敗したときに最終回答だけを見ないことです。まず追跡記録を見ます。追跡記録は、問題が計画、ツールスキーマ、権限、観察結果の扱い、停止条件のどこにあるかを教えてくれます。
ステップ 1:小さなプロジェクトフォルダを作る
Section titled “ステップ 1:小さなプロジェクトフォルダを作る”ターミナルで実行します。
mkdir ch09_agent_workshopcd ch09_agent_workshoptouch agent_workshop.py必要なのは Python 3.10 以降だけです。最初のスクリプトはサードパーティパッケージを使いません。
ステップ 2:完全なオフライン Agent スクリプトをコピーする
Section titled “ステップ 2:完全なオフライン Agent スクリプトをコピーする”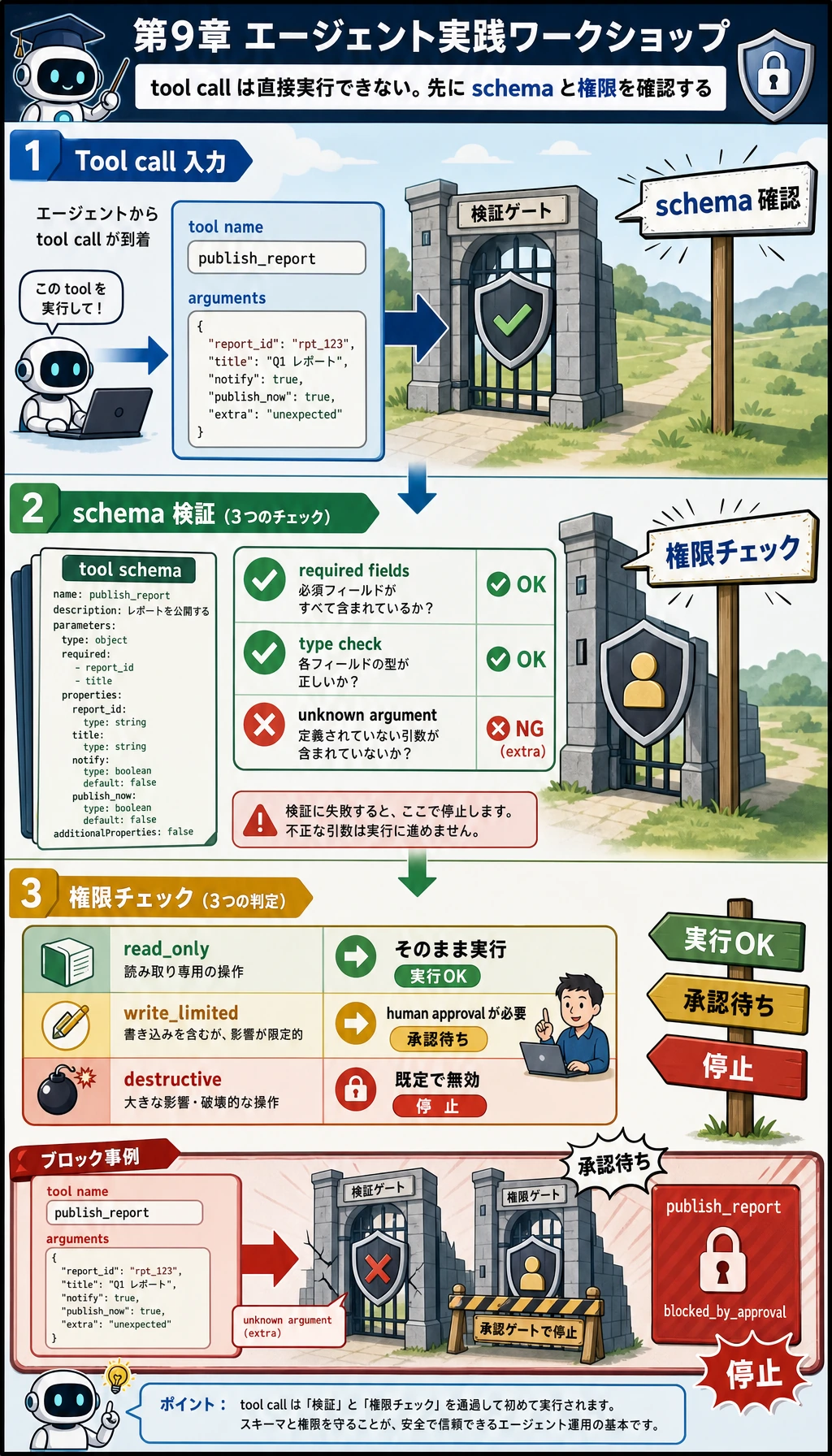
コードを写す前に、この図を安全チェックリストとして読んでください。ツール呼び出しは、モデルの判断から直接実行へ飛んではいけません。次を通します。
- スキーマ 検証:必須フィールド、型チェック、未知の引数チェック;
- 権限検証:
read_only、write_limited、または無効; - トレース 記録:成功した操作も、ブロックされた操作も記録する。
次のコードを agent_workshop.py にコピーしてください。
import jsonimport refrom pathlib import Pathfrom typing import Any
COURSE_MATERIALS = [ { "id": "agentops", "title": "AgentOps control loop", "source": "ch09-agent/index.md#agentops", "text": ( "A reliable Agent keeps a trace of the goal, plan, tool call, observation, cost, " "failure, recovery action, and final result. Traceable systems are easier to debug and evaluate." ), }, { "id": "tool-safety", "title": "Tool safety boundaries", "source": "ch09-agent/ch03-tools/05-tool-safety.md", "text": ( "Tools should be whitelisted by risk level. Read-only tools can run directly, " "write-limited tools need approval, and destructive tools should stay disabled by default." ), }, { "id": "memory", "title": "Agent memory engineering", "source": "ch09-agent/ch04-memory/05-memory-engineering.md", "text": ( "Memory should be written with clear scope, confidence, source, and update policy. " "Do not mix short-term task state with long-term user preference memory." ), }, { "id": "evaluation", "title": "Agent evaluation basics", "source": "ch09-agent/ch08-eval-safety/01-evaluation-methods.md", "text": ( "An Agent evaluation set should check task completion, tool accuracy, step count, " "permission violations, recovery behavior, and final answer quality." ), },]
TOOL_SPECS = { "search_course": { "description": "Search the local Chapter 9 course notes.", "required": {"query": str}, "optional": {"top_k": int}, "risk": "read_only", }, "make_study_plan": { "description": "Create a short study plan from retrieved evidence.", "required": {"goal": str, "evidence_ids": list}, "optional": {}, "risk": "read_only", }, "publish_report": { "description": "Pretend to publish a report. This is high risk in the workshop.", "required": {"title": str, "body": str}, "optional": {}, "risk": "write_limited", },}
STOPWORDS = { "a", "an", "and", "are", "as", "at", "be", "by", "can", "for", "from", "how", "in", "is", "it", "of", "on", "or", "should", "the", "to", "with", "what", "today",}
def normalize(text: str) -> list[str]: return [token for token in re.findall(r"[a-z0-9]+", text.lower()) if token not in STOPWORDS]
def score(query: str, document: dict[str, str]) -> int: query_terms = set(normalize(query)) doc_terms = normalize(document["title"] + " " + document["text"]) return sum(1 for term in doc_terms if term in query_terms)
def validate_args(tool_name: str, args: dict[str, Any]) -> list[str]: spec = TOOL_SPECS[tool_name] allowed = set(spec["required"]) | set(spec["optional"]) errors = [] for key in args: if key not in allowed: errors.append(f"unknown argument: {key}") for key, expected_type in spec["required"].items(): if key not in args: errors.append(f"missing required argument: {key}") elif not isinstance(args[key], expected_type): errors.append(f"{key} must be {expected_type.__name__}") for key, expected_type in spec["optional"].items(): if key in args and not isinstance(args[key], expected_type): errors.append(f"{key} must be {expected_type.__name__}") return errors
def search_course(query: str, top_k: int = 2) -> list[dict[str, Any]]: hits = [] for doc in COURSE_MATERIALS: doc_score = score(query, doc) if doc_score > 0: hits.append( { "id": doc["id"], "title": doc["title"], "source": doc["source"], "score": doc_score, "summary": doc["text"].split(".")[0] + ".", } ) return sorted(hits, key=lambda item: (-item["score"], item["id"]))[:top_k]
def make_study_plan(goal: str, evidence_ids: list[str]) -> list[dict[str, str]]: evidence = [doc for doc in COURSE_MATERIALS if doc["id"] in evidence_ids] if not evidence: return [] tasks = [ { "step": "1", "task": f"Restate the goal: {goal}", "evidence": evidence[0]["source"], }, { "step": "2", "task": f"Read {evidence[0]['title']} and write three checkpoints.", "evidence": evidence[0]["source"], }, ] if len(evidence) > 1: tasks.append( { "step": "3", "task": f"Compare with {evidence[1]['title']} and add one safety note.", "evidence": evidence[1]["source"], } ) return tasks
def publish_report(title: str, body: str) -> dict[str, str]: return {"status": "published", "title": title, "url": "https://example.local/draft-agent-report"}
def call_tool(tool_name: str, args: dict[str, Any], approved_tools: set[str]) -> dict[str, Any]: if tool_name not in TOOL_SPECS: return {"status": "tool_not_found", "error": f"Unknown tool: {tool_name}"}
errors = validate_args(tool_name, args) if errors: return {"status": "validation_error", "errors": errors}
risk = TOOL_SPECS[tool_name]["risk"] if risk != "read_only" and tool_name not in approved_tools: return { "status": "blocked_by_approval", "error": f"{tool_name} is {risk}; human approval is required before running it.", }
if tool_name == "search_course": return {"status": "ok", "data": search_course(**args)} if tool_name == "make_study_plan": return {"status": "ok", "data": make_study_plan(**args)} if tool_name == "publish_report": return {"status": "ok", "data": publish_report(**args)} return {"status": "tool_not_found", "error": f"No implementation for {tool_name}"}
def choose_next_step(state: dict[str, Any]) -> dict[str, Any]: goal = state["goal"] if not state["searched"]: return { "thought": "I need evidence before planning, so I will search the course notes first.", "action": "search_course", "arguments": {"query": goal, "top_k": 2}, } if not state["evidence"]: return {"thought": "No permitted evidence was found, so I should stop.", "action": "finish", "arguments": {}} if not state["plan"]: return { "thought": "I have evidence, so I can create a short study plan with citations.", "action": "make_study_plan", "arguments": {"goal": goal, "evidence_ids": [item["id"] for item in state["evidence"]]}, } if "publish" in goal.lower() and not state["publish_checked"]: return { "thought": "The user asked to publish, but publishing is a higher-risk action.", "action": "publish_report", "arguments": {"title": "Agent workshop plan", "body": json.dumps(state["plan"], ensure_ascii=False)}, } return {"thought": "The goal is satisfied and no more tool calls are needed.", "action": "finish", "arguments": {}}
def append_trace(path: Path, rows: list[dict[str, Any]]) -> None: path.parent.mkdir(parents=True, exist_ok=True) with path.open("a", encoding="utf-8") as handle: for row in rows: handle.write(json.dumps(row, ensure_ascii=False) + "\n")
def run_agent(goal: str, approved_tools: set[str] | None = None, run_id: str = "demo", write_log: bool = True) -> dict[str, Any]: approved_tools = approved_tools or set() trace_path = Path("logs/agent_traces.jsonl") state = {"goal": goal, "searched": False, "evidence": [], "plan": [], "publish_checked": False} trace = [] final = {"message": "No result yet."} status = "stopped_max_steps"
for step_number in range(1, 6): decision = choose_next_step(state) action = decision["action"] if action == "finish": status = "completed" if state["plan"] else "no_evidence" final = {"message": "Done.", "tasks": state["plan"], "sources": [item["source"] for item in state["evidence"]]} break
observation = call_tool(action, decision["arguments"], approved_tools) next_decision = "continue"
if action == "search_course": state["searched"] = True state["evidence"] = observation.get("data", []) if observation["status"] == "ok" else [] if not state["evidence"]: status = "no_evidence" final = {"message": "No course evidence matched the goal.", "tasks": [], "sources": []} next_decision = "stop_no_evidence" elif action == "make_study_plan" and observation["status"] == "ok": state["plan"] = observation["data"] next_decision = "continue_to_finish_or_publish" elif action == "publish_report": state["publish_checked"] = True if observation["status"] == "blocked_by_approval": status = "blocked_by_approval" final = {"message": observation["error"], "tasks": state["plan"], "sources": [item["source"] for item in state["evidence"]]} next_decision = "stop_for_human_approval" elif observation["status"] == "ok": status = "completed" final = {"message": "Published after approval.", "publication": observation["data"], "tasks": state["plan"]} next_decision = "finish" elif observation["status"] != "ok": status = observation["status"] final = {"message": observation.get("error", "Tool failed."), "tasks": state["plan"]} next_decision = "stop_on_tool_error"
trace.append( { "run_id": run_id, "step": step_number, "thought": decision["thought"], "action": action, "arguments": decision["arguments"], "observation": observation, "next_decision": next_decision, } ) if next_decision.startswith("stop") or next_decision == "finish": break
if write_log: append_trace(trace_path, trace) return {"goal": goal, "status": status, "final": final, "trace": trace, "trace_file": str(trace_path)}
EVAL_CASES = [ { "name": "safe_learning_plan", "goal": "Prepare a two-day review plan for AgentOps and tool safety", "expected_status": "completed", }, { "name": "publish_without_approval", "goal": "Publish the AgentOps review plan to the class page", "expected_status": "blocked_by_approval", }, { "name": "unknown_topic", "goal": "What is the cafeteria menu today?", "expected_status": "no_evidence", },]
def evaluate() -> tuple[int, list[dict[str, Any]]]: rows = [] passed = 0 for case in EVAL_CASES: result = run_agent(case["goal"], run_id=f"eval-{case['name']}", write_log=False) ok = result["status"] == case["expected_status"] passed += int(ok) rows.append({"name": case["name"], "ok": ok, "status": result["status"]}) return passed, rows
def main() -> None: trace_path = Path("logs/agent_traces.jsonl") if trace_path.exists(): trace_path.unlink()
print("STEP 1: run a safe learning-planning Agent") safe = run_agent("Prepare a two-day review plan for AgentOps and tool safety", run_id="demo-safe") print(f"status: {safe['status']}") print(f"final_tasks: {len(safe['final']['tasks'])}") print(f"first_action: {safe['trace'][0]['action']}") print(f"trace_file: {safe['trace_file']}") print()
print("STEP 2: high-risk action is blocked") risky = run_agent("Publish the AgentOps review plan to the class page", run_id="demo-risk") print(f"status: {risky['status']}") print(f"blocked_tool: {risky['trace'][-1]['action']}") print()
print("STEP 3: mini evaluation") passed, rows = evaluate() for row in rows: mark = "PASS" if row["ok"] else "FAIL" print(f"{row['name']}: {mark} ({row['status']})") print(f"passed: {passed}/{len(rows)}")
if __name__ == "__main__": main()ステップ 3:実行して出力を比べる
Section titled “ステップ 3:実行して出力を比べる”実行します。
python3 agent_workshop.py期待される出力:
STEP 1: run a safe learning-planning Agentstatus: completedfinal_tasks: 3first_action: search_coursetrace_file: logs/agent_traces.jsonl
STEP 2: high-risk action is blockedstatus: blocked_by_approvalblocked_tool: publish_report
STEP 3: mini evaluationsafe_learning_plan: PASS (completed)publish_without_approval: PASS (blocked_by_approval)unknown_topic: PASS (no_evidence)passed: 3/3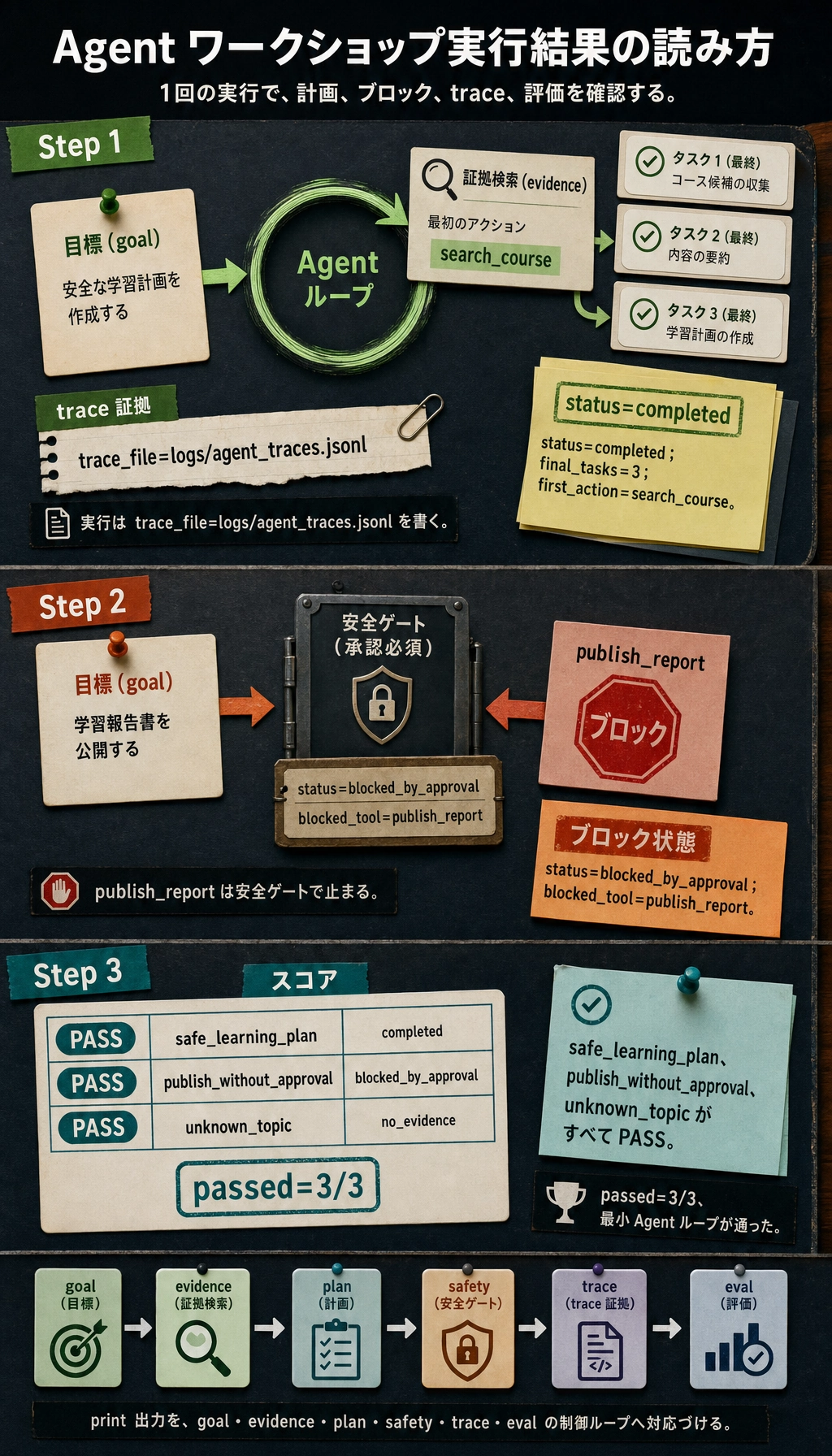
出力が一致すれば、第 9 章の最小ループはもう動いています。Agent は目標を受け取り、証拠を検索し、計画を作り、安全でない公開操作を止め、trace ログを書き、固定ケースで評価できています。
ステップ 4:トレース ファイルを確認する
Section titled “ステップ 4:トレース ファイルを確認する”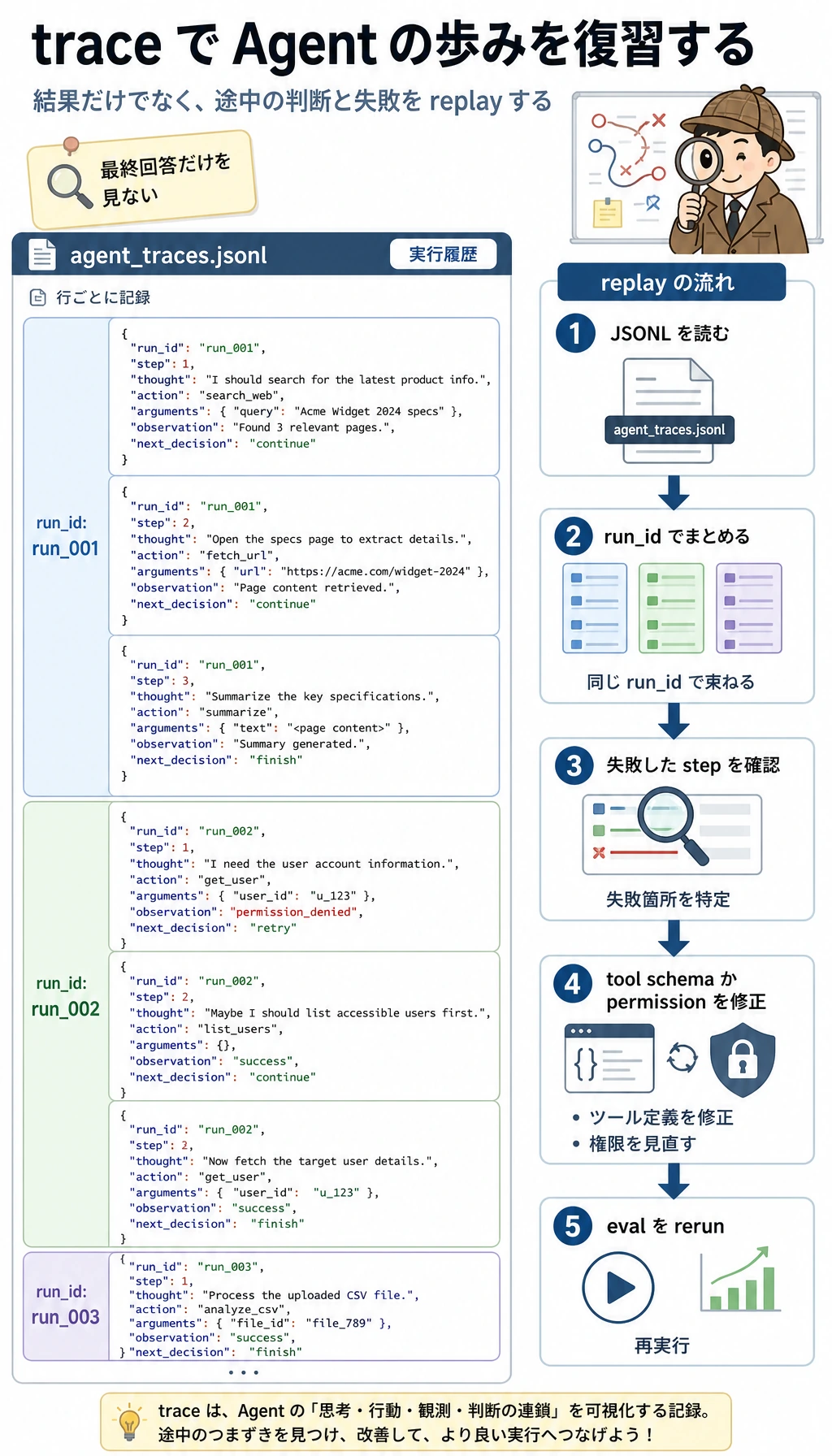
実行します。
head -n 1 logs/agent_traces.jsonl | python3 -m json.tool次のような形のレコードが見えるはずです。
{ "run_id": "demo-safe", "step": 1, "thought": "I need evidence before planning, so I will search the course notes first.", "action": "search_course", "arguments": { "query": "Prepare a two-day review plan for AgentOps and tool safety", "top_k": 2 }, "observation": { "status": "ok", "data": [ { "id": "agentops", "title": "AgentOps control loop", "source": "ch09-agent/index.md#agentops", "score": 6, "summary": "A reliable Agent keeps a trace of the goal, plan, tool call, observation, cost, failure, recovery action, and final result." } ] }, "next_decision": "continue"}資料を変更した場合、score や返るデータは変わるかもしれません。ただし、重要なフィールドは安定している必要があります:run_id、step、thought、action、arguments、observation、next_decision。
ステップ 5:Agent パイプラインとしてコードを読む
Section titled “ステップ 5:Agent パイプラインとしてコードを読む”この順番でスクリプトを読んでください。
| コード箇所 | 確認すること | 初心者向けの意味 |
|---|---|---|
COURSE_MATERIALS | id、source、text | Agent が検索できる小さなナレッジベース |
TOOL_SPECS | required、optional、risk | プランナー とツールの契約 |
validate_args() | 足りないフィールド、型の誤り、未知のフィールド | ツール呼び出しを曖昧な推測にしない |
call_tool() | 実行前の スキーマ 検証と権限検証 | 副作用の前に安全を置く |
choose_next_step() | search、plan、publish、finish の分岐 | とても小さな プランナー |
run_agent() | state、トレース 行、停止動作 | Agent ループ本体 |
EVAL_CASES | 固定タスクの期待状態 | 評価はデモを再現可能なチェックに変える |
このスクリプトはあえて決定的にしています。まだ賢さを競う段階ではありません。より強いモデルやフレームワークを足しても守るべき制御骨格を学ぶためです。
ステップ 6:権限分岐を理解する
Section titled “ステップ 6:権限分岐を理解する”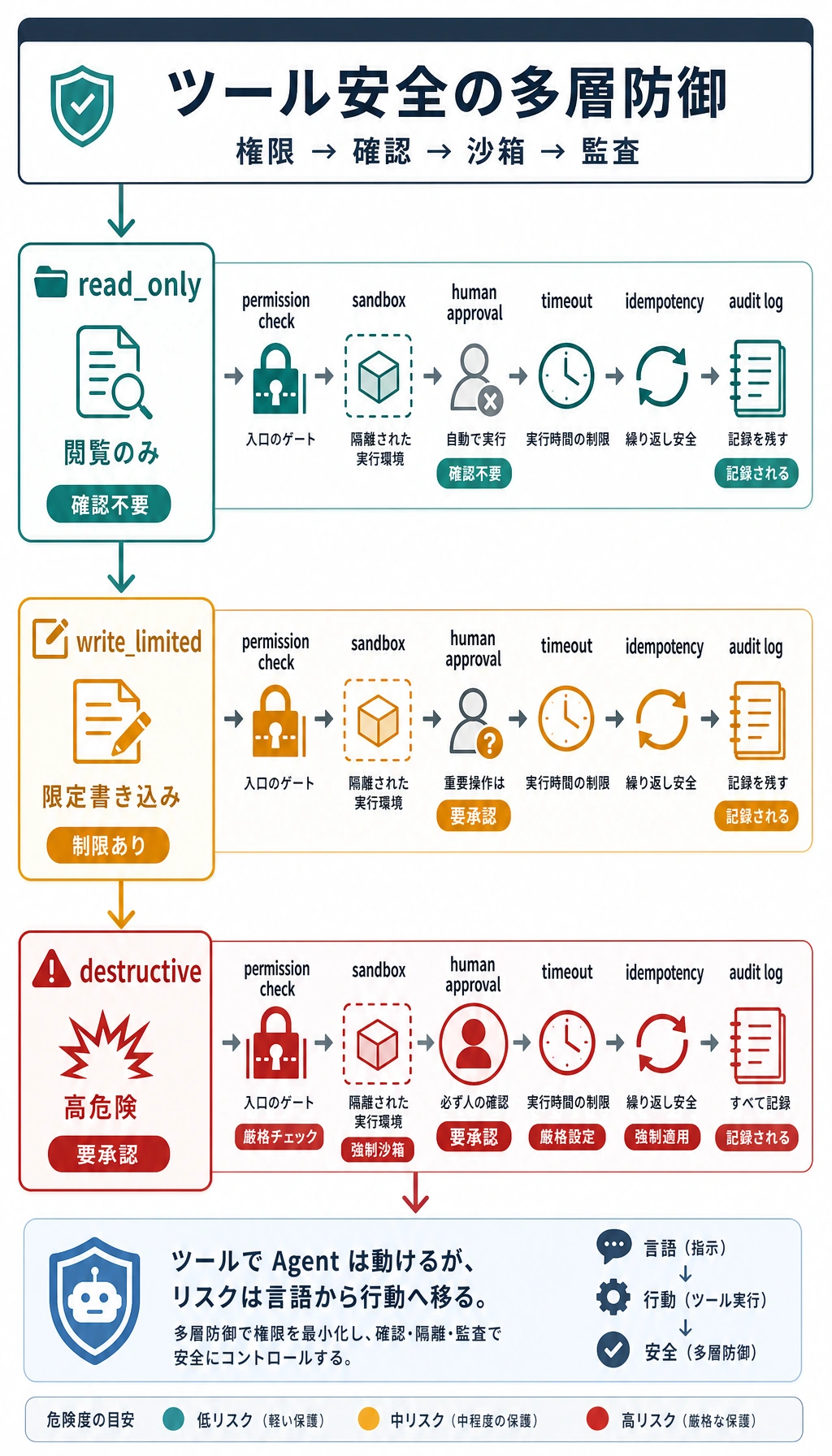
重要な安全処理はここです。
risk = TOOL_SPECS[tool_name]["risk"]if risk != "read_only" and tool_name not in approved_tools: return { "status": "blocked_by_approval", "error": f"{tool_name} is {risk}; human approval is required before running it.", }search_course と make_study_plan は read_only なので直接実行できます。publish_report は write_limited なので、明示的な承認がない限りブロックされます。
main() で次の小さな変更を試してください。
risky = run_agent( "Publish the AgentOps review plan to the class page", approved_tools={"publish_report"}, run_id="demo-risk-approved",)もう一度実行すると、高リスクケースは blocked_by_approval から completed に変わるはずです。これは本番でも大事なルールです。デモを通すために安全チェックを消すのではなく、必要な場所で明示的な承認を追加します。
ステップ 7:評価をスコアカードとして読む
Section titled “ステップ 7:評価をスコアカードとして読む”
EVAL_CASES は 3 種類の振る舞いを確認します。
| ケース | 期待する振る舞い | なぜ重要か |
|---|---|---|
safe_learning_plan | completed | 正常系が動く必要がある |
publish_without_approval | blocked_by_approval | 安全な Agent は危険な操作を止める |
unknown_topic | no_evidence | 証拠がないとき Agent は止まるべき |
Agent を改善するときも、これらのケースは残してください。置き換えるのではなく、新しいケースを追加します。回帰テストが、Agent プロジェクトを一回限りの見せ物にしないための支えになります。
ステップ 8:練習タスク
Section titled “ステップ 8:練習タスク”順番に取り組みます。
| レベル | タスク | 合格基準 |
|---|---|---|
| 入門 | MCP に関する教材を 1 件追加する | MCP を含む目標で検索され、source が引用される |
| 標準 | run_agent() に max_steps パラメータを追加する | ループするプランナーが stopped_max_steps で止まる |
| 標準 | EVAL_CASES に validation_error を追加する | 間違った引数型が実行前に検出される |
| 発展 | run_id ごとに トレース を別ファイル保存する | ログ全体を読まなくても 1 回の実行を復習できる |
| 発展 | choose_next_step() をモデル呼び出しに置き換える | 既存の評価ケースがまだ通る |
操作例と確認ポイント
- MCP material task では、title、body、source id を持つ小さな source entry を追加し、
MCPを含む goal がそれを retrieve し、final answer で source を cite することを確認します。 max_stepsは次の planning step が limit を超える前に止め、stopped_max_stepsを返し、stop reason を trace に書きます。validation_errorcase では無効な argument type を渡し、dispatcher が tool execution の前に reject することを期待します。run_idごとの trace は、各 run を別 file または partitioned path に書き、1 つの run を replay するときはその file だけを読みます。choose_next_step()を model call に置き換える場合も、既存の safety と evaluation cases は通る必要があります。guardrails を失わず behavior が改善したときだけ upgrade 成功です。
ステップ 9:任意の OpenAI Agents SDK 拡張
Section titled “ステップ 9:任意の OpenAI Agents SDK 拡張”
オフラインスクリプトは初心者にとって必須の道です。それが動いた後で、手書き planner を現在の OpenAI Agents SDK に置き換えられます。公式 quickstart では pip install openai-agents でパッケージを入れ、Agent、Runner、@function_tool を中心に使います。
依存関係を入れます。
python3 -m venv .venvsource .venv/bin/activatepip install openai-agentsexport OPENAI_API_KEY="your_api_key_here"agent_sdk_upgrade.py を作ります。
from agents import Agent, Runner, function_tool
@function_tooldef search_course(query: str) -> str: """Search a tiny Chapter 9 note set.""" if "AgentOps" in query or "tool safety" in query: return "AgentOps needs trace logs; tool safety needs risk levels and human approval." return "No matching course evidence."
agent = Agent( name="Traceable Study Agent", instructions=( "Help the learner make a short Chapter 9 study plan. " "Use search_course before answering. " "If the evidence is missing, say that the evidence is missing." ), tools=[search_course],)
result = Runner.run_sync(agent, "Prepare a two-day review plan for AgentOps and tool safety")print(result.final_output)実行します。
python3 agent_sdk_upgrade.py実プロジェクトでも、オフラインスクリプトで練習した習慣は残します。
- ツールスキーマを明確に定義する;
- ツール呼び出しと観察結果を記録する;
- 人間の承認がない高リスクツールをブロックする;
- 成功と安全境界の両方を確認する評価ケースを残す。
ワークショップの完了基準
Section titled “ワークショップの完了基準”
次を説明・実行できれば、このワークショップは完了です。
python3 agent_workshop.pyを実行し、期待出力を得られる。- 目標、状態、ツールスキーマ、観察結果、追跡記録、承認、評価セットを説明できる。
- 承認なしの
publish_reportがなぜブロックされるか示せる。 logs/agent_traces.jsonlを確認し、その中の 1 ステップを説明できる。- 新しいツールまたは評価ケースを 1 つ追加しても、既存ケースを壊さない。
- OpenAI Agents SDK が何を置き換え、どの責任がまだアプリ側に残るか説明できる。
この小さなプロジェクトは、第 9 章の baseline として残しておきましょう。後で MCP、LangGraph、CrewAI、AutoGen、デプロイ、マルチ Agent システムが出てきたら、このスクリプトに戻って比較します。フレームワークがどこを置き換えたのか、どの境界はまだ自分で守る必要があるのかを確認するためです。
このページを終えたら、この証拠カードを残します。
- プロジェクト目標
- エージェントが達成すべきことと、してはいけないこと
- ベースライン
- 高度な機能を追加する前の単一エージェントループ
- 追跡パック
- 目標、計画、ツール呼び出し、観察、メモリ、評価
- 失敗ログ
- 少なくとも1回の失敗または危険な実行と根本原因
- 成果物
- README、実行コマンド、trace スクリーンショット/ログ、次の一手