5.3.4 異常検知
この節では、実用的なアラート実験を 1 つ作ります。
- 正常点と合成異常点を作る;
- Isolation Forest の
contaminationを調整する; - 異常スコアを確認する;
- Isolation Forest と LOF を比較する;
- precision、recall、偽陽性、偽陰性をプロダクト上のトレードオフとして読む。
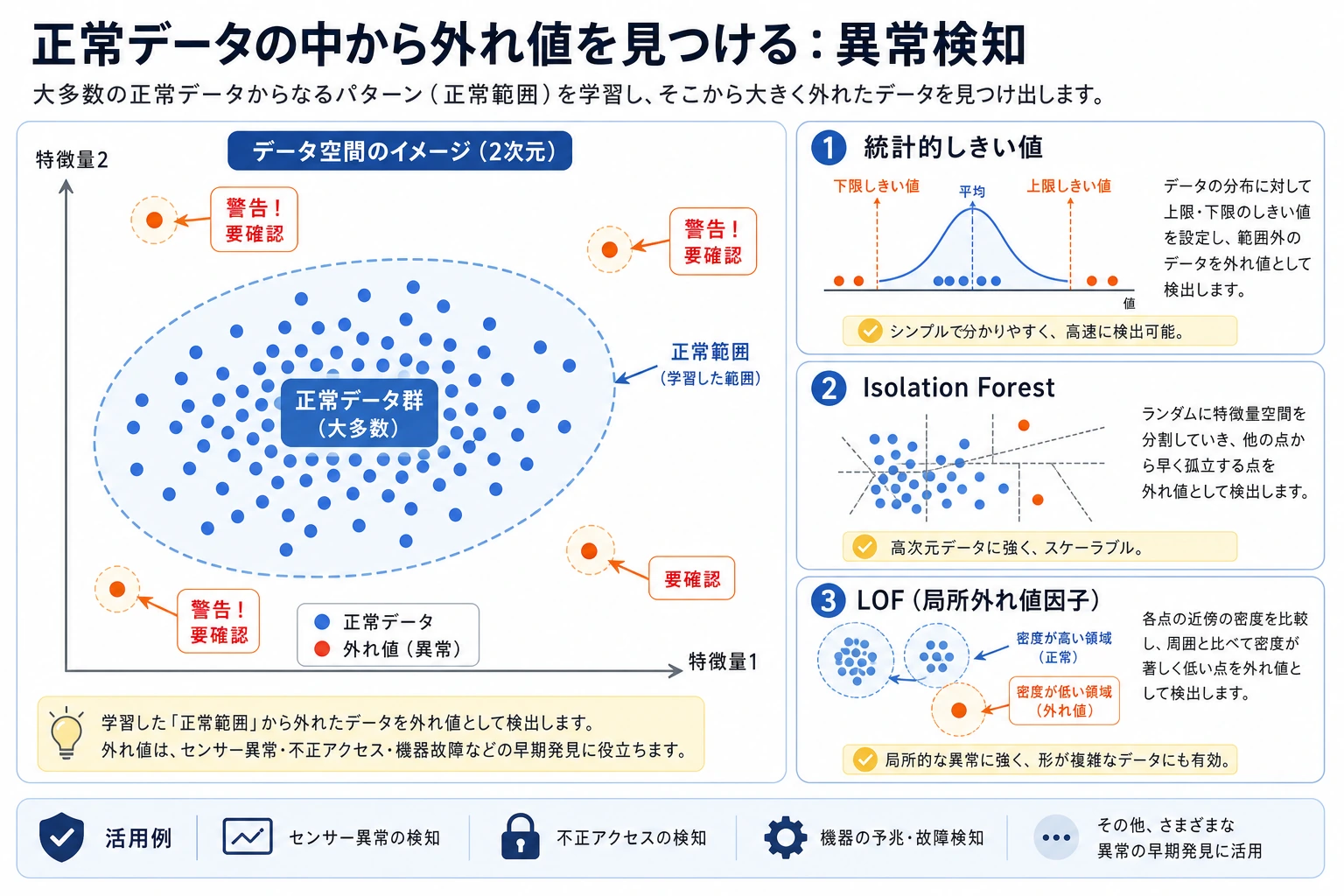
まず図を見てください。異常検知の中心は、何をアラートにするか、そして各ミスがどれくらい高いかです。
| 用語 | 実用上の意味 |
|---|---|
anomaly | 通常パターンに合わないサンプル |
outlier | 多くの点から離れている点 |
contamination | 期待される異常割合。しきい値の手がかりになる |
score_samples | モデルスコア。Isolation Forest では低いほど異常 |
false positive | 正常サンプルを疑わしいと誤検知すること |
false negative | 本当の異常を見逃すこと |
IsolationForest | 木ベースの手法。異常点をすばやく隔離する |
LOF | Local Outlier Factor。各点周辺の局所密度を比較する |
セットアップ
Section titled “セットアップ”python -m pip install -U scikit-learn numpyこの実験では、学習のために合成ラベルを使います。実際の異常検知では、ラベルがない、遅れて届く、不完全であることがよくあります。
完全な実験を実行する
Section titled “完全な実験を実行する”anomaly_lab.py を作成します。
import numpy as npfrom sklearn.datasets import make_blobsfrom sklearn.ensemble import IsolationForestfrom sklearn.metrics import confusion_matrix, f1_score, precision_score, recall_scorefrom sklearn.neighbors import LocalOutlierFactorfrom sklearn.preprocessing import StandardScaler
normal, _ = make_blobs(n_samples=360, centers=2, cluster_std=0.75, random_state=42)rng = np.random.default_rng(42)outliers = rng.uniform(low=-8, high=8, size=(24, 2))X = np.vstack([normal, outliers])y_true = np.array([0] * len(normal) + [1] * len(outliers)) # 1 means anomalyX_scaled = StandardScaler().fit_transform(X)
print("isolation_forest_contamination_lab")for contamination in [0.03, 0.06, 0.12]: model = IsolationForest(contamination=contamination, random_state=42) pred = model.fit_predict(X_scaled) y_pred = (pred == -1).astype(int) tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel() print( f"contamination={contamination:.2f} " f"flagged={int(y_pred.sum())} " f"precision={precision_score(y_true, y_pred):.3f} " f"recall={recall_score(y_true, y_pred):.3f} " f"f1={f1_score(y_true, y_pred):.3f} " f"fp={fp} fn={fn}" )
print("score_inspection")best = IsolationForest(contamination=0.06, random_state=42)best.fit(X_scaled)scores = best.score_samples(X_scaled) # lower means more abnormalorder = np.argsort(scores)[:5]for idx in order: print(f"index={idx:<3} score={scores[idx]:.3f} true_anomaly={bool(y_true[idx])}")
print("lof_comparison")lof = LocalOutlierFactor(n_neighbors=20, contamination=0.06)y_pred = (lof.fit_predict(X_scaled) == -1).astype(int)print( f"flagged={int(y_pred.sum())} " f"precision={precision_score(y_true, y_pred):.3f} " f"recall={recall_score(y_true, y_pred):.3f} " f"f1={f1_score(y_true, y_pred):.3f}")実行します。
python anomaly_lab.py期待される出力:
isolation_forest_contamination_labcontamination=0.03 flagged=12 precision=1.000 recall=0.500 f1=0.667 fp=0 fn=12contamination=0.06 flagged=23 precision=0.826 recall=0.792 f1=0.809 fp=4 fn=5contamination=0.12 flagged=46 precision=0.478 recall=0.917 f1=0.629 fp=24 fn=2score_inspectionindex=371 score=-0.747 true_anomaly=Trueindex=368 score=-0.738 true_anomaly=Trueindex=373 score=-0.734 true_anomaly=Trueindex=364 score=-0.725 true_anomaly=Trueindex=378 score=-0.717 true_anomaly=Truelof_comparisonflagged=23 precision=0.870 recall=0.833 f1=0.851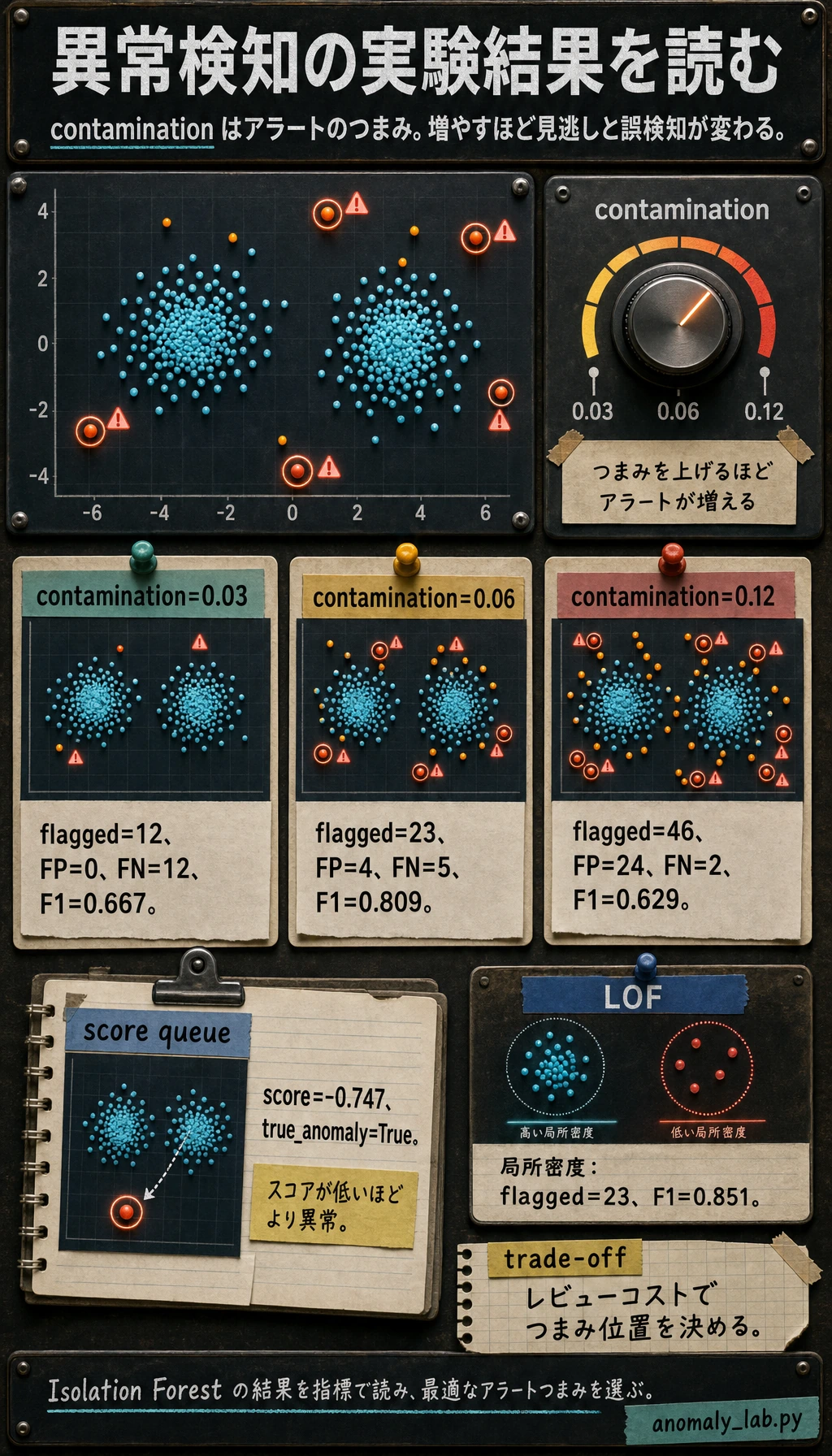
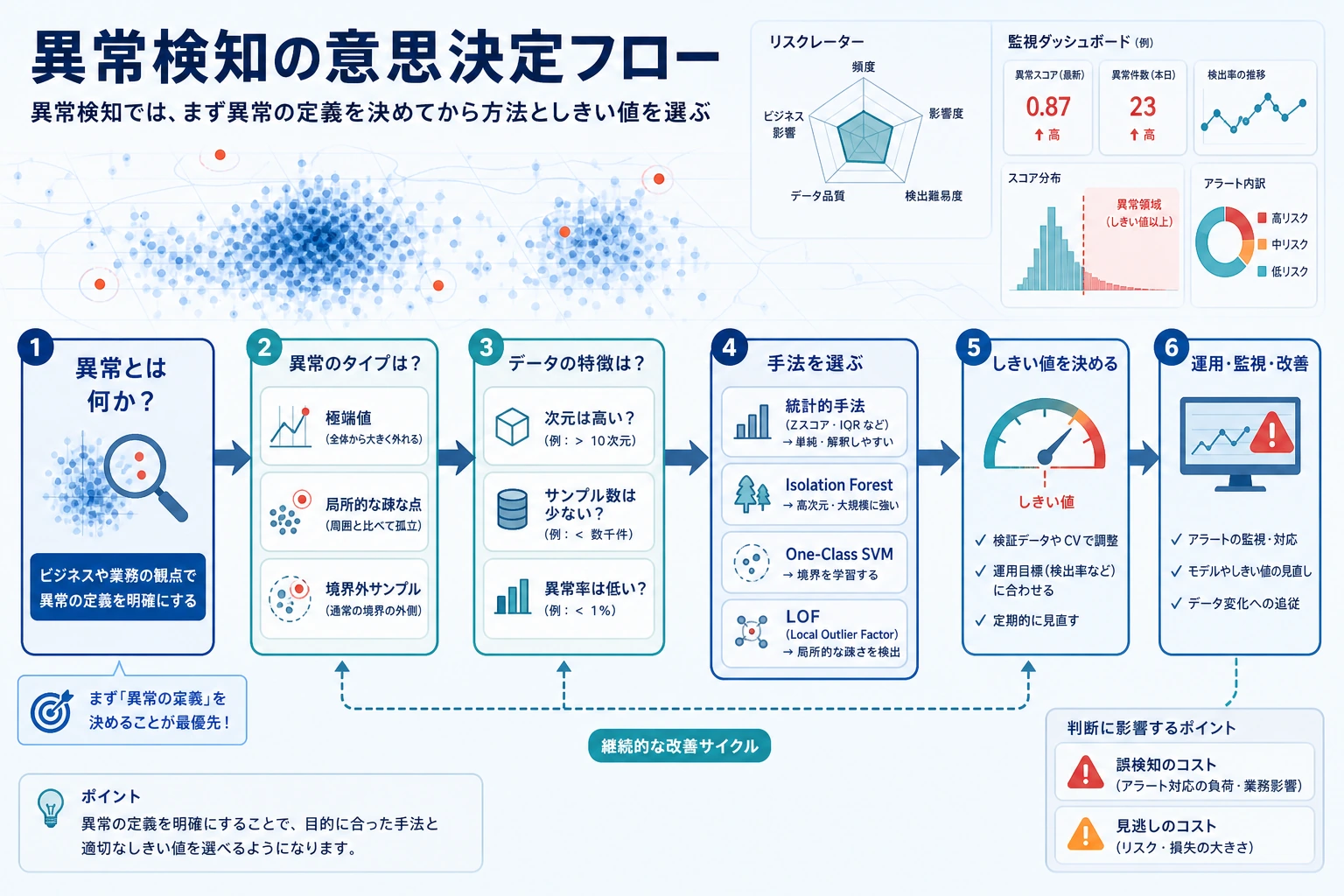
アラートのトレードオフを読む
Section titled “アラートのトレードオフを読む”contamination は、モデルがどれくらいのサンプルをアラートにするかに影響します。
contamination=0.03 flagged=12 precision=1.000 recall=0.500contamination=0.12 flagged=46 precision=0.478 recall=0.917これは分類しきい値と同じトレードオフです。
- contamination が低い:アラートは少なく、偽陽性も少ないが、見逃しが増える;
- contamination が高い:アラートは増え、recall は上がるが、偽陽性も増える。
正しい選択は数学だけでは決まりません。詐欺を 1 件見逃すコストが高ければ、偽陽性を多めに受け入れることがあります。人手レビューが高ければ、少数の高確信アラートを選ぶことがあります。
Isolation Forest
Section titled “Isolation Forest”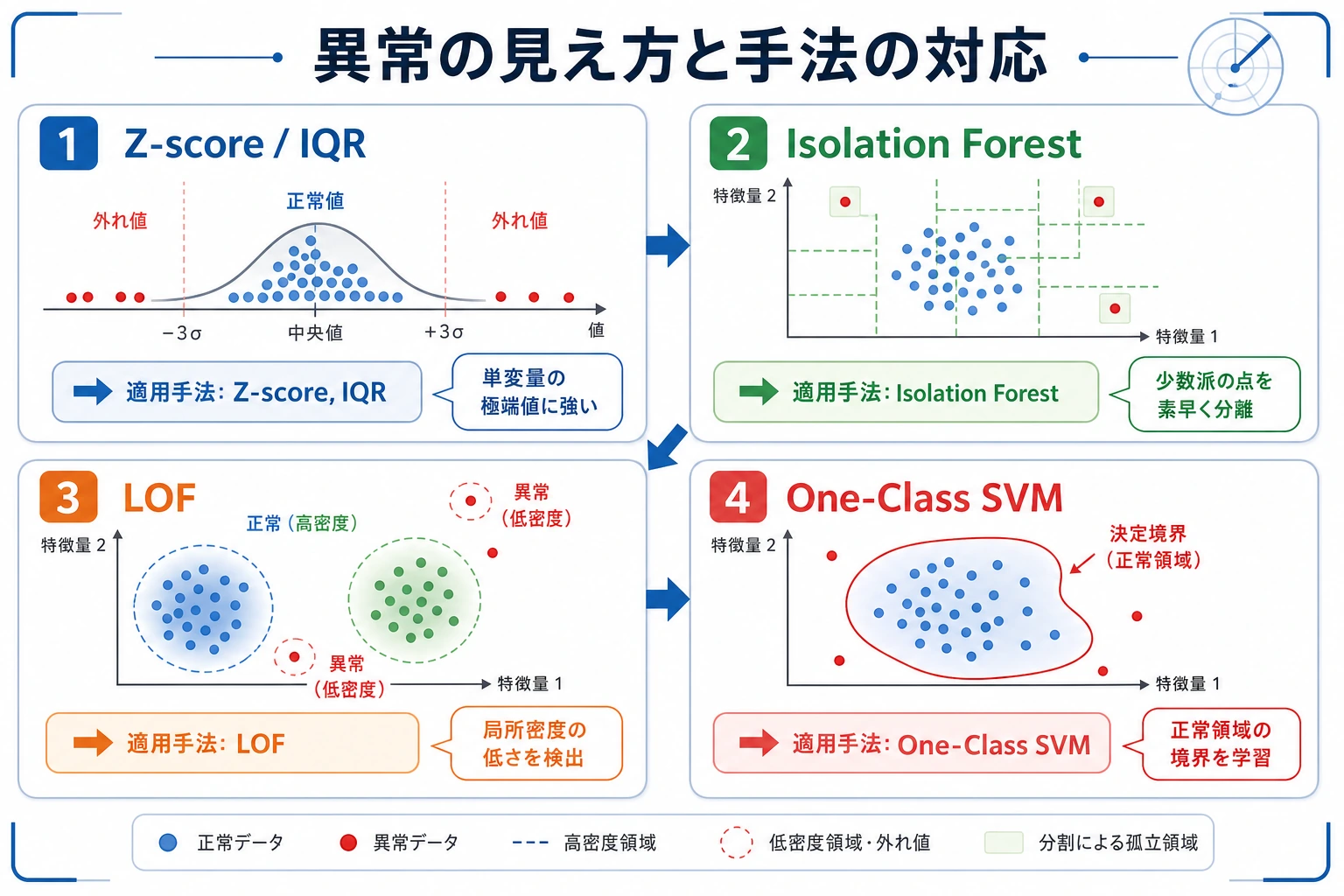
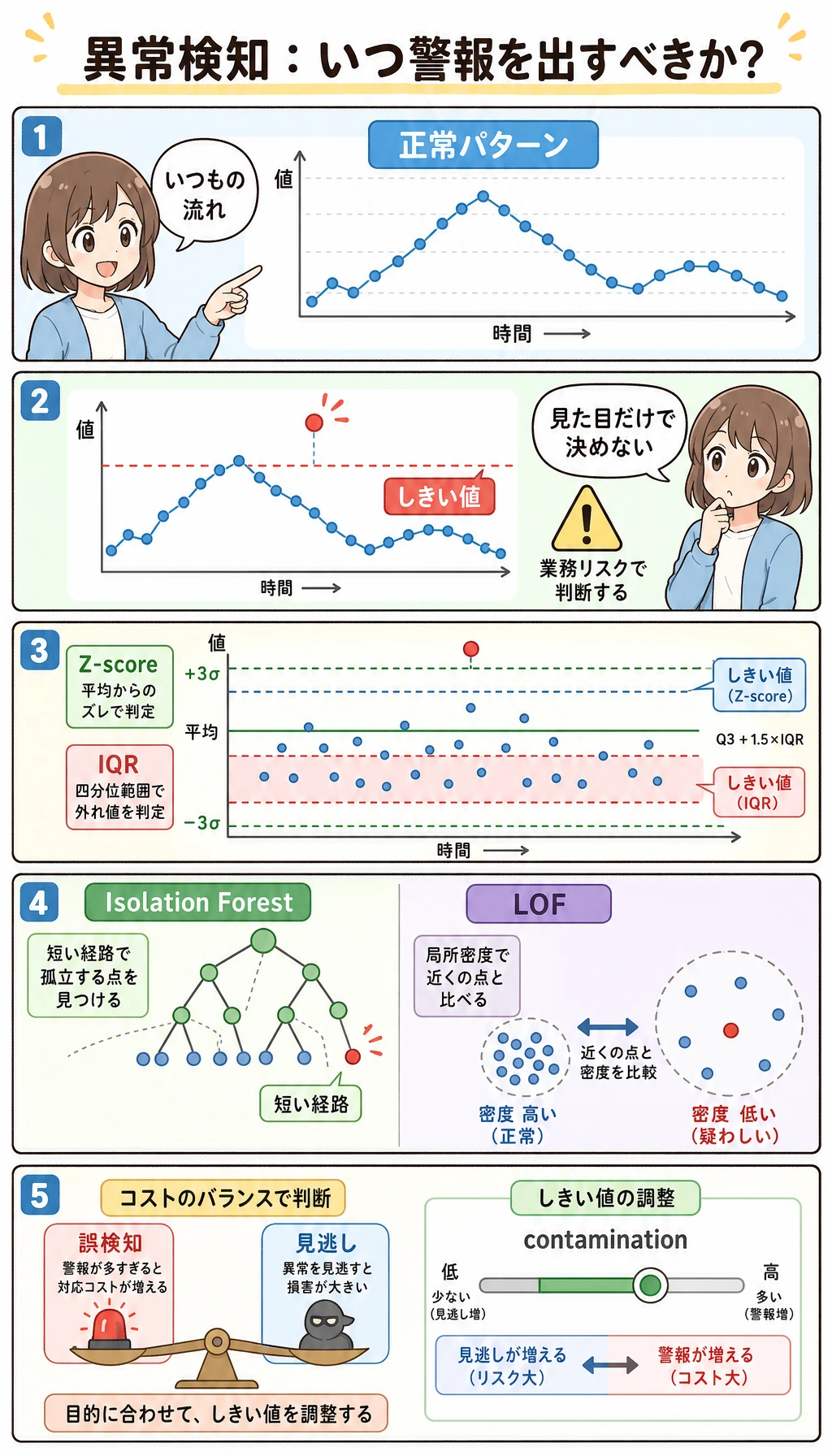
Isolation Forest はランダムな分割木を作ります。異常点は少ない分割で孤立しやすいため、より異常なスコアを受け取ります。
実験では:
scores = best.score_samples(X_scaled)Isolation Forest では、スコアが低いほど異常です。最も疑わしいサンプルは、合成した本当の異常でした。
index=371 score=-0.747 true_anomaly=True単なる yes/no 判定ではなくレビューキューを作りたい場合、スコア順に見るほうが役立ちます。
LOF:局所密度
Section titled “LOF:局所密度”LOF は、ある点の周辺密度と、その近傍点の周辺密度を比べます。全体からは遠くなくても、局所的に変な点を見つけるのに向いています。
この合成実験では:
lof_comparisonflagged=23 precision=0.870 recall=0.833 f1=0.851LOF はここでは Isolation Forest より少し良い結果でした。ただし、常に優れているわけではありません。このデータでは局所密度という仮定が合っていた、という意味です。
方法の選び方
Section titled “方法の選び方”| 状況 | 最初に試すもの | 理由 |
|---|---|---|
| 一般的な表形式異常検知 | Isolation Forest | 速く、頑健で、調整しやすい |
| 局所密度の異常 | LOF | 近傍と比べて不自然な点を見つけられる |
| 単一数値列のチェック | Z-score または IQR | 透明で安い |
| 高次元 embedding | Isolation Forest + 近傍チェック | スコアと近傍を合わせて見る |
| アラート運用が必要 | 任意のモデル + しきい値/レビュー設計 | 運用はスコアと同じくらい重要 |
経験者向け:異常検知は、遅れて届くラベル、レビュー可能件数、アラート疲れ、ドリフト監視を含めて評価します。オフライン F1 が最大のモデルでも、レビュー担当者を圧迫するなら実務では弱い設計です。
このページを終えたら、この evidence card を残します。
- タスク
- clustering、dimensionality reduction、または anomaly detection の目標
- データ表示
- スケーリング済み特徴量、射影、クラスタ、または異常スコア
- 解釈
- このシナリオでグループ、軸、またはアラートが何を意味するか
- 失敗確認
- 任意のクラスタ数、スケーリングの問題、ノイズの多い次元、または誤検知
- 期待される成果
- 解釈と不確実性メモを含む教師なし結果
よくあるトラブル
Section titled “よくあるトラブル”| 症状 | よくある原因 | 修正 |
|---|---|---|
| アラートが多すぎる | contamination またはしきい値が高い | contamination を下げ、レビュー段階を分ける |
| 異常を多く見逃す | しきい値が厳しすぎる | contamination を上げ、弱いルールも足し、recall を監視する |
| 新データでスコア分布が変わる | データ分布のドリフト | スコア分布を継続監視する |
| 尺度の違いだけを異常扱いする | 特徴量をスケーリングしていない | 数値特徴量を先にスケーリングする |
| 評価ラベルがない | 異常検知ではよくある | サンプルレビュー、フィードバック収集、遅延結果の追跡を行う |
- 合成異常点の数を
24から12と48に変えてください。contaminationはどう調整すべきですか? - 外れ値を近づけるために
low=-5, high=5に変えてください。どの手法がより影響を受けますか? - 尺度が非常に大きい 4 つ目の特徴量を追加してください。スケーリング前後で何が変わりますか?
- 固定しきい値ではなく、
score_samples()で並べ替えて上位 20 件を確認してください。 - 3 段階のアラートキューを設計してください:今すぐレビュー、あとでレビュー、無視。
参考実装と解説
contaminationは想定される異常率に近づけます。たとえば12 / total_samplesや48 / total_samplesです。実務では運用上の仮定なので、レビュー結果で調整します。- 外れ値が正常クラスタに近づくと、どの手法も難しくなります。局所密度や境界分離に強く依存する方法は偽陰性が増えやすいため、スコアだけでなく上位サンプルを確認します。
- 尺度の大きい特徴量は、スケーリング前に距離や異常スコアを支配します。スケーリング後は単位の大きさではなくパターン差を見やすくなります。
score_samples()で並べる方法は運用向きです。しきい値が確定していなくても、分析者は最も怪しい候補から確認できます。- たとえば最上位の少数を「今すぐレビュー」、次の層を「あとでレビュー」、残りを「無視」にします。割合はレビュー能力と誤報コストで決めます。
合格チェック
Section titled “合格チェック”次を説明できれば、この節はクリアです。
- 異常検知はアラートワークフローであり、モデルだけではない;
contaminationは偽陽性/偽陰性のトレードオフを変える;- Isolation Forest は不自然な点をすばやく隔離する;
- LOF は局所密度の異常を見つける;
- 単一の yes/no ラベルより、スコア順位を見るほうが役立つことが多い。