2.2.4 関数型プログラミングの基礎
このページを終えたら、この evidence card を残します。
- パターン
- class、exception、file IO、functional pipeline、generator、またはtype hint
- コード成果物
- 最小限の実行可能な例と、現実的なユースケース 1 つ
- 出力
- 印字されたオブジェクト状態、捕捉したエラー、保存したファイル、yieldされた値、または型チェックのメモ
- 失敗確認
- 隠れた変更、副作用を飲み込む例外、ファイルパスの問題、lazy iterator の混同、または誤解を招く注釈
- 期待される成果
- デバッグメモを含む小さな高度Python例
この節の位置づけ
Section titled “この節の位置づけ”この節では、Python におけるより柔軟な関数の使い方を補足します。lambda、map、filter、sorted の key 引数、そしてデコレータは、データ処理、フレームワークのソースコード、ユーティリティ関数でよく登場します。最初から高度なテクニックを目指すのではなく、まずは読めるようになり、少しずつ使えるようになることが目標です。
- 関数型プログラミングの基本的な考え方を理解する
- lambda 無名関数を身につける
map()、filter()、sorted()の key 引数を使いこなす- クロージャとデコレータの基本概念を理解する
最初から「関数型は優雅だ」と思う必要はありません。バッチ変換、絞り込み、並べ替え、そしてフレームワークに自分のロジックを渡す場面でよく使われる、ということだけ知っておけば十分です。
関数型プログラミングとは?
Section titled “関数型プログラミングとは?”簡単に言うと、関数型プログラミングとは関数をデータのように受け渡しして使うことです。
Python では、関数は第一級オブジェクトです。数字や文字列と同じように、次のことができます。
- 変数に代入する
- 別の関数の引数として渡す
- 戻り値として返す
# 関数は変数に代入できるdef greet(name): return f"こんにちは、{name}!"
say_hi = greet # 関数を変数に代入する(括弧がない点に注意)print(say_hi("小明")) # こんにちは、小明!
# 関数をリストに入れられるdef add(a, b): return a + bdef sub(a, b): return a - bdef mul(a, b): return a * b
operations = [add, sub, mul]for op in operations: print(op(10, 3)) # 13, 7, 30lambda 無名関数
Section titled “lambda 無名関数”lambda は一度だけ使う小さな関数です。def で定義する必要も、名前を付ける必要もありません。
# 通常の関数def square(x): return x ** 2
# 同じ処理をする lambdasquare = lambda x: x ** 2
print(square(5)) # 25構文:lambda 引数: 式
# 1つの引数double = lambda x: x * 2print(double(5)) # 10
# 複数の引数add = lambda a, b: a + bprint(add(3, 5)) # 8
# 条件付きsize_label = lambda hours: "大きいタスク" if hours >= 8 else "小さいタスク"print(size_label(12)) # 大きいタスクprint(size_label(3)) # 小さいタスクlambda の主な用途
Section titled “lambda の主な用途”lambda で最もよくある使い方は、他の関数に引数として渡すことです。
# 場面:特定のルールで並べ替えるtasks = [ {"name": "ログイン API", "hours": 8}, {"name": "RAG デモ", "hours": 12}, {"name": "グラフビュー", "hours": 5},]
# 見積もり時間順に並べるtasks.sort(key=lambda task: task["hours"])print([task["name"] for task in tasks]) # ['グラフビュー', 'ログイン API', 'RAG デモ']
# 見積もり時間の長い順に並べるtasks.sort(key=lambda task: task["hours"], reverse=True)print([task["name"] for task in tasks]) # ['RAG デモ', 'ログイン API', 'グラフビュー']map():各要素に同じ処理をする
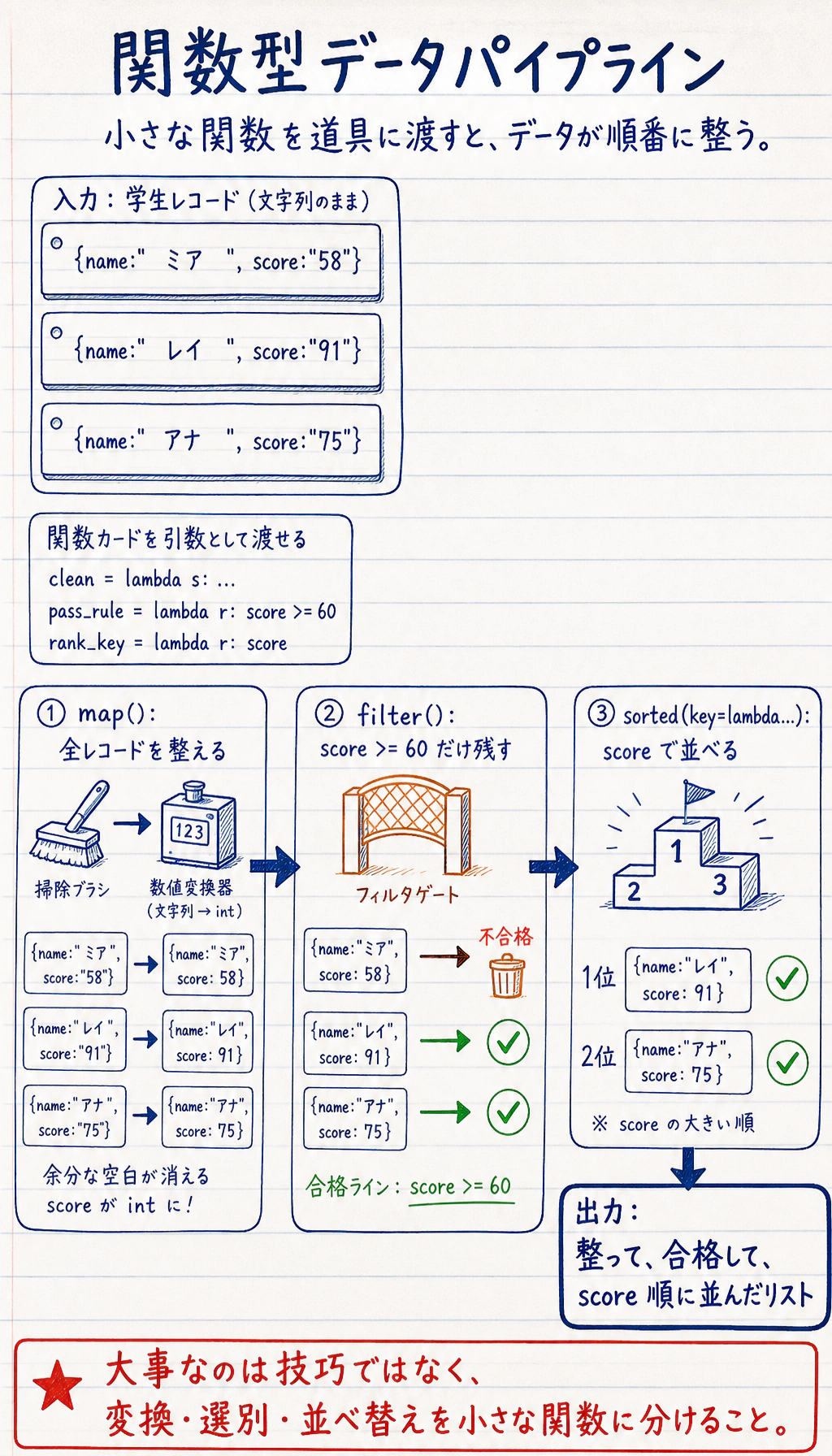
Section titled “map():各要素に同じ処理をする”map(関数, イテラブル) は、シーケンスの各要素に関数を適用し、新しいシーケンスを返します。
# リストの各数字を2乗するnumbers = [1, 2, 3, 4, 5]
# 方法 1:for ループsquares = []for n in numbers: squares.append(n ** 2)
# 方法 2:map を使うsquares = list(map(lambda x: x ** 2, numbers))print(squares) # [1, 4, 9, 16, 25]
# 方法 3:リスト内包表記(通常はこちらの方がおすすめ)squares = [x ** 2 for x in numbers]print(squares) # [1, 4, 9, 16, 25]map() の実用例
Section titled “map() の実用例”# データ型をまとめて変換するstr_numbers = ["10", "20", "30", "40"]numbers = list(map(int, str_numbers))print(numbers) # [10, 20, 30, 40]
# 文字列をまとめて処理するnames = [" alice ", " BOB", "charlie "]clean_names = list(map(str.strip, names))print(clean_names) # ['alice', 'BOB', 'charlie']
# 既存の関数を使うtemperatures_c = [0, 20, 37, 100]def c_to_f(c): return c * 9/5 + 32
temperatures_f = list(map(c_to_f, temperatures_c))print(temperatures_f) # [32.0, 68.0, 98.6, 212.0]filter():条件を満たす要素を絞り込む
Section titled “filter():条件を満たす要素を絞り込む”filter(関数, イテラブル) は、関数が True を返した要素だけを残します。
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 偶数を絞り込むevens = list(filter(lambda x: x % 2 == 0, numbers))print(evens) # [2, 4, 6, 8, 10]
# 同じ処理をするリスト内包表記evens = [x for x in numbers if x % 2 == 0]print(evens) # [2, 4, 6, 8, 10]filter() の実用例
Section titled “filter() の実用例”# 遅いレスポンスを絞り込むlatencies_ms = [45, 78, 55, 920, 880, 30, 67, 1000]slow = list(filter(lambda ms: ms >= 800, latencies_ms))print(f"遅いレスポンス: {slow}") # [920, 880, 1000]
# 空でない文字列を絞り込むdata = ["hello", "", "world", "", "python", ""]non_empty = list(filter(None, data)) # filter(None, ...) は真偽値が False のものを除くprint(non_empty) # ['hello', 'world', 'python']
# 特定の種類のファイルを絞り込むfiles = ["data.csv", "model.py", "readme.md", "train.py", "config.json"]py_files = list(filter(lambda f: f.endswith(".py"), files))print(py_files) # ['model.py', 'train.py']sorted() の key 引数
Section titled “sorted() の key 引数”sorted() の key 引数を使うと、並べ替えのルールを自分で決められます。
# 絶対値で並べるnumbers = [-5, 3, -1, 4, -2]result = sorted(numbers, key=abs)print(result) # [-1, -2, 3, 4, -5]
# 文字列の長さで並べるwords = ["python", "AI", "deep", "learning"]result = sorted(words, key=len)print(result) # ['AI', 'deep', 'python', 'learning']
# 辞書の特定キーで並べるtasks = [ {"name": "ログイン API", "owner_count": 2, "hours": 8}, {"name": "RAG デモ", "owner_count": 1, "hours": 12}, {"name": "グラフビュー", "owner_count": 1, "hours": 5},]
# 見積もり時間順に並べるby_hours = sorted(tasks, key=lambda task: task["hours"], reverse=True)for task in by_hours: print(f"{task['name']}: {task['hours']} 時間")# RAG デモ: 12 時間# ログイン API: 8 時間# グラフビュー: 5 時間
# 複数条件で並べる(まず優先度の高い順、同じなら見積もり時間の短い順)tasks2 = [ {"name": "A", "priority": 2, "hours": 8}, {"name": "B", "priority": 2, "hours": 5}, {"name": "C", "priority": 3, "hours": 12},]result = sorted(tasks2, key=lambda task: (-task["priority"], task["hours"]))for task in result: print(f"{task['name']}: priority={task['priority']}, hours={task['hours']}")# C: priority=3, hours=12# B: priority=2, hours=5# A: priority=2, hours=8クロージャ(Closure)
Section titled “クロージャ(Closure)”クロージャとは、外側の関数の変数を覚えている関数のことです。外側の関数の実行が終わっていても、その変数を使えます。
def make_multiplier(factor): """乗算器を作成する""" def multiplier(x): return x * factor # factor は外側の関数から来ている return multiplier
double = make_multiplier(2)triple = make_multiplier(3)
print(double(5)) # 10print(triple(5)) # 15print(double(10)) # 20クロージャの実用例
Section titled “クロージャの実用例”# カウンターを作るdef make_counter(start=0): count = [start] # 内側の関数で変更できるようにリストで包む def counter(): count[0] += 1 return count[0] return counter
counter = make_counter()print(counter()) # 1print(counter()) # 2print(counter()) # 3
# プレフィックス付きのログ関数を作るdef make_logger(prefix): def log(message): from datetime import datetime timestamp = datetime.now().strftime("%H:%M:%S") print(f"[{prefix}] {timestamp} {message}") return log
info = make_logger("INFO")error = make_logger("ERROR")
info("プログラムを起動しました") # [INFO] 14:30:01 プログラムを起動しましたerror("ファイルが見つかりません") # [ERROR] 14:30:01 ファイルが見つかりませんデコレータ(Decorator)
Section titled “デコレータ(Decorator)”デコレータは、関数に追加の機能を付けるためのスマートな方法です。本質的にはクロージャの応用です。
複数の関数に実行時間の計測を追加したいとします。
import time
# デコレータを使わない場合:各関数に計測コードを入れる必要があるdef train_model(): start = time.time() # ここでは簡単な学習ループを模擬する。実際のプロジェクトではモデル学習に置き換えられる epochs = 3 for epoch in range(epochs): time.sleep(0.25) print(f"{epoch + 1}/{epochs} エポック: 学習中...") time.sleep(1) end = time.time() print(f"train_model の実行時間: {end - start:.2f}秒")
def process_data(): start = time.time() # ここではデータ前処理を簡単に模擬する records = ["元データ1", "元データ2", "元データ3"] cleaned = [record.replace("元データ", "整形後") for record in records] print("整形結果:", cleaned) time.sleep(0.5) end = time.time() print(f"process_data の実行時間: {end - start:.2f}秒")各関数に同じ計測コードを書くのは、かなり面倒です。
デコレータによる解決
Section titled “デコレータによる解決”import time
def timer(func): """計測用デコレータ""" def wrapper(*args, **kwargs): start = time.time() result = func(*args, **kwargs) end = time.time() print(f"⏱ {func.__name__} の実行時間: {end - start:.2f}秒") return result return wrapper
# @ 構文でデコレータを使う@timerdef train_model(): """モデルを学習する""" time.sleep(1) print("学習が完了しました!")
@timerdef process_data(filename): """データを処理する""" time.sleep(0.5) print(f"{filename} の処理が完了しました!")
train_model()# 学習が完了しました!# ⏱ train_model の実行時間: 1.00秒
process_data("data.csv")# data.csv の処理が完了しました!# ⏱ process_data の実行時間: 0.50秒@timer は train_model = timer(train_model) と同じ意味です。
よく使うデコレータのパターン
Section titled “よく使うデコレータのパターン”# リトライ用デコレータdef retry(max_attempts=3): def decorator(func): def wrapper(*args, **kwargs): for attempt in range(1, max_attempts + 1): try: return func(*args, **kwargs) except Exception as e: print(f"{attempt} 回目の試行に失敗しました: {e}") if attempt == max_attempts: raise return wrapper return decorator
@retry(max_attempts=3)def risky_operation(): import random if random.random() < 0.7: raise ConnectionError("接続に失敗しました") return "成功!"map / filter とリスト内包表記の比較
Section titled “map / filter とリスト内包表記の比較”| 方法 | 適した場面 | 例 |
|---|---|---|
| リスト内包表記 | ほとんどの場面(おすすめ) | [x**2 for x in nums] |
map() | 既存の関数をそのまま使える | list(map(int, strings)) |
filter() | 既存の判定関数と組み合わせる | list(filter(str.isdigit, items)) |
# すでにある関数が使えるなら、map の方が簡潔numbers = ["1", "2", "3"]list(map(int, numbers)) # 簡潔[int(x) for x in numbers] # これでもよいが、少し長い
# 変換 + 条件が必要なら、リスト内包表記の方が見やすい[x**2 for x in range(10) if x % 2 == 0]# list(filter(lambda x: x%2==0, map(lambda x: x**2, range(10)))) よりずっと読みやすい手を動かしてみよう
Section titled “手を動かしてみよう”練習 1:データ処理パイプライン
Section titled “練習 1:データ処理パイプライン”# map と filter を使って次のデータを処理してみようraw_data = [" 23 ", "abc", "45.6", "", "78", "not_a_number", "90.1"]
# 1. 空白を取り除く# 2. 数値に変換できない文字列を除外する# 3. 浮動小数点数に変換する# 4. 50 未満の数を除外する# ヒント:map、filter、リスト内包表記を組み合わせることができる練習 2:カスタムソート
Section titled “練習 2:カスタムソート”products = [ {"name": "ノートPC", "price": 5999, "rating": 4.5}, {"name": "マウス", "price": 199, "rating": 4.8}, {"name": "キーボード", "price": 599, "rating": 4.2}, {"name": "モニター", "price": 2999, "rating": 4.7},]
# 1. 価格の安い順に並べる# 2. 評価の高い順に並べる# 3. コストパフォーマンス(rating/price)の高い順に並べる練習 3:デコレータを作る
Section titled “練習 3:デコレータを作る”関数の前後でログを出す @log デコレータを書いてみましょう。
@logdef add(a, b): return a + b
add(3, 5)# 出力例:# add を呼び出し、引数: (3, 5) {}# add の戻り値: 8参考実装と解説
- データ処理パイプラインは、空白除去、空文字と数値化できない値の除外、浮動小数点数への変換、
50以上の値だけを残す流れにします。サンプルでは78と90.1が残ります。 - 並べ替えは
sorted(..., key=...)を 3 回使い分けます。価格は昇順、評価は降順、コストパフォーマンスはrating / priceのような指標を作って降順にします。 - デコレータは元の関数を包み、実行前後にログを出し、戻り値をそのまま返します。実務では
functools.wrapsを使い、元の関数名や docstring を保つのがよい形です。
| 概念 | 説明 | 例 |
|---|---|---|
| lambda | 無名関数 | lambda x: x * 2 |
| map() | 各要素に関数を適用する | map(int, ["1", "2"]) |
| filter() | 条件を満たす要素を絞り込む | filter(lambda x: x>0, nums) |
| sorted(key=) | 並べ替えを自分で決める | sorted(data, key=lambda x: x["hours"]) |
| クロージャ | 関数が外側の変数を覚える | ファクトリ関数パターン |
| デコレータ | 関数に追加機能を付ける | @timer |