9.9.6 本番環境のベストプラクティス
- 本番環境で最も重要なリリースと運用の原則を理解する
- 最小限のリリース前チェックリストを設計できるようになる
- 段階的リリース、ロールバック、アラート、手動引き継ぎの役割を理解する
- 実行可能な例を通して、本番準備の考え方を身につける
リリース前に本当に確認すべきことは?
Section titled “リリース前に本当に確認すべきことは?”機能が正しいだけでは、まだ最低限にすぎない
Section titled “機能が正しいだけでは、まだ最低限にすぎない”本番準備には、少なくとも次の内容も含まれます。
- 監視できるか
- ロールバックできるか
- レート制限とタイムアウトがあるか
- 安全境界があるか
- 評価の基準値があるか
とても実用的な判断基準
Section titled “とても実用的な判断基準”あるサービスをリリースしたあとに問題が起きたら、次のことがすでに分かっているでしょうか。
- ログをどこで見るか
- どの指標を見るか
- どのように旧バージョンへ戻すか
- 誰が手動で引き継ぐか
これらに答えられないなら、そのシステムはまだ本番投入の準備ができていないことが多いです。
本番環境で最も重要な6つの原則
Section titled “本番環境で最も重要な6つの原則”まず段階的に出す。いきなり全量投入しない
Section titled “まず段階的に出す。いきなり全量投入しない”Agent システムの不確実性は、通常の CRUD より高いことがよくあります。
段階的リリースにより、先に次の変化を観察できます。
- 正確性の変化
- レイテンシの変化
- コストの変化
ロールバック経路は必ず残しておく
Section titled “ロールバック経路は必ず残しておく”ロールバックがなければ、真に安全なリリースとは言えません。
重要な機能には必ず手動引き継ぎの仕組みを用意する
Section titled “重要な機能には必ず手動引き継ぎの仕組みを用意する”特に次のようなものです。
- 高リスク操作
- 書き込み操作
- 外部への副作用を伴うタスク
リリースの前に、まずアラートを定義する
Section titled “リリースの前に、まずアラートを定義する”少なくとも、次を明確にしておく必要があります。
- どの指標の異常でアラートを出すか
- 誰がそのアラートを受けるか
- 発火したら最初に何を確認するか
すべての重要な動作は監査可能であるべき
Section titled “すべての重要な動作は監査可能であるべき”特に次の項目です。
- ツール呼び出し
- 権限判定
- 重要な状態変更
リリースは評価と結びつける
Section titled “リリースは評価と結びつける”リリースは「モデルを信じる」ことではありません。
「評価結果と本番のシグナルを一緒に見て判断する」ことです。
まずは最小の準備チェッカーを動かしてみよう
Section titled “まずは最小の準備チェッカーを動かしてみよう”次の例では、リリース前チェックの一式をシミュレーションします。
実際にサービスをデプロイするのではなく、次の問いに答えます。
- このシステムは、今すでに最低限の本番条件を満たしているか
deployment_config = { "has_metrics": True, "has_structured_logs": True, "has_timeout": True, "has_retry_policy": True, "has_rate_limit": False, "has_eval_suite": True, "has_canary_rollout": True, "has_rollback_plan": True, "has_human_override": False, "has_audit_log": True,}
def readiness_check(config): required = [ "has_metrics", "has_structured_logs", "has_timeout", "has_retry_policy", "has_eval_suite", "has_canary_rollout", "has_rollback_plan", "has_audit_log", ]
missing_required = [key for key in required if not config.get(key, False)] warnings = []
if not config.get("has_rate_limit", False): warnings.append("missing_rate_limit") if not config.get("has_human_override", False): warnings.append("missing_human_override")
ready = len(missing_required) == 0 return { "ready": ready, "missing_required": missing_required, "warnings": warnings, }
print(readiness_check(deployment_config))実行結果の例:
{'ready': True, 'missing_required': [], 'warnings': ['missing_rate_limit', 'missing_human_override']}
この例から得られる最も重要な気づきは?
Section titled “この例から得られる最も重要な気づきは?”この例が教えてくれるのは、次のことです。
- 本番準備は「感覚」ではない
- ちゃんと確認できる条件の集まりである

「不足項目」を明示することがなぜ大切なのか?
Section titled “「不足項目」を明示することがなぜ大切なのか?”こうすることで、チームの議論が次のように変わるからです。
- 「なんとなく、もう大丈夫そう」
から
- 「今は rate limit と human override が足りない」
へ変わります。
そのほうが、リリース判断をずっと明確にできます。
なぜ段階的リリースが Agent に特に重要なのか?
Section titled “なぜ段階的リリースが Agent に特に重要なのか?”Agent の問題は確率的に起きることが多いから
Section titled “Agent の問題は確率的に起きることが多いから”問題によっては、ローカルでは毎回再現できず、
本番の実トラフィックで初めて表面化します。たとえば次のようなケースです。
- ある種類の複雑な入力で、誤った経路に入る
- あるツールが高並列時に不安定になる
- ある Prompt が境界的なサンプルで暴走する
段階的リリースの主な利点
Section titled “段階的リリースの主な利点”- 少量のトラフィックで先に検証できる
- 旧システムを保険として残せる
- 本番環境で指標を収集できる
とてもシンプルなトラフィック割り当ての例
Section titled “とてもシンプルなトラフィック割り当ての例”def route_request(request_id, canary_ratio=0.2): bucket = sum(ord(c) for c in request_id) % 100 return "new_agent" if bucket < canary_ratio * 100 else "stable_agent"
for request_id in ["req-001", "req-002", "req-003", "req-004"]: print(request_id, "->", route_request(request_id))実行結果の例:
req-001 -> new_agentreq-002 -> new_agentreq-003 -> stable_agentreq-004 -> stable_agent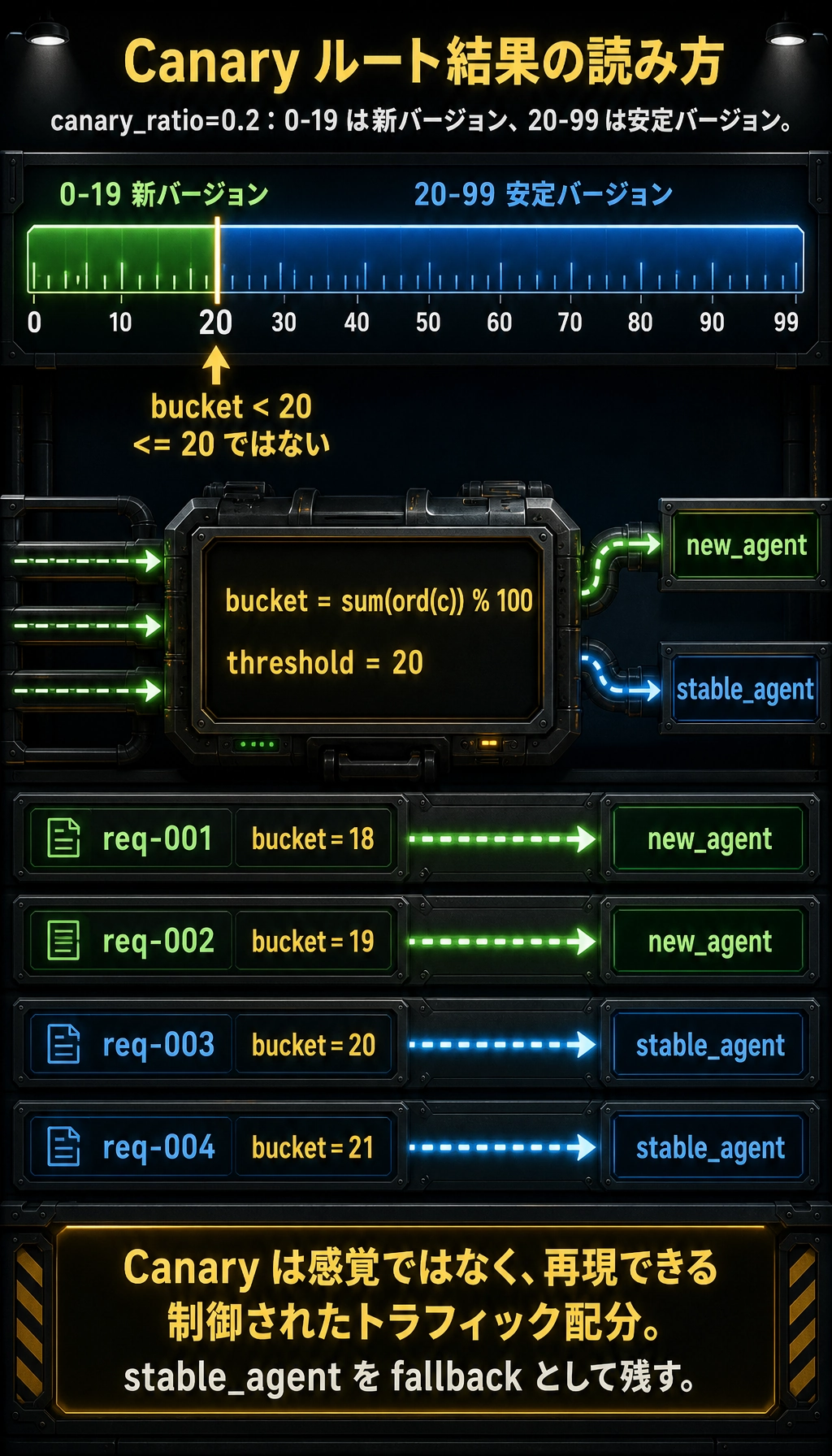
このコードはシンプルですが、次のことを示しています。
- 段階的リリースは難しいものではない
- 本質は、制御されたトラフィック分配である
なぜロールバックは事前に設計しておく必要があるのか?
Section titled “なぜロールバックは事前に設計しておく必要があるのか?”ロールバックは、問題が起きてから考えるものではない
Section titled “ロールバックは、問題が起きてから考えるものではない”システムに問題が出てから、次のことを考え始めるとしたら、たいてい遅すぎます。
- どのバージョンに戻すか
- 状態をどう復旧するか
- データの副作用をどう扱うか
ロールバックでは少なくとも3点を答えられる必要がある
Section titled “ロールバックでは少なくとも3点を答えられる必要がある”- どうやって旧バージョンに切り戻すか
- 新バージョンが作った中間状態をどう処理するか
- 高リスク動作を一時停止する必要があるか
なぜ Agent のロールバックは普通のページより複雑なのか?
Section titled “なぜ Agent のロールバックは普通のページより複雑なのか?”Agent はすでに次のようなものを発生させている可能性があるからです。
- ツール呼び出しの副作用
- 永続化された状態
- 外部システムへの書き込み
そのため、ロールバックは「イメージを切り戻す」だけではありません。
状態の整合性まで考える必要があります。
アラートと手動引き継ぎはどう連携させるのか?
Section titled “アラートと手動引き継ぎはどう連携させるのか?”アラートは多ければよいわけではない
Section titled “アラートは多ければよいわけではない”大事なのは、次の点です。
- アラートが、具体的な行動につながること
たとえば次のようなものです。
- タイムアウト率 > 5%
- サーキットブレーカーが連続で開いたまま
- コストが突然、通常範囲から外れた
手動引き継ぎは失敗ではなく、成熟の証
Section titled “手動引き継ぎは失敗ではなく、成熟の証”高リスクシステムでは、手動引き継ぎは次のことを認めているという意味です。
- 自動化には限界がある
これはむしろ、成熟した設計に近い考え方です。
よくある引き継ぎ方法
Section titled “よくある引き継ぎ方法”- 人間のオペレーターやカスタマーサポートへ切り替える
- 書き込み操作を停止する
- 読み取り専用モードに切り替える
- 人による承認を必須にする
最も起こりやすい落とし穴
Section titled “最も起こりやすい落とし穴”落とし穴1:リリース前に機能の単体確認だけする
Section titled “落とし穴1:リリース前に機能の単体確認だけする”評価、監視、ロールバック、段階的リリースがなければ、
機能確認だけでは全然足りません。
落とし穴2:セキュリティ系のシステムだけが監査を必要とすると思う
Section titled “落とし穴2:セキュリティ系のシステムだけが監査を必要とすると思う”多くの通常業務の Agent でも、次のようなものを扱います。
- ユーザーデータ
- 書き込み操作
- 外部への副作用
監査は同じくらい重要です。
落とし穴3:本番ベストプラクティスはチェックリスト1枚で終わると思う
Section titled “落とし穴3:本番ベストプラクティスはチェックリスト1枚で終わると思う”チェックリストはとても重要です。
ただし、実際に役立つためには次の前提が必要です。
- チームが、誰が責任を持つか分かっている
- 問題が起きたときに、実際に実行される
期待される結果:段階的リリース、rollback、alert、audit、手動引き継ぎを README や運用メモに整理し、本番準備を説明できる状態です。
このページを終えたら、この証拠カードを残します。
- ランタイム
- キュー、ワーカー、状態ストア、ツールサービス、モデルエンドポイント
- 永続化
- チェックポイント、イベントログ、メモリストア、復旧パス
- 運用シグナル
- レイテンシ、コスト、エラー率、追跡カバレッジ、飽和度
- 失敗確認
- 停止した実行、重複アクション、部分失敗、またはコスト暴走
- 復旧アクション
- 再開、ロールバック、中止、人間への引き継ぎ、または安全に劣化
この節で最も重要なのは、本番環境の見方を持つことです。
Agent の本番準備 は、「機能が動いた」で終わりではなく、段階的リリース、ロールバック、アラート、監査、手動引き継ぎという安全機構がそろって初めて成立する。
これらの仕組みがそろっていて、はじめてそのシステムは「本番環境」と呼べます。
- 今の自分のプロジェクトに合わせて、準備設定表を作り、何が足りないか確認してみましょう。
- なぜ、段階的リリースは静的ページよりも Agent に対して重要だと言えるのでしょうか?
- ある高リスクのツール呼び出しが急に増えて異常になったら、あなたはまずアラート、サーキットブレーカー、手動引き継ぎのどれを優先しますか? その理由も考えてみましょう。
- 考えてみましょう。ロールバックはなぜ「コードを1つ前のバージョンに戻す」だけではないのでしょうか?
プロジェクト参考とレビュー観点
- 準備状況表 には tools、permissions、tracing、evaluation cases、rollback、budget limits、human approval、incident response について owner、status、evidence、next action を書きます。
- canary rollout が Agent で重要なのは、behavior が prompt、tools、external data、model version、user goal に依存するからです。小さな traffic exposure が static page check では見えない failure を見つけます。
- high-risk call が急増したら、まず alerting で人が知れる状態にします。危険または説明不能なら circuit breaking を使い、安全に継続すべき case は human takeover に回します。
- rollback は code を戻すだけではありません。prompt、model version、tool schema、memory、queue、cached results、external side effects も戻すか整合させる必要があります。