5.5.3 特徴量の前処理
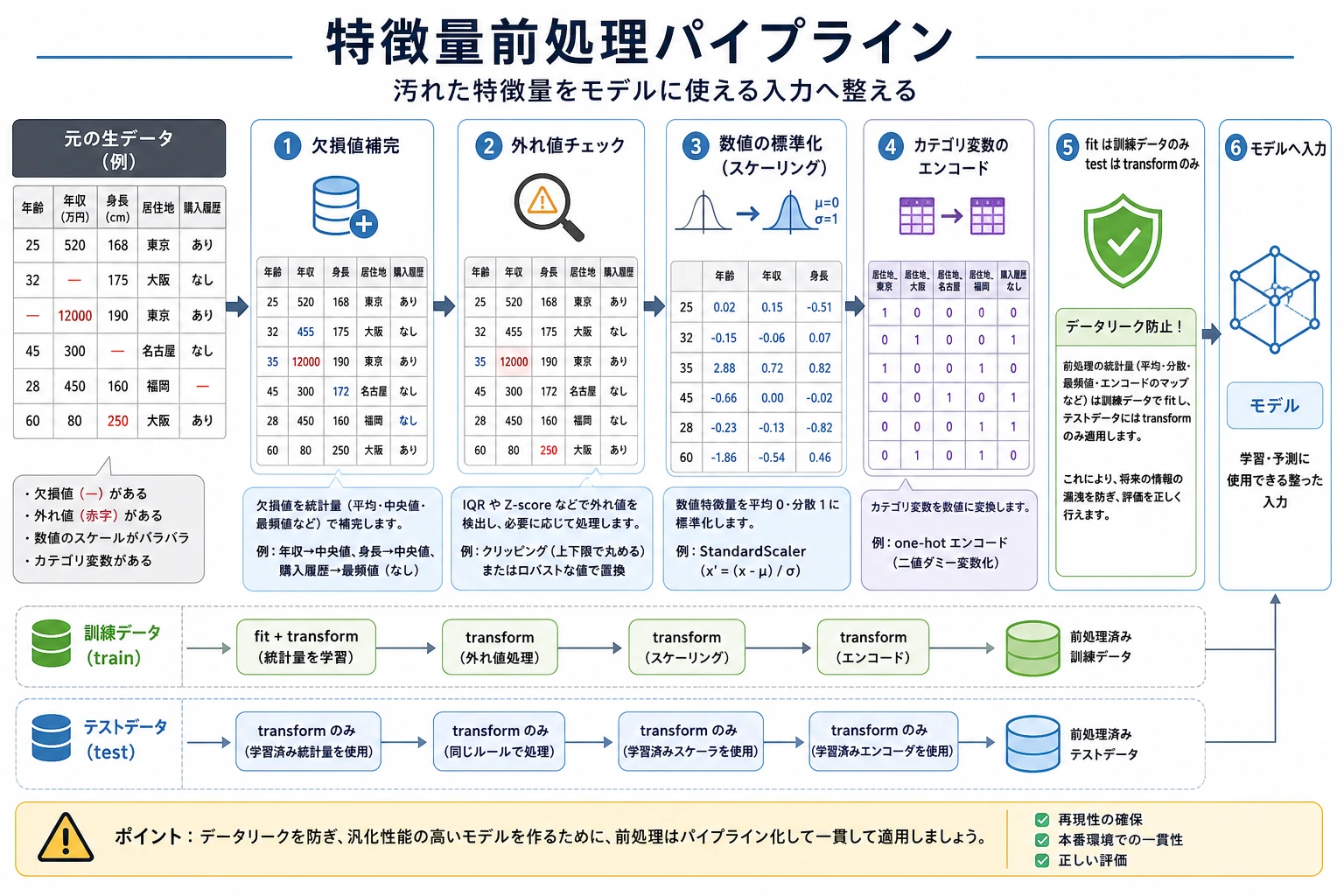
- 欠損値、外れ値、スケーリング、エンコードがそれぞれ何を解決するのか理解する
- モデルごとに標準化が必要かどうか判断できる
- One-Hot、Ordinal Encoding、Target Encoding の適用範囲を知る
- データリークを避ける基本的な意識を身につける
まず全体の地図を作ろう
Section titled “まず全体の地図を作ろう”flowchart LR A[元の特徴量] --> B[欠損値処理] B --> C[外れ値処理] C --> D[数値のスケーリング] D --> E[カテゴリのエンコード] E --> F[モデルへ入力]この図はあくまでよくある順番であって、固定の手順ではありません。たとえば木系モデルは通常、標準化にあまり依存しませんが、線形モデル、KNN、SVM、ニューラルネットワークはスケーリングがより重要になることが多いです。
ここからの例をそのまま実行できるように準備する
Section titled “ここからの例をそのまま実行できるように準備する”後半のコードを単独で動かせるように、まずは小さな混合型データセットを用意します。欠損値、数値列、カテゴリ列がすべて入っています。
import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_split
df = pd.DataFrame({ "age": [25, np.nan, 39, 51, 45, np.nan, 33, 60], "income": [50000, 62000, np.nan, 120000, 85000, 76000, 54000, 200000], "amount": [80, 95, 120, 10000, 110, 130, 70, 150], "city": ["A", "B", "A", "C", None, "B", "D", "A"], "gender": ["F", "M", "F", "M", "F", None, "M", "F"], "target": [0, 1, 0, 1, 0, 1, 0, 1],})
X = df[["age", "income", "amount", "city", "gender"]]y = df["target"]X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25, random_state=42, stratify=y)一、欠損値処理
Section titled “一、欠損値処理”欠損値は、汚れたデータである場合もあれば、それ自体が情報になっている場合もあります。たとえば「ユーザーが会社名を入力していない」ことは一般個人ユーザーを意味するかもしれませんし、「健診項目が欠けている」ことは単なるシステム入力ミスかもしれません。処理する前に、まず「なぜ欠損しているのか」を考えましょう。
import pandas as pd
missing_rate = df.isna().mean().sort_values(ascending=False)print(missing_rate)よくある方法には、欠損が多すぎる列を削除する、数値特徴量には平均値や中央値で補完する、カテゴリ特徴量には最頻値や「unknown」で補完する、欠損しているかどうかを表すフラグ列を追加する、などがあります。いきなり全部に dropna() を使うのは避けましょう。大量のサンプルを失う可能性があります。
二、外れ値処理
Section titled “二、外れ値処理”外れ値が必ずしも間違いとは限りません。金融詐欺、機器の故障、極端な購買行動などは、むしろモデルが最も注目すべきサンプルかもしれません。外れ値を扱うときは、業務上の意味と合わせて考える必要があります。
q1 = df["amount"].quantile(0.25)q3 = df["amount"].quantile(0.75)iqr = q3 - q1lower = q1 - 1.5 * iqrupper = q3 + 1.5 * iqroutliers = df[(df["amount"] < lower) | (df["amount"] > upper)]print(outliers.head())外れ値が入力ミスなら、修正または削除できます。もし外れ値が本当に珍しい行動を表しているなら、残したうえで、頑健なモデルやビン分割で扱うことを考えましょう。
三、数値のスケーリング:標準化が必要なのはいつか
Section titled “三、数値のスケーリング:標準化が必要なのはいつか”標準化は、特徴量ごとの単位や大きさの違いが大きすぎる問題を解決します。たとえば年齢は数十ですが、収入は数万かもしれません。モデルが距離や勾配に依存する場合、スケール差は学習に影響します。
| モデルの種類 | 通常、スケーリングは必要か | 理由 |
|---|---|---|
| 線形回帰 / ロジスティック回帰 | 必要なことを推奨 | 勾配と正則化項がスケールの影響を受ける |
| KNN / SVM | 通常必要 | 距離計算がスケールの影響を受ける |
| ニューラルネットワーク | 通常必要 | 学習を安定させやすい |
| 決定木 / ランダムフォレスト / GBDT | 通常不要 | しきい値で分割するため、単調なスケーリングに敏感ではない |
from sklearn.preprocessing import StandardScaler
numeric_cols = ["age", "income", "amount"]scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train[numeric_cols])X_test_scaled = scaler.transform(X_test[numeric_cols])print(X_train_scaled[:2])注意: fit は必ず訓練集だけで行い、そのあとでテスト集に transform します。全データで scaler を fit すると、テスト集の情報が学習に漏れてしまいます。
四、カテゴリのエンコード
Section titled “四、カテゴリのエンコード”カテゴリ特徴量は、そのままでは多くの伝統的なモデルに入力できないため、エンコードが必要です。もっともよく使われるのは One-Hot Encoding で、都市、色、職業のような順序のないカテゴリに向いています。
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(handle_unknown="ignore")X_train_cat = encoder.fit_transform(X_train[["city"]])X_test_cat = encoder.transform(X_test[["city"]])print(X_train_cat.shape, X_test_cat.shape)順序があるカテゴリには Ordinal Encoding が使えます。たとえば学歴や S / M / L のサイズです。ただし、順序のないカテゴリを適当に 0、1、2 に変換してはいけません。モデルが「数値が大きいほど上位」と誤解する可能性があります。
Target Encoding は高カーディナリティのカテゴリに有効な場合がありますが、データリークが起きやすいです。たとえば「各都市の平均CVR」で都市をエンコードする場合、必ず訓練折だけで計算し、全データのラベルを直接使わないようにしましょう。
五、Pipeline を使ってリークを防ぐ
Section titled “五、Pipeline を使ってリークを防ぐ”もっとも安全な方法は、前処理とモデルを同じ Pipeline にまとめることです。そうすると、交差検証の各 fold で、前処理器はその fold の訓練部分だけで fit されます。
from sklearn.compose import ColumnTransformerfrom sklearn.pipeline import Pipelinefrom sklearn.impute import SimpleImputerfrom sklearn.preprocessing import OneHotEncoder, StandardScalerfrom sklearn.linear_model import LogisticRegression
num_features = ["age", "income", "amount"]cat_features = ["city", "gender"]
preprocess = ColumnTransformer([ ("num", Pipeline([ ("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler()), ]), num_features), ("cat", Pipeline([ ("imputer", SimpleImputer(strategy="most_frequent")), ("onehot", OneHotEncoder(handle_unknown="ignore")), ]), cat_features),])
model = Pipeline([ ("preprocess", preprocess), ("clf", LogisticRegression(max_iter=1000)),])
model.fit(X_train, y_train)print(model.score(X_test, y_test))
このページを終えたら、この evidence card を残します。
- 特徴状態
- 生の列、型、欠損値、スケール、およびターゲットとの関係
- 変換
- 前処理、構築、選択、またはパイプライン手順
- 出力
- transformされたfeature table、pipeline object、scoreの変化、または選択された特徴量
- 失敗確認
- リーク、不一致な train/test 変換、高カーディナリティの落とし穴、または無意味な特徴
- 期待される成果
- 前後比較とメトリクスへの影響を含む特徴量パイプラインの証拠
よくある間違い
Section titled “よくある間違い”1つ目の間違いは、すべてのモデルに標準化をかけることです。木系モデルでは通常不要で、かけても効果がないことがあります。2つ目の間違いは、訓練データとテストデータに分ける前に前処理をしてしまうことです。これはデータリークになります。3つ目の間違いは、カテゴリを適当に数字へ置き換えてしまい、存在しない大小関係をモデルに学習させることです。4つ目の間違いは、外れ値を消しすぎて、本当に価値のある極端なサンプルまで失うことです。
- Titanic データセットを使って欠損率をそれぞれ集計し、各列の処理方針を考えてみましょう。
- 同じデータで LogisticRegression と RandomForest をそれぞれ学習し、標準化が両者に与える影響を比較しましょう。
- なぜ scaler は全量データではなく訓練集で
fitするべきなのか説明しましょう。 - 高カーディナリティのカテゴリ特徴量を1つ選び、One-Hot と Target Encoding のそれぞれにどんなリスクがあるか考えましょう。
解法と解説
- 欠損率が低い列は中央値や最頻値で補完できることが多いです。欠損率が高い列は、欠損 indicator、ドメイン確認、削除を検討し、列ごとに理由を残します。
- LogisticRegression は係数と最適化が数値スケールに影響されるため、標準化の効果が出やすいです。RandomForest は分割順序を見るため、スケールの影響は小さいです。
- scaler は訓練データだけで平均と分散を学ぶ必要があります。全量で fit すると、テストデータの分布情報が訓練に漏れます。
- One-Hot は高カーディナリティで疎な列を大量に作ります。Target Encoding は交差検証内で行わないとラベル情報が漏れやすくなります。
この節を学び終えたら、表形式データに対する前処理方針を自分で書けるようになり、各ステップの理由を説明でき、Pipeline を使ってデータリークを防げるようになり、あるモデルに標準化やカテゴリエンコードが本当に必要か判断できるようになっているはずです。