10.1.2 デジタル画像の基礎
![]()
この節が終わると、次のことができるようになります。
- 画像のピクセル表現とカラーチャンネルを理解する
- グレースケール画像とカラー画像の保存方式を区別する
- RGB と HSV の違いを理解する
- 代表的な画像フォーマットがどんな場面に向いているかを知る
この節と第 6 章の CNN メインラインはどうつながるのか
Section titled “この節と第 6 章の CNN メインラインはどうつながるのか”もしあなたが畳み込みニューラルネットワークを学び終えたところなら、この節は次のように考えるとよいです。
- CNN は、なぜネットワークが画像を見るのに向いているのかを教えてくれる
- この節では、その「画像」という入力そのものを分解して見ていく
つまり、この節はモデルのメインラインからそれるのではなく、いちばん大事な入力の直感を補っているのです。
- 画像はコンピュータの中で実際には何なのか
- なぜチャンネル、色空間、サイズといった概念が、あとで何度も出てくるのか
一、コンピュータの目には、画像は何に見えるのか?
Section titled “一、コンピュータの目には、画像は何に見えるのか?”人が1枚の猫の写真を見ると、「これは猫だ」と思います。 でもコンピュータが見ているのは「猫」ではなく、たくさんの数字です。
いちばんシンプルに言うと:
画像 = 位置ごとに並んだ数字の行列
これは「光るチェス盤」のように考えられます。
- 各マスが1つのピクセル(pixel)
- 各ピクセルには明るさや色の値が入っている
- すべてのピクセルが並ぶと、1枚の画像になる
画像を学び始めるとき、まず何をつかむべきか?
Section titled “画像を学び始めるとき、まず何をつかむべきか?”最初に押さえるべきなのは「この画像は何の内容か」ではなく、次の点です。
コンピュータにとって、画像はまず空間的に並んだ数字のグリッドである。
この1文がしっかり理解できると、あとで多くの処理がずっと見通しやすくなります。
- なぜ畳み込みは局所ウィンドウを動かすのか
- なぜチャンネルを分けて処理できるのか
- なぜ検出やセグメンテーションでもピクセル空間が必要なのか
二、ピクセル:画像の最小単位
Section titled “二、ピクセル:画像の最小単位”グレースケール画像
Section titled “グレースケール画像”グレースケール画像では、各ピクセルは明るさを表す1つの数だけで表現できます。
0は真っ黒255は真っ白- その中間の値は、さまざまな濃さのグレー
import numpy as np
# 5x5 のグレースケール画像gray = np.array([ [0, 50, 100, 150, 200], [30, 80, 130, 180, 230], [60, 110, 160, 210, 255], [20, 70, 120, 170, 220], [10, 40, 90, 140, 190]], dtype=np.uint8)
print("グレースケール画像の shape:", gray.shape)print(gray)実行結果の例:
グレースケール画像の shape: (5, 5)[[ 0 50 100 150 200] [ 30 80 130 180 230] [ 60 110 160 210 255] [ 20 70 120 170 220] [ 10 40 90 140 190]]ここでの shape は (5, 5) です。これは次を意味します。
- 高さ 5
- 幅 5
つまり、この画像には 25 個のピクセルしかありません。
カラー画像はふつう RGB で色を表します。
R= 赤の強さG= 緑の強さB= 青の強さ
各ピクセルは1つの数ではなく、3つの数を持ちます。
import numpy as np
# 2x2 の RGB 画像rgb = np.array([ [[255, 0, 0], [ 0, 255, 0]], [[ 0, 0, 255], [255, 255, 0]]], dtype=np.uint8)
print("RGB 画像の shape:", rgb.shape)print(rgb)実行結果の例:
RGB 画像の shape: (2, 2, 3)[[[255 0 0] [ 0 255 0]]
[[ 0 0 255] [255 255 0]]]ここで shape = (2, 2, 3) は次を意味します。
- 高さ 2
- 幅 2
- 各ピクセルに 3 つのチャンネル
この節でまず身につけたい習慣
Section titled “この節でまず身につけたい習慣”画像配列を見たら、すぐに次の3つを確認する習慣をつけましょう。
- shape はいくつか?
- 各次元は何を表しているか?
- チャンネルは最後の次元にあるのか、それとも最初の次元にあるのか?
この習慣があるだけで、画像コードでの shape の混乱をかなり減らせます。
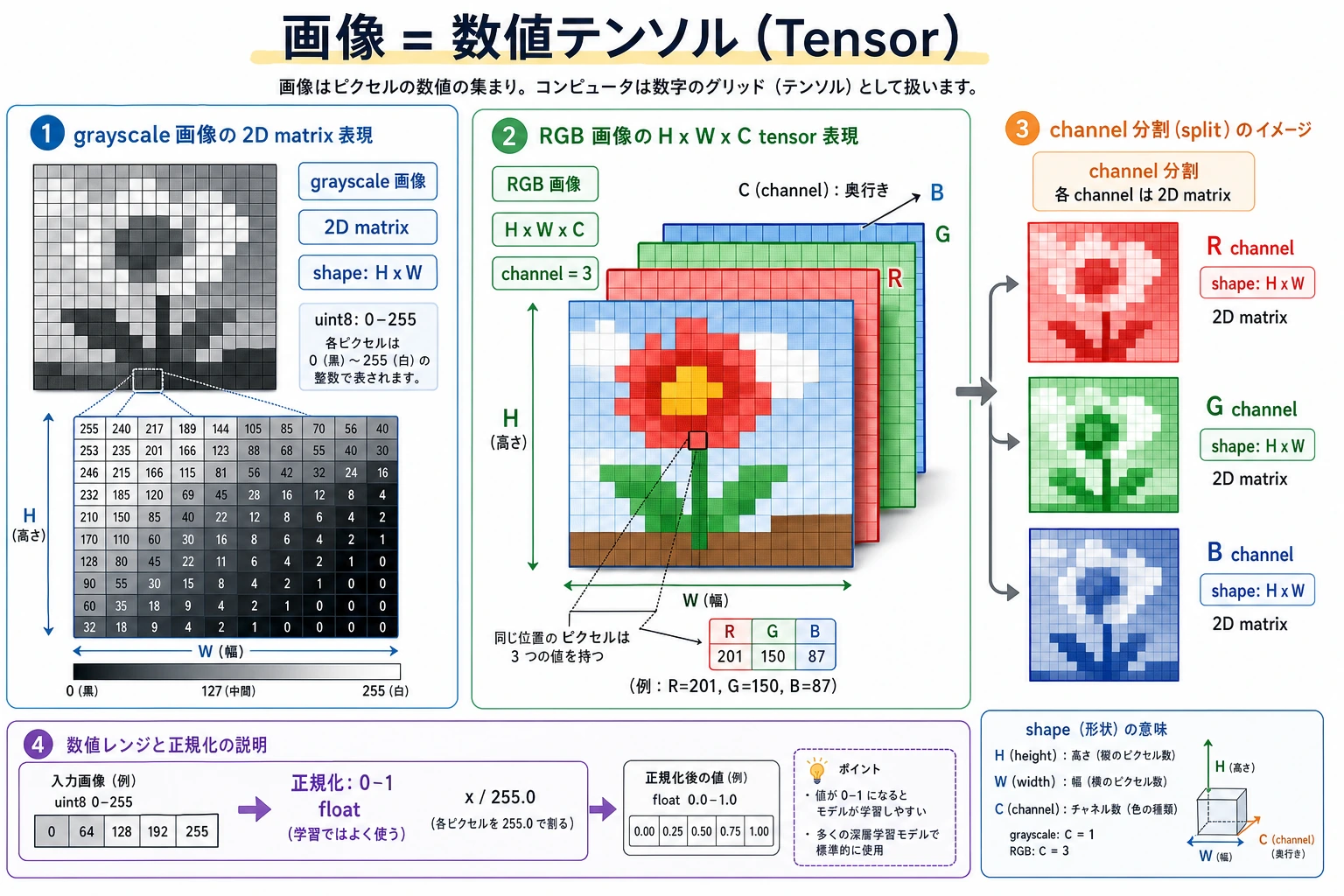
三、チャンネルとは何か?
Section titled “三、チャンネルとは何か?”チャンネル(channel)は、「同じ1枚の画像の中にある、色ごとの層」と考えるとわかりやすいです。
たとえば:
1枚の RGB 画像は、赤い薄膜、緑の薄膜、青い薄膜の3枚を重ねたもののようなイメージです。
import numpy as np
rgb = np.array([ [[255, 0, 0], [ 0, 255, 0]], [[ 0, 0, 255], [255, 255, 0]]], dtype=np.uint8)
red_channel = rgb[:, :, 0]green_channel = rgb[:, :, 1]blue_channel = rgb[:, :, 2]
print("R チャンネル:\n", red_channel)print("G チャンネル:\n", green_channel)print("B チャンネル:\n", blue_channel)実行結果の例:
R チャンネル: [[255 0] [ 0 255]]G チャンネル: [[ 0 255] [ 0 255]]B チャンネル: [[ 0 0] [255 0]]コンピュータビジョンでは、「チャンネルを分ける」処理はとてもよく使われます。
たとえば:
- 明るさだけを分析する
- 特定の色だけを強調する
- まずグレースケールにしてからエッジ検出を行う
チャンネルでいちばん大事なのは、定義よりも「個別に扱える」こと
Section titled “チャンネルでいちばん大事なのは、定義よりも「個別に扱える」こと”つまり:
- カラー画像は1つの大きなブラックボックスではない
- 実際には、色の層が重なってできている
これはとても重要です。というのも、あとで出てくる多くの画像処理は本質的に次のことをしているからです。
- チャンネルを分ける
- チャンネルを組み直す
- あるチャンネルだけを個別に処理する
四、なぜ画像は uint8 をよく使うのか?
Section titled “四、なぜ画像は uint8 をよく使うのか?”ほとんどの画像では、ピクセル値の範囲は 0~255 なので、保存には uint8 がよく使われます。
u= unsigned、符号なしint8= 8ビット整数0~255を表せる
import numpy as np
pixel = np.array([128, 200, 30], dtype=np.uint8)print(pixel, pixel.dtype)実行結果の例:
[128 200 30] uint8ただし、モデル学習では画像を 0~1 に正規化することがよくあります。
import numpy as np
pixel = np.array([128, 200, 30], dtype=np.float32)pixel_normalized = pixel / 255.0
print(pixel_normalized)実行結果の例:
[0.5019608 0.78431374 0.11764706]なぜ正規化するのか?
Section titled “なぜ正規化するのか?”ニューラルネットワークは、数値スケールが安定したデータを好むからです。 料理で言えば、調味料はそれぞれ適切な量で入れる必要があり、1つだけ「グラム」、別の1つだけ「バケツ」では困ります。
これが第 6 章の学習主線に直接関係する理由
Section titled “これが第 6 章の学習主線に直接関係する理由”第 6 章では、すでに次のことを見ました。
- モデル学習は入力のスケールにとても敏感である
- 最適化器や勾配は数値範囲の影響を受ける
つまり、画像の正規化は視覚分野だけの小さなテクニックではなく、
- 画像データを学習フローに入れる前の標準的な準備
なのです。
五、RGB と HSV の違いは何か?
Section titled “五、RGB と HSV の違いは何か?”RGB: 「赤・緑・青をどれだけ混ぜるか」で色を表す
Section titled “RGB: 「赤・緑・青をどれだけ混ぜるか」で色を表す”RGB は、画像を保存したり表示したりするのに向いています。 ただし、人が色を説明するときの感覚とは少し違います。
たとえば人は、次のように言うことが多いです。
- この色は赤っぽい
- 彩度が高い
- もう少し明るい
こういうときは HSV のほうが直感的です。
H= Hue、色相S= Saturation、彩度V= Value、明度
そのまま実行できる小さな例
Section titled “そのまま実行できる小さな例”import colorsys
# 赤系のピクセル。まず 0~255 を 0~1 に変換するr, g, b = 255 / 255, 80 / 255, 80 / 255h, s, v = colorsys.rgb_to_hsv(r, g, b)
print("HSV:")print("H =", round(h, 3))print("S =", round(s, 3))print("V =", round(v, 3))実行結果の例:
HSV:H = 0.0S = 0.686V = 1.0RGB と HSV はどんな場面に向いているか?
Section titled “RGB と HSV はどんな場面に向いているか?”| 色空間 | より向いていること |
|---|---|
| RGB | 保存、表示、ニューラルネットワークへの入力 |
| HSV | 色の選別、色の分割、「色相/明るさ」での画像処理 |
たとえば「画像の中の赤っぽい部分を見つけたい」ときは、RGB より HSV のほうが扱いやすいことが多いです。
六、カラー画像をグレースケールに変換する
Section titled “六、カラー画像をグレースケールに変換する”グレースケール画像は、単純に3つのチャンネルを平均したものではありません。 ふつうは、人間の目が色によって感じやすさが違うことを考えて、重み付きで計算します。
よく使われる式は次のとおりです。
gray = 0.299*R + 0.587*G + 0.114*B
import numpy as np
rgb = np.array([ [[255, 0, 0], [ 0, 255, 0]], [[ 0, 0, 255], [255, 255, 255]]], dtype=np.float32)
gray = ( 0.299 * rgb[:, :, 0] + 0.587 * rgb[:, :, 1] + 0.114 * rgb[:, :, 2])
print(gray.astype(np.uint8))実行結果の例:
[[ 76 149] [ 29 255]]七、画像フォーマットはどう選ぶか?
Section titled “七、画像フォーマットはどう選ぶか?”これはとても実務的ですが、かなり役立つ知識です。
| フォーマット | 特徴 | よくある用途 |
|---|---|---|
| JPG / JPEG | 非可逆圧縮、容量が小さい | 写真、Web 表示 |
| PNG | 可逆圧縮、透明背景をサポート | アイコン、スクリーンショット、UI 素材 |
| WebP | 圧縮効率が高い | आधुनिकな Web 画像 |
| BMP | ほぼ圧縮しない、容量が大きい | 教材、低レベル処理 |
とても実用的な直感
Section titled “とても実用的な直感”- 写真: まず
JPG - 透明背景が必要: まず
PNG - 画質と容量のバランスを取りたい:
WebPを検討する
八、なぜ視覚タスクでは「解像度」がよく話題になるのか?
Section titled “八、なぜ視覚タスクでは「解像度」がよく話題になるのか?”解像度は画像のサイズのことです。たとえば:
224 x 224640 x 4801920 x 1080
解像度が高いほど:
- 細部が増える
- そのぶん計算量も大きくなる
これは地図を見るときと似ています。
- 拡大すると、より細かく見える
- でも処理しなければならない情報も増える
そのため、多くの深層学習モデルでは、画像をあらかじめ固定サイズに縮小します。
九、小さな実験: 画像の明るさを統計してみる
Section titled “九、小さな実験: 画像の明るさを統計してみる”次の例は、「画像とは数値行列である」という感覚をすぐにつかむのに役立ちます。
import numpy as np
gray = np.array([ [10, 20, 30], [100, 120, 140], [200, 220, 240]], dtype=np.uint8)
print("最も暗いピクセル:", gray.min())print("最も明るいピクセル:", gray.max())print("平均の明るさ:", gray.mean())実行結果の例:
最も暗いピクセル: 10最も明るいピクセル: 240平均の明るさ: 120.0これは視覚タスクでよく使われます。たとえば:
- 画像全体が暗すぎないかを判断する
- 明るさの正規化をする
- 露出状態を推定する
十、初心者がよくやる間違い
Section titled “十、初心者がよくやる間違い”画像は「オブジェクト」であって「配列」ではないと思ってしまう
Section titled “画像は「オブジェクト」であって「配列」ではないと思ってしまう”人にとってはオブジェクトですが、コンピュータにとってはまず配列です。 この点を先に受け入れると、あとで出てくる視覚アルゴリズムがずっと理解しやすくなります。
画像の shape を混同する
Section titled “画像の shape を混同する”ライブラリによって約束が違うことがあります。
- NumPy / OpenCV ではよく
H x W x C - PyTorch ではよく
C x H x W
これは後でモデルを書くときに、特に注意が必要な点です。
RGB と HSV は名前が違うだけだと思ってしまう
Section titled “RGB と HSV は名前が違うだけだと思ってしまう”違います。 これは別の色表現方式であり、向いている処理タスクも異なります。
このページを終えたら、この evidence card を残します。
- 入力画像
- 実行で使うソース画像または生成画像
- 配列形状
- 幅、高さ、channels、dtype、座標規約
- 処理済み出力
- グレースケール、切り抜き、エッジ、しきい値処理、または保存済み中間画像
- 失敗確認
- チャネル順、リサイズの歪み、座標ミス、または過剰処理
- 期待される成果
- 前後の画像と、出力された shape またはピクセル値
この節を学んだら、次の大事な直感を持てるようにしましょう。
画像は不思議なものではなく、本質的には空間構造を持った数字の行列である。
これから先、OpenCV の処理でも、畳み込みニューラルネットワークでも、物体検出でも、本質的にはこの構造を持った数字を扱っていくことになります。
- 自分で
3x3のグレースケール画像行列を作り、最大値、最小値、平均値を求めてみましょう。 - 自分で
2x2x3の RGB 画像を作り、各チャンネルを表示してみましょう。 - いくつかの RGB ピクセルを手で
0~1の浮動小数に変換し、正規化の意味を理解しましょう。
解法と解説
- よい
3x3グレースケール画像の答えでは、まず(3, 3)の配列を作り、min()、max()、mean()で画素値を確認します。行列がuint8なら画素値は0-255の範囲に収まり、平均値は浮動小数として表示されることがあります。 - RGB 画像の期待される形状は
(2, 2, 3)です。rgb[:, :, 0]、rgb[:, :, 1]、rgb[:, :, 2]はそれぞれ2x2のチャンネル行列になります。 - 正規化は各チャンネル値を
255.0で割ることです。色の相対関係は変わりませんが、数値範囲が0-1になり、モデルや後続処理で扱いやすくなります。