11.4.3 HMM、CRF と系列ラベリングの歴史の主線
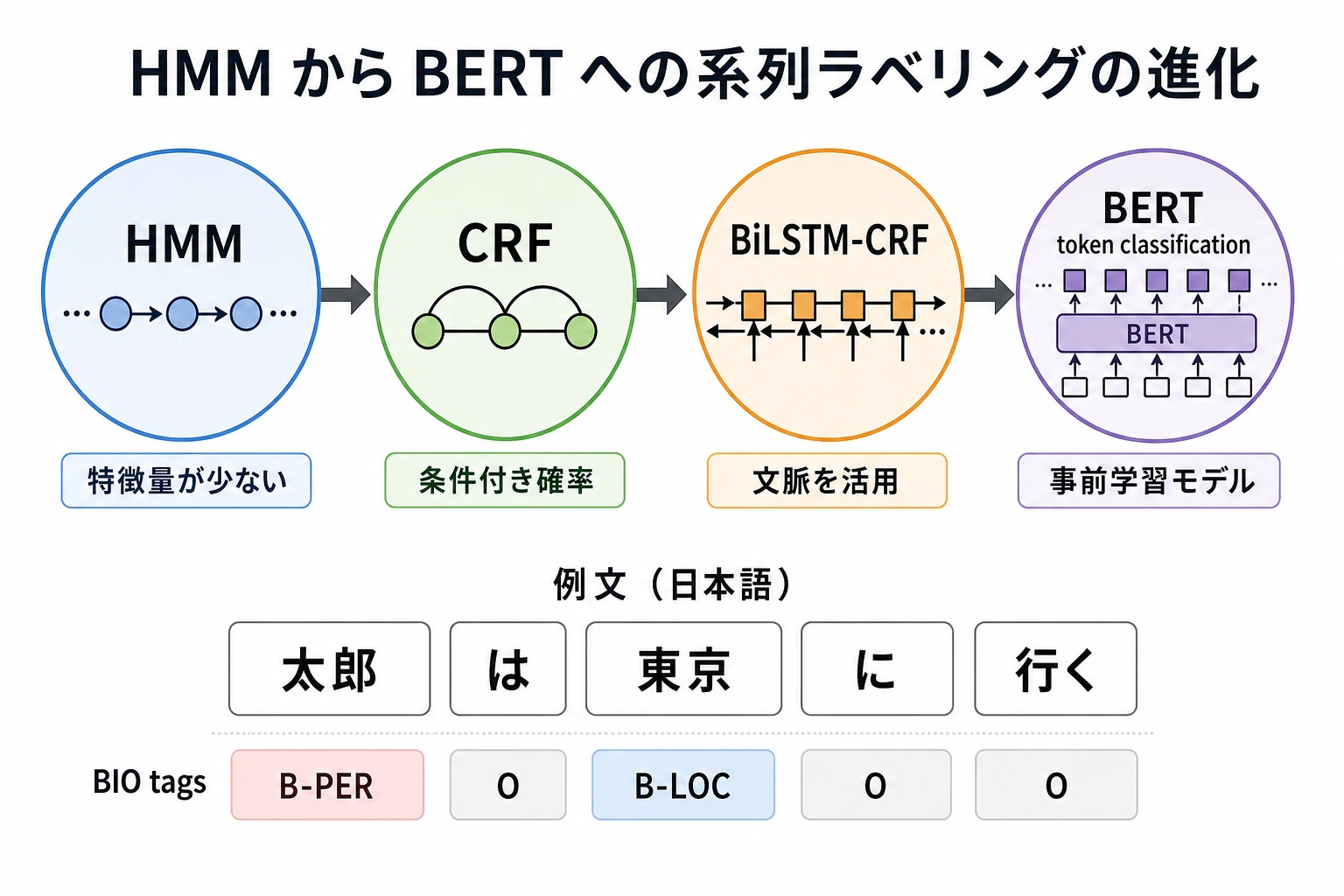
一、系列ラベリングは何がそんなに難しいのか?
Section titled “一、系列ラベリングは何がそんなに難しいのか?”系列ラベリングは、文全体に 1 つのラベルを付けるのではなく、各位置にラベルを付けるタスクです。
たとえば固有表現認識では、次のようになります。
ジョブズ 創業 アップルB-PER O B-ORG難しいのは、各位置のラベルが完全に独立ではないことです。
たとえば:
I-PERは、文頭にいきなり現れることは通常ありませんB-ORGの後にI-ORGが続くことはあります- 中国語の分かち書き、品詞タグ付け、NER はどれも文脈に依存します
つまり、この歴史の流れはずっと同じ問題を解いてきました。
どうすれば、現在の token を見つつ、前後の文脈も考え、しかもラベル列全体を自然なものにできるのか?
二、HMM:初期の統計的系列モデリングの代表的な出発点
Section titled “二、HMM:初期の統計的系列モデリングの代表的な出発点”HMM は、「隠れ状態が観測される単語を生成する」モデルと考えることができます。
品詞タグ付けでは:
- 隠れ状態:品詞ラベル。たとえば名詞、動詞、形容詞
- 観測結果:実際に現れた単語
HMM では、次の 2 つを考えます。
| 問題 | HMM での名前 |
|---|---|
| ある品詞の後に、どの品詞が続きやすいか? | 遷移確率 |
| ある品詞が、ある単語を生成しやすいか? | 出力確率 |
| ある品詞の後に、どの品詞が続きやすいか? | 遷移確率 |
| ある品詞が、ある単語を生成しやすいか? | 出力確率 |
最も有名なデコード方法は Viterbi です。 各位置ごとに独立して最大確率を選ぶのではなく、文全体で最もありそうなラベル経路を探します。
三、CRF:「ラベル列全体」を直接スコアリングする
Section titled “三、CRF:「ラベル列全体」を直接スコアリングする”HMM は非常にクラシックですが、生成モデルとしての仮定が比較的強いです。 CRF は、より直接に次の問いに答えます。
この文が与えられたとき、どのラベル列全体が最も自然か?
NER では、ラベル間に制約があるため、これはとても重要です。
たとえば:
B-PER -> I-PER 自然O -> I-PER 通常は不自然CRF の価値はここにあります。 つまり、単に「この token は実体っぽいか」を見るだけでなく、「ラベル列全体が正しいか、つながりが滑らかか」 も同時に見ます。
四、BiLSTM-CRF:文脈表現 + ラベル制約
Section titled “四、BiLSTM-CRF:文脈表現 + ラベル制約”その後、深層学習が NLP に入ってくると、BiLSTM が文脈を読み取り、CRF が全体のラベル経路を選びます。
役割分担として見ると、次のようになります。
| モジュール | 何を担当するか |
|---|---|
| Embedding | 単語をベクトルに変換する |
| BiLSTM | 左右両方の文脈を見る |
| CRF | 最も自然なラベル列を選ぶ |
そのため、初期の NER システムでは BiLSTM-CRF がよく使われました。
五、BERT の後でも、HMM/CRF を学ぶ意味はあるのか?
Section titled “五、BERT の後でも、HMM/CRF を学ぶ意味はあるのか?”あります。理由は、プロジェクトで HMM を自分で実装する必要があるからではありません。
- HMM は「系列状態」と「経路デコード」の考え方を理解する助けになります
- CRF は「ラベル間に制約がある」ことを理解する助けになります
- BiLSTM-CRF は「文脈表現 + 構造化出力」を理解する助けになります
- BERT token classification は「より強い表現で一部の特徴設計を置き換えられる」ことを理解する助けになります
現代のプロジェクトでは、BERT が強力な token 表現をそのまま作ってくれることが多いです。 ただし、データが少ないとき、ラベル規則が厳密なとき、境界が間違いやすいときには、CRF の考え方は今でも価値があります。
六、歴史上の節目を授業の章に対応づける
Section titled “六、歴史上の節目を授業の章に対応づける”| 歴史上の節目 | 解決した問題 | 対応する授業章 |
|---|---|---|
| HMM による品詞タグ付け | 隠れ状態と遷移確率でラベル列をモデル化する | 4.5 本節、4.2 系列ラベリングタスク |
| Viterbi デコード | 文全体で最もありそうなラベル経路を探す | 4.5 本節、4.3 BiLSTM + CRF |
| CRF | 入力が与えられたときにラベル経路全体を直接モデル化する | 4.3 BiLSTM + CRF |
| BiLSTM-CRF | 文脈表現とラベル制約を組み合わせる | 4.3 BiLSTM + CRF、4.4 NER 実践 |
| BERT token classification | 事前学習済みの文脈表現で token レベルのタスクを解く | 6.3 BERT、7 大規模モデル基礎 |
七、最小限の直感をつかむ例
Section titled “七、最小限の直感をつかむ例”以下は完全な HMM ではありませんが、「遷移制約」の感覚をつかむためのものです。
labels = ["B-PER", "I-PER", "O"]
allowed = { "B-PER": ["I-PER", "O"], "I-PER": ["I-PER", "O"], "O": ["B-PER", "O"],}
path = ["O", "I-PER"]
if path[1] not in allowed[path[0]]: print("このラベル経路は不自然です")else: print("このラベル経路は許容できます")実行結果の例:
このラベル経路は不自然ですI-PER は、すでに始まっている人物エンティティを続けるためのタグです。O の直後に突然出るとラベルの文法が崩れます。このような制約を見えるようにするのが、HMM/CRF 的な考え方の大事な価値です。
このコードが伝えたいのは、 系列ラベリングでは、各 token をバラバラに判定するのではなく、ラベル同士にも「文法」があるということです。
八、この節を学んだあとに持っておきたい直感
Section titled “八、この節を学んだあとに持っておきたい直感”系列ラベリングの歴史は BERT から始まったわけではありません。 大まかには次のように進化してきました。
それぞれの世代が、同じ問いに答えようとしてきました。
どうすれば、各位置のラベルを文脈に合うものにしつつ、ラベル列全体も自然にできるのか?
このページを終えたら、この evidence card を残します。
- スキーマ
- エンティティ型、BIO タグ、またはシーケンスラベル規則
- 予測
- トークン単位のラベルと抽出スパン
- 指標
- エンティティの precision/recall/F1 と境界ケース
- 失敗確認
- span 境界、入れ子のエンティティ、未知語、または不一致なアノテーション
- 期待される成果
- 少なくとも1つの miss がある、gold と predicted の span 表
レビュー観点と通過基準
- 合格の目安は、token labels が独立した判断ではない理由を説明できることです。local evidence と label-transition constraints の両方を含めます。
O -> I-PERのような invalid BIO path を少なくとも 1 つ試し、その誤りが representation、decoding、annotation rules のどこから来るかを説明します。- BERT token classification の出力と rule-checked span table を横に並べて確認します。高信頼でも illegal path なら、structured check が検出できる必要があります。
- main model が modern pretrained encoder でも、CRF-style constraint が役に立つ場面を説明できれば、このページは完了です。