6.8.3 プロジェクト:テキスト感情分析
- モデルを選ぶ前に感情ラベルを定義できる。
- 説明しやすいキーワード基準モデルを作れる。
- シンプルな否定語ルールで 1 つの既知エラータイプを改善できる。
- 誤予測をエラー分類に整理できる。
- 小さな NLP プロジェクトを再現可能な成果物としてまとめられる。
まずプロジェクトの流れを見る
Section titled “まずプロジェクトの流れを見る”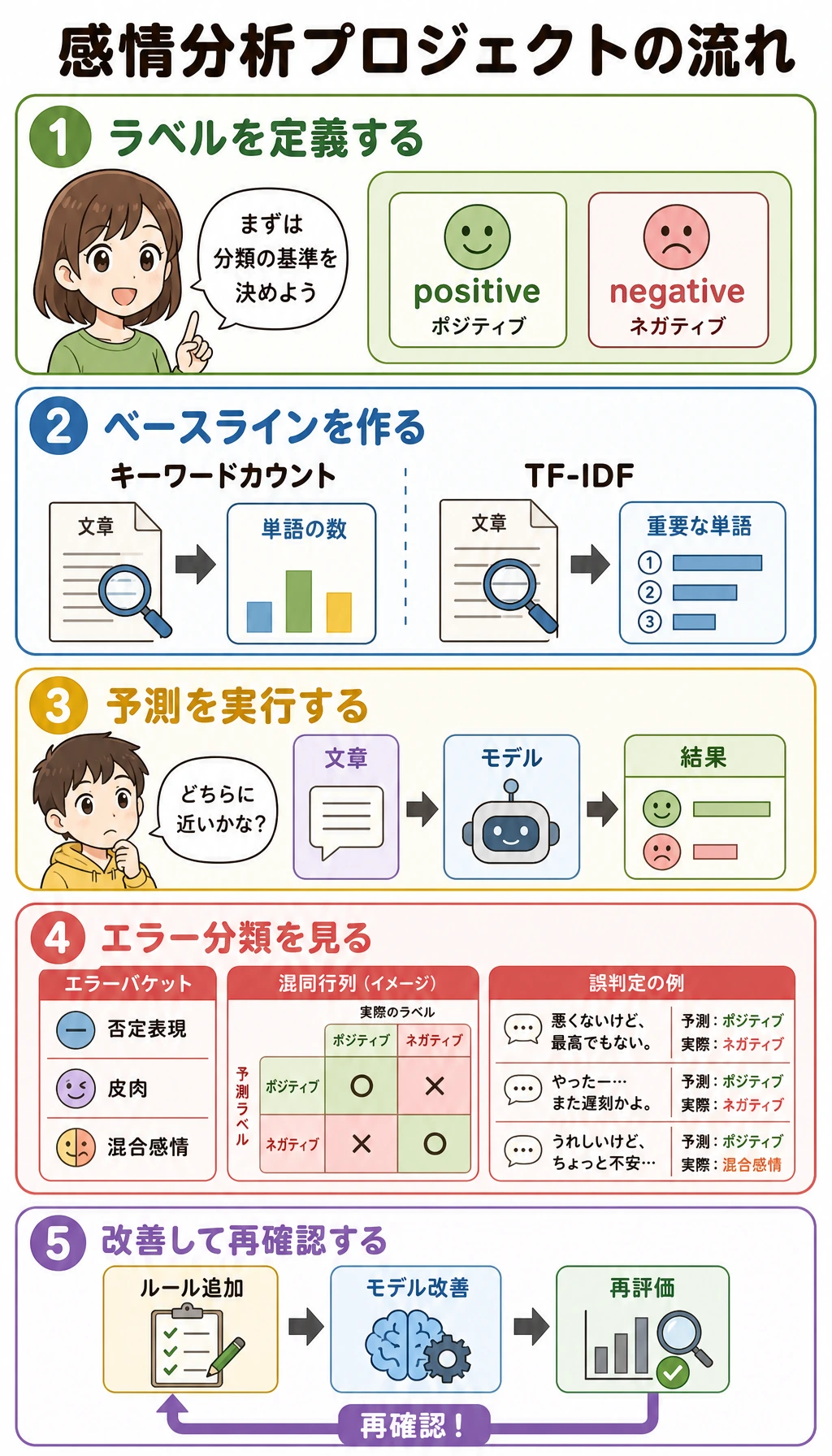
label boundarybaselinepredictionserror bucketstargeted upgrade
まずは二値ラベルから始めます。
positive:明確に推薦、称賛、満足を表す。negative:明確に不満、拒否、苦情を表す。
基本ループが安定する前に、neutral、mixed、irony、unclear などを増やしすぎないでください。
実験:キーワード基準モデルと否定語ルール修正
Section titled “実験:キーワード基準モデルと否定語ルール修正”sentiment_project_baseline.py を作成します。
from collections import Counter
def tokenize(text): text = text.lower() for ch in ",.!?": text = text.replace(ch, "") return text.split()
train = [ ("clear examples and practical pace", "positive"), ("recommended and systematic course", "positive"), ("messy confusing and too fast", "negative"), ("unclear examples and weak structure", "negative"),]
val = [ ("clear and practical course", "positive"), ("messy and confusing pace", "negative"), ("not recommended", "negative"),]
positive_words = Counter()negative_words = Counter()
for text, label in train: if label == "positive": positive_words.update(tokenize(text)) else: negative_words.update(tokenize(text))
positive_words.update(["recommended"] * 2)negative_words.update(["messy"] * 2)
def predict(text): score = sum(positive_words[t] - negative_words[t] for t in tokenize(text)) return ("positive" if score >= 0 else "negative"), score
def predict_with_negation(text): score = 0 flip = False
for token in tokenize(text): if token in {"not", "no", "never"}: flip = True continue
token_score = positive_words[token] - negative_words[token] if flip and token_score != 0: token_score *= -1 flip = False
score += token_score
return ("positive" if score >= 0 else "negative"), score
print("sentiment_baseline")for text, gold in val: pred, score = predict(text) print({"gold": gold, "pred": pred, "score": score, "text": text})
print("with_negation")for text, gold in val: pred, score = predict_with_negation(text) print({"gold": gold, "pred": pred, "score": score, "text": text})実行します。
python sentiment_project_baseline.py期待される出力:
sentiment_baseline{'gold': 'positive', 'pred': 'positive', 'score': 3, 'text': 'clear and practical course'}{'gold': 'negative', 'pred': 'negative', 'score': -3, 'text': 'messy and confusing pace'}{'gold': 'negative', 'pred': 'positive', 'score': 3, 'text': 'not recommended'}with_negation{'gold': 'positive', 'pred': 'positive', 'score': 3, 'text': 'clear and practical course'}{'gold': 'negative', 'pred': 'negative', 'score': -3, 'text': 'messy and confusing pace'}{'gold': 'negative', 'pred': 'negative', 'score': -3, 'text': 'not recommended'}
このコードで学ぶこと:
- 基準モデルは、各 token が score を変えるので説明しやすい。
not recommendedは否定語ルールの前では失敗する。- 狙いを絞ったルールは 1 つのエラータイプを直せるが、言語理解全体を解いたわけではない。
誤分類例は隠さず、タイプごとにまとめます。
error_buckets = { "negation": [], "sarcasm": [], "mixed_sentiment": [], "other": [],}
examples = [ ("Not recommended for this course", "negative", "positive"), ("Great, it got stuck again", "negative", "positive"), ("The content is great, but the pace is too fast", "negative", "positive"),]
for text, gold, pred in examples: lower = text.lower() if "not" in lower: error_buckets["negation"].append(text) elif "great" in lower and "again" in lower: error_buckets["sarcasm"].append(text) elif "but" in lower: error_buckets["mixed_sentiment"].append(text) else: error_buckets["other"].append(text)
for name, rows in error_buckets.items(): print(name, len(rows), rows)これはプロジェクトの証拠です。モデルがどこで失敗し、次に何を改善すべきかを示します。
| バージョン | 追加するもの | 理由 |
|---|---|---|
| ルール基準モデル | キーワード数と否定語ルール | 説明しやすい出発点 |
| 伝統的機械学習 | TF-IDF + LogisticRegression | 低コストで強い基準モデル |
| ニューラル基準モデル | embedding + pooling または小さな Transformer | 表現特徴を学ぶ |
| 成果物版 | エラー分類、比較表、デモコマンド | エンジニアリング判断を示す |
README に見せるもの
Section titled “README に見せるもの”README は具体的にします。
- ラベル定義。
- データセットの出典と分割。
- 実行コマンド。
- 基準モデルの比較表。
- エラー分類。
- モデルが正解した例と間違えた例。
- 次の改善計画。
感情分析プロジェクトでは、最低限この証拠を残します。
- ラベル規則
- 正例と負例の境界
- ベースライン
- keyword または TF-IDF のベースライン
- 既知の失敗
- 否定、皮肉、または混合感情
- 修正試行
- 1つの対象ルールまたはモデル変更
- エラーバケット
- まとめられた誤予測
- 次の行動
- データラベル付け、特徴量、またはモデルアップグレード
よくある間違い
Section titled “よくある間違い”| 間違い | 直し方 |
|---|---|
| ラベルが曖昧 | 学習前にラベルルールを書く |
| accuracy だけ報告する | エラー分類と例を含める |
| 否定語を無視する | not、never、no のケースをテストする |
| 深層モデルを早く入れすぎる | ルールまたは TF-IDF の基準モデルを残す |
| 皮肉や混合感情のエラーを隠す | 既知の制約として記録する |
"not clear"と"never useful"を検証例に追加してください。- ルールでは分類できない
otherの分類例を追加してください。 - プロジェクト計画でキーワード数を TF-IDF に置き換えてください。
neutralのラベルルールを書いてください。ただしモデルにはまだ追加しないでください。- このプロジェクトの README アウトラインを作ってください。
プロジェクト参考とレビュー観点
"not clear"は neutral または uncertain に近く、"never useful"は negative と考えるのが自然です。この 2 つは否定表現と弱い感情を扱えるかの確認になります。- よい
other例は、皮肉、言語の混在、配送や価格の話で感情が明確でない文などです。曖昧な入力を無理に間違ったラベルへ入れないことが目的です。 - TF-IDF は classifier の前の feature extraction step になります。計画には vocabulary、vectorization、train/validation split、metrics を書きます。
- 単純な
neutralルールとして、強い positive/negative keyword がない文、または正負の手がかりが相殺される文を扱えます。評価できるまではモデルに混ぜず分けておきます。 - README には task definition、labels、dataset examples、baseline、metric、error examples、次の model upgrade を含めます。
- 感情分析プロジェクトはラベル境界とエラー分析で決まります。
- 単純な基準モデルは説明しやすいので有用です。
- 否定表現は古典的な最初の失敗タイプです。
- エラー分類は単一の正解率よりプロジェクトの価値を見せられます。