7.8.2 プロジェクト:垂直領域のファインチューニング
- 「領域ファインチューニング」の題材を、実行可能なプロジェクトまで絞り込めるようになる
- 元の知識を整理して、SFT データと評価セットを作れるようになる
- 本当に説得力のある ベースライン 比較ができるようになる
- このプロジェクトを作品レベルのページとして見せられるようになる
一、なぜプロジェクトの題材は先に絞る必要があるのか?
Section titled “一、なぜプロジェクトの題材は先に絞る必要があるのか?”大きすぎる題材は、ほとんど進められない
Section titled “大きすぎる題材は、ほとんど進められない”たとえば:
- 業界の専門家 LLM を作る
このような題材は境界が広すぎて、
次の点をはっきりさせにくいです。
- 入力は何か
- 出力は何か
- 何をもって正解とするか
ポートフォリオに向いている題材
Section titled “ポートフォリオに向いている題材”たとえば:
EC のアフターサービス方針アシスタント:返金、住所変更、請求書、アフターサービス手続きの 4 種類の質問に絞る。
この題材の良いところは:
- 範囲が狭い
- 意味が安定している
- 評価基準を設計しやすい
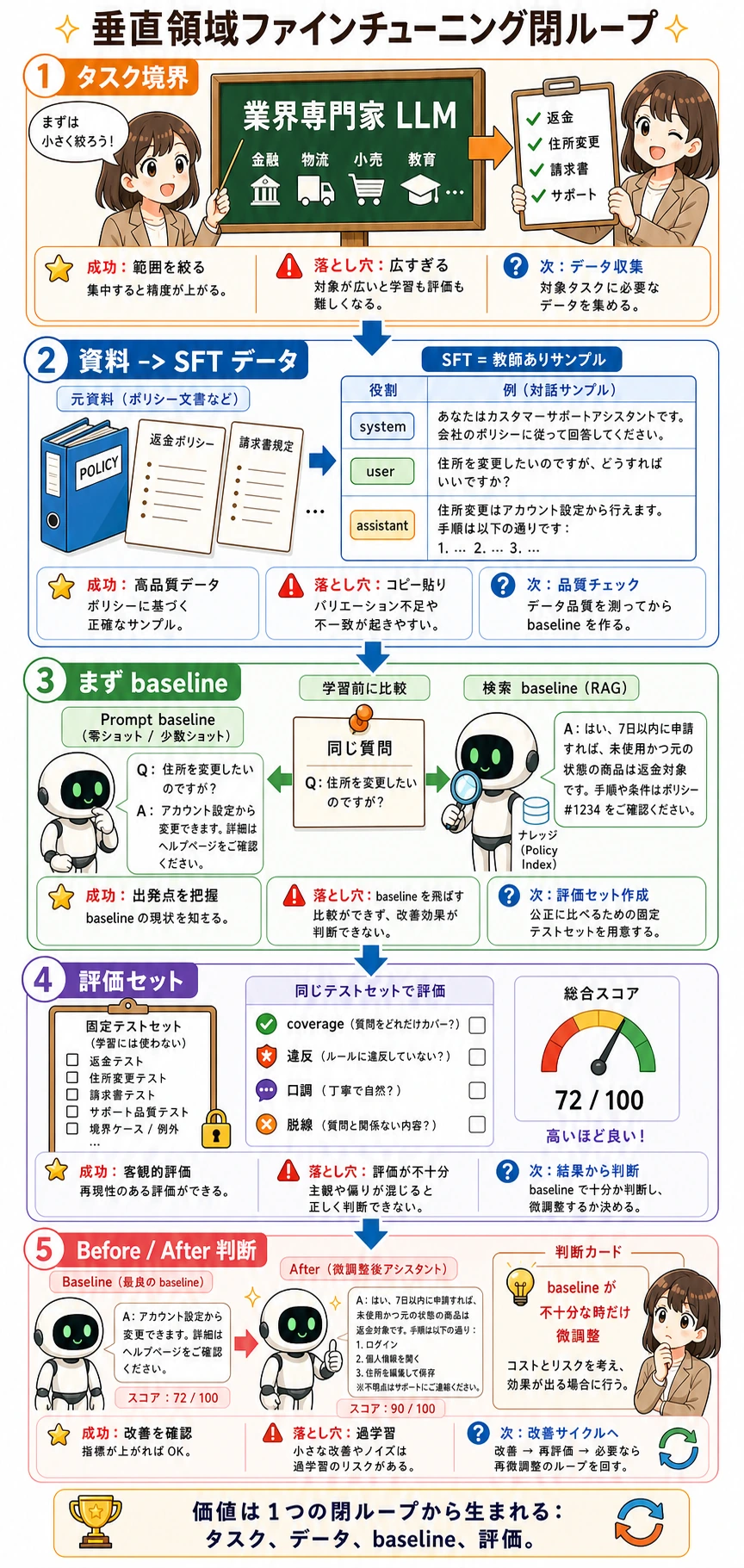
二、作品レベルのファインチューニング・プロジェクトの最小ループは?
Section titled “二、作品レベルのファインチューニング・プロジェクトの最小ループは?”- タスクの境界を決める
- 知識と会話サンプルを整理する
- ベースライン を作る
- SFT データを整理する
- 評価セットを作る
- 学習して before/after 比較を行う
この 6 ステップがはっきりしていれば、プロジェクトはかなり説得力のあるものになります。
三、おすすめの進め方
Section titled “三、おすすめの進め方”初心者にとって、より安定しやすい順番は通常こうです。
- まず題材の範囲を絞る
- 次に Prompt / 検索 ベースライン を作る
- その後で SFT データを整理する
- 最後にファインチューニングと before/after 比較を行う
こうすると、プロジェクトが「何となく微調整したもの」ではなく、「判断した上で微調整したもの」に見えます。
コードを読む前に押さえたいプロジェクト用語
Section titled “コードを読む前に押さえたいプロジェクト用語”| 用語 | 初心者向けの意味 | この節での役割 |
|---|---|---|
| LLM | Large Language Model、大規模言語モデル。token を1つずつ予測しながら文章を生成するモデル | このプロジェクトでは、LLM の領域タスクでの振る舞いを調整する |
| Prompt | 推論時にモデルへ渡す指示、文脈、制約 | 追加学習より低コストなので、最初の ベースライン になる |
| RAG | Retrieval-Augmented Generation、回答前に外部資料を検索してから生成する方法 | 最新知識や社内資料が足りないときに役立つ |
| ファインチューニング | タスク専用サンプルでモデルを追加学習すること | 文体、形式、判断パターンを安定させたいときに価値がある |
| SFT | Supervised Fine-Tuning、整理済みの入力/出力例で行う教師あり微調整 | モデルに「良い回答の形」を教える |
| ベースライン | 高度な方法の前に作る、最も簡単な比較対象 | 根拠なしに「改善した」と言わないために必要 |
| 評価セット | 学習には使わない固定のテスト質問セット | 新しい方法が未見のケースにも効くかを確認する |
| coverage | 必須ポリシー点をどれだけ回答に含めたか | 「良さそう」を、より測れるスコアに変える |
四、まずは、より完全なデータと ベースライン の例を見てみよう
Section titled “四、まずは、より完全なデータと ベースライン の例を見てみよう”次の例では、以下を同時に示します。
- 元データ
- SFT サンプル
- 2 種類の ベースライン
- 評価ルール
このコードは Python 標準ライブラリだけで動きます。domain_finetune_demo.py として保存し、python domain_finetune_demo.py で実行できます。
raw_records = [ { "intent": "refund_unshipped", "question": "注文がまだ発送されていませんが、そのまま返金できますか?", "policy_points": ["未発送なら直接返金申請できる", "返金は元の支払い方法に戻る", "着金は通常 3〜7 営業日"], "evaluation_keywords": [["未発送", "発送されていない"], ["元の支払い方法"], ["3〜7", "営業日"]], "answer": "はい。注文がまだ発送されていない場合は、そのまま返金を申請できます。代金は元の支払い方法に返金され、通常 3〜7 営業日で反映されます。", }, { "intent": "change_address", "question": "受け取り住所を間違えました。変更できますか?", "policy_points": ["出庫前なら住所変更可能", "出庫後は有人サポートに連絡"], "evaluation_keywords": [["出庫前"], ["有人サポート", "出庫済み"]], "answer": "注文がまだ出庫前であれば、注文詳細ページから住所を変更できます。すでに出庫済みの場合は、有人サポートまでご連絡ください。", }, { "intent": "invoice", "question": "請求書はいつ発行できますか?", "policy_points": ["注文完了後に申請可能", "電子請求書はメール送付"], "evaluation_keywords": [["注文完了"], ["電子請求書", "メール"]], "answer": "注文完了後に請求書センターから発行を申請できます。電子請求書は登録済みのメールアドレスに送信されます。", },]
def build_sft_record(row): system = "あなたは EC のアフターサービス方針アシスタントです。丁寧で正確、かつプラットフォーム規則に沿ってユーザーの質問に答えてください。" return { "messages": [ {"role": "system", "content": system}, {"role": "user", "content": row["question"]}, {"role": "assistant", "content": row["answer"]}, ], "intent": row["intent"], "policy_points": row["policy_points"], }
def generic_baseline(question): if "返金" in question: return "一般的には返金申請は可能です。詳細は注文状況によります。" if "住所" in question: return "住所の問題は、できるだけ早くサポートへ連絡することをおすすめします。" if "請求書" in question: return "請求書は通常申請できます。詳しくは画面の案内をご確認ください。" return "サポート窓口へお問い合わせください。"
def retrieval_baseline(question, records): best = max(records, key=lambda row: overlap(question, row["question"])) return best["answer"]
def tokenize(text): punctuation = "、。!?;:「」『』()()[]{}" words = [char.strip(punctuation) for char in text] return {word for word in words if word}
def overlap(a, b): return len(tokenize(a) & tokenize(b))
def coverage(answer, required_keyword_groups): matched = [ group for group in required_keyword_groups if any(keyword in answer for keyword in group) ] return round(len(matched) / len(required_keyword_groups), 3)
sft_dataset = [build_sft_record(row) for row in raw_records]sample = raw_records[0]
generic_answer = generic_baseline(sample["question"])retrieval_answer = retrieval_baseline(sample["question"], raw_records)
print("question:", sample["question"])print("generic :", generic_answer, "coverage=", coverage(generic_answer, sample["evaluation_keywords"]))print("retrieval:", retrieval_answer, "coverage=", coverage(retrieval_answer, sample["evaluation_keywords"]))print("sft_sample:", sft_dataset[0])期待される出力は次のとおりです。
question: 注文がまだ発送されていませんが、そのまま返金できますか?generic : 一般的には返金申請は可能です。詳細は注文状況によります。 coverage= 0.0retrieval: はい。注文がまだ発送されていない場合は、そのまま返金を申請できます。代金は元の支払い方法に返金され、通常 3〜7 営業日で反映されます。 coverage= 1.0sft_sample: {'messages': [{'role': 'system', 'content': 'あなたは EC のアフターサービス方針アシスタントです。丁寧で正確、かつプラットフォーム規則に沿ってユーザーの質問に答えてください。'}, {'role': 'user', 'content': '注文がまだ発送されていませんが、そのまま返金できますか?'}, {'role': 'assistant', 'content': 'はい。注文がまだ発送されていない場合は、そのまま返金を申請できます。代金は元の支払い方法に返金され、通常 3〜7 営業日で反映されます。'}], 'intent': 'refund_unshipped', 'policy_points': ['未発送なら直接返金申請できる', '返金は元の支払い方法に戻る', '着金は通常 3〜7 営業日']}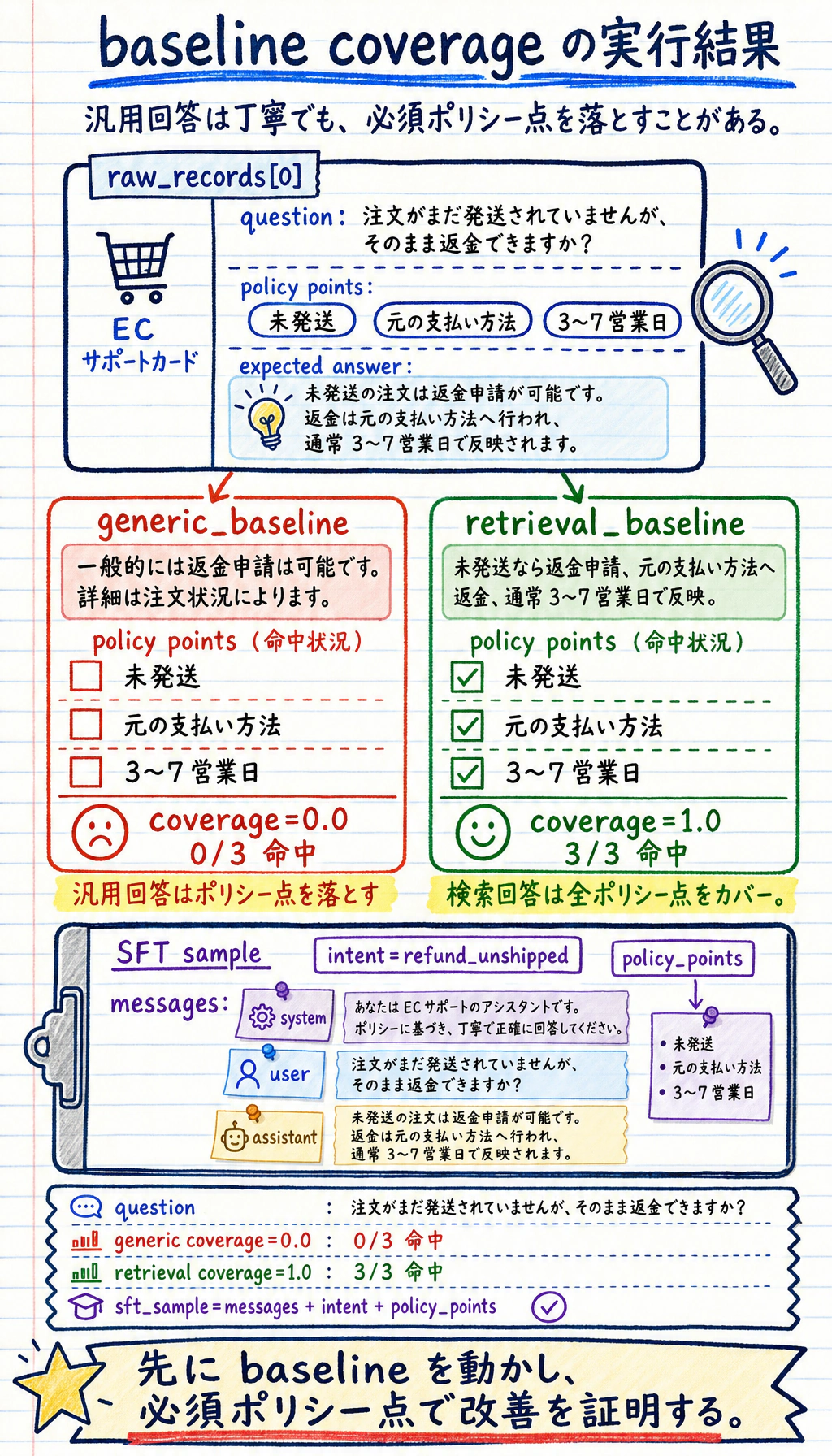
この小さなコードの目的は、本番レベルの検索システムを作ることではありません。比較を見える形にすることです。汎用回答は丁寧に聞こえても、必須のポリシー詳細を落とすことがあります。一方、領域に合った回答は、固定した必須点に照らして確認できます。
この例が、単なる「プロジェクト案」より価値がある理由
Section titled “この例が、単なる「プロジェクト案」より価値がある理由”なぜなら、プロジェクトで本当に重要な 4 つが、すでに入っているからです。
- 元データがどんな形か
- SFT サンプルがどんな形か
- ベースライン の結果が何か
- 評価ルールが何か
これは、実際のファインチューニング・プロジェクトの核にかなり近い形です。

なぜ最初に 2 つの ベースライン を作るのか?
Section titled “なぜ最初に 2 つの ベースライン を作るのか?”少なくとも、次の比較をおすすめします。
- そのままの Prompt / 汎用回答
- 検索 or 簡単な領域マッチ
- ファインチューニング後のシステム
これがないと、あとで次のことを説明しにくくなります。
- ファインチューニングで、何がどれだけ改善したのか
検索がすでに強いなら、いつファインチューニングする価値があるのか?
Section titled “検索がすでに強いなら、いつファインチューニングする価値があるのか?”検索が答えるのは「モデルにどの知識を見せるべきか」です。ファインチューニングが答えるのは別の問いで、「入力を見たあと、モデルがどんな安定した振る舞いをするべきか」です。検索で正しいポリシーを見つけられる場合でも、文体を常にそろえる、意図分類を安定させる、厳密な JSON schema を出す、同じ推論パターンを何度も使う、といった場面ではファインチューニングが価値を持つことがあります。
| 状況 | まず選びたい方法 | 理由 |
|---|---|---|
| 回答が社内資料や頻繁に変わる知識に依存する | RAG | 文書更新のほうが再学習より安全 |
| 回答の文体や構造を安定させたい | ファインチューニング | モデルが繰り返し出る出力パターンを学ぶ |
| タスク定義そのものがあいまい | 先にタスクと Prompt を書き直す | あいまいなサンプルで学習すると、混乱を固定してしまう |
| 出力をコードで安定して解析したい | まず Prompt + スキーマ、その後必要ならファインチューニング | スキーマ 制約で、問題が表現なのか振る舞いなのか見えやすくなる |
| ベースライン がすでに評価を通っている | より単純な方法を残す | 単純で信頼できるシステムのほうが保守しやすい |
五、ファインチューニング・プロジェクトで最も大切な評価は、「専門家っぽく見えるか」だけではない
Section titled “五、ファインチューニング・プロジェクトで最も大切な評価は、「専門家っぽく見えるか」だけではない”構造化された評価ポイント
Section titled “構造化された評価ポイント”少なくとも、次を含めるべきです。
- 重要なポリシー点をカバーしているか
- 禁止された約束をしていないか
- 文体が一貫しているか
- 質問にきちんと答えているか
作品レベルらしい見せ方
Section titled “作品レベルらしい見せ方”最もおすすめなのは、次の形で見せることです。
- 同じ質問セット
- ベースライン の回答
- ファインチューニング後の回答
- 1 つずつ差分を説明する
失敗例はとても重要
Section titled “失敗例はとても重要”たとえば:
- 方針を勝手に作ってしまう
- 細かい点を間違える
- 口調が安定しない
こうした例は、成功例だけを見せるよりも、ずっと実際のプロジェクトらしく見えます。
六、このプロジェクトを作品レベルのページにするには?
Section titled “六、このプロジェクトを作品レベルのページにするには?”おすすめのページ構成
Section titled “おすすめのページ構成”- タスクの境界
- データの作り方
- ベースライン比較
- SFT サンプル例
- 前後比較
- 失敗例
とても評価が高いポイント
Section titled “とても評価が高いポイント”「ポリシー点カバー率」のような、明確なルールを出すことです。
これにより、主観だけに頼らず、プロジェクトがかなりしっかりしたものに見えます。
七、いちばんハマりやすい落とし穴
Section titled “七、いちばんハマりやすい落とし穴”最初から大きすぎる題材を選ぶ
Section titled “最初から大きすぎる題材を選ぶ”これをやると、評価もデータも一緒に拡散してしまいます。
ベースラインがない
Section titled “ベースラインがない”比較対象がなければ、ファインチューニング・プロジェクトはほとんど成立しません。
モデル学習だけを見せて、タスク判断を見せない
Section titled “モデル学習だけを見せて、タスク判断を見せない”プロジェクト提出時に、できれば追加したい内容
Section titled “プロジェクト提出時に、できれば追加したい内容”- タスク境界の表を 1 枚
- ベースライン比較の表を 1 枚
- 前後比較の QA サンプルを 1 セット
- 失敗例と原因分析を 1 セット
- 「なぜここは RAG / Prompt だけではなく、ファインチューニングする価値があるのか」の判断説明
プロジェクトが本当に価値を持つのは、次の部分です。
- 題材の定義
- データの整理
- 評価設計
このページを終えたら、この証拠カードを残します。
- 範囲
- 狭いドメインの挙動と対象ユーザー
- データ
- 例、ラベル規則、品質チェック
- ベースライン
- 微調整前のプロンプト/RAG結果
- 評価
- ドメインケース、失敗サンプル、安全性ケース
- ポートフォリオ
- 決定表と再現可能な実行手順
この節で最も大切なのは、作品レベルの判断軸を作ることです。
垂直領域のファインチューニング・プロジェクトの本当の価値は、「モデルをファインチューニングしたこと」そのものではなく、タスク境界、SFT データ、ベースライン、評価ルール、before/after 比較を 1 本のきれいな閉ループとして説明できるかどうかです。
このループがきちんと見えていれば、このプロジェクトは展示用としてとても向いています。
バージョンの進め方のおすすめ
Section titled “バージョンの進め方のおすすめ”| バージョン | 目標 | 仕上げの重点 |
|---|---|---|
| 基礎版 | 最小ループを動かす | 入力できる、処理できる、出力できる、サンプルを 1 組残す |
| 標準版 | 見せられるプロジェクトにする | 設定、ログ、エラー処理、README、スクリーンショットを追加する |
| チャレンジ版 | ポートフォリオ品質に近づける | 評価、比較実験、失敗サンプル分析、次の方針を追加する |
まずは基礎版を完成させるのがおすすめです。最初から全部入りを目指さなくて大丈夫です。バージョンを 1 つ上げるたびに、「何が増えたのか、どう検証したのか、まだ何が課題か」を README に書きましょう。
- 元データにさらに 5 件サンプルを追加して、4 つの intent がもっと均等になるようにしてみましょう。
- 考えてみましょう:Retrieval ベースライン がすでにかなり良い場合、それでもファインチューニングをする価値があるのは、どんなときでしょうか?
- なぜ「ポリシー点カバー率」は、「なんとなく人間っぽい」という感覚より、プロジェクト評価に向いているのでしょうか?
- もしこのプロジェクトをポートフォリオにするなら、最も見せる価値がある before/after の例は、どの 4 つでしょうか?
プロジェクト参考とレビュー観点
- short、long、ambiguous、noisy wording を含め、各 intent に十分な variation を持たせます。balance は数を同じにするだけでなく、case coverage を増やすことです。
- stable style、domain-specific phrasing、repeated classification pattern、低い prompt complexity、より compact な運用が必要なら、fine-tuning はまだ検討価値があります。
- policy-point coverage rate は必要な内容が入っているかを測ります。「人間らしい」は主観的で、流暢だが不完全な answer を高く評価してしまいます。
- wrong intent、missing policy point、不適切な refusal、不安定な format を直した before/after が有用です。それぞれに evaluation reason を添えます。