7.8.4 実践:第 7 章フルワークショップ
このページは、第 7 章全体をつなぐ実践の主線です。概念が多くて迷ったら、まずこのページを上から下まで一度動かしてください。ここでは大規模モデルを訓練しません。代わりに、token、リクエスト payload、Prompt 版、構造化出力の検証、評価、Prompt/RAG/ファインチューニングの判断、そしてあとで見直せる小さな証拠パックをつなぐ、最小で再現可能な流れを作ります。
最後まで進むと、次のことができる 1 つの Python ファイルが手元に残ります。
- 学習者のリクエストを簡単な tokens、token ids、小さなベクトルの痕跡に変換する。
- 固定テストケースで 3 つの Prompt 版を比較する。
- モデル風の出力が、必須フィールドを持つ本物の JSON か検証する。
- タスクが Prompt、構造化出力、RAG、ファインチューニング計画のどこから始めるべきか判断する。
- token の痕跡、Prompt 評価結果、手法判断、失敗ケース、README を 1 つのローカル証拠フォルダに保存する。
- エンジニアのように出力を説明する。どこで失敗し、なぜ失敗し、次に何を変えるべきかを言えるようにする。
コードは Python 標準ライブラリだけを使います。初回実行で API key、ネットワーク、有料モデルを用意しなくても、先にエンジニアリングの流れを理解できます。
図解チェックポイント:全体ルート
Section titled “図解チェックポイント:全体ルート”コードに入る前に、第 7 章の image2 教材図をこの順番で並べて見てください。これらは装飾ではなく、このワークショップの地図です。
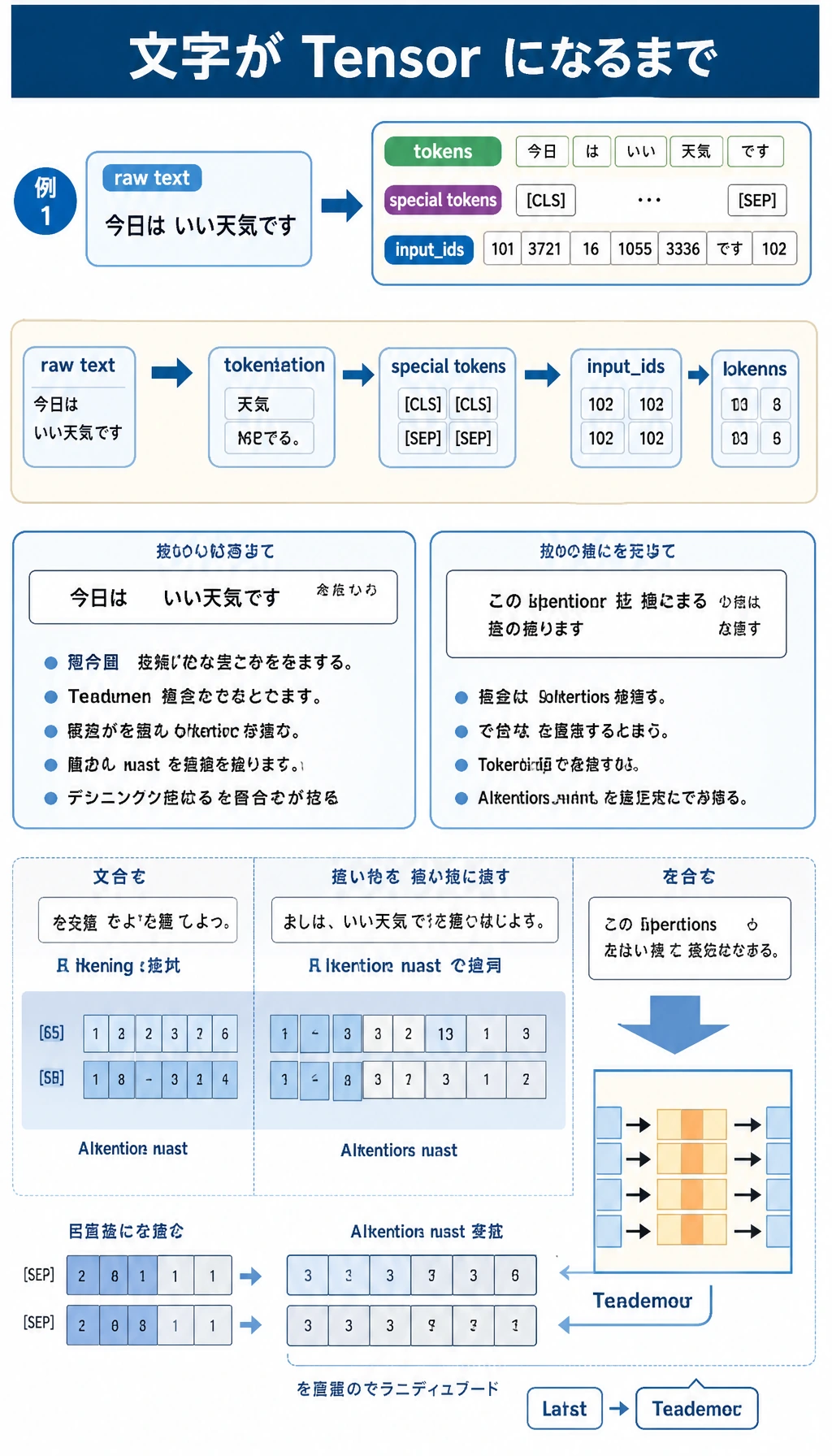
まず、テキストは token と id になってからモデルに入ります。
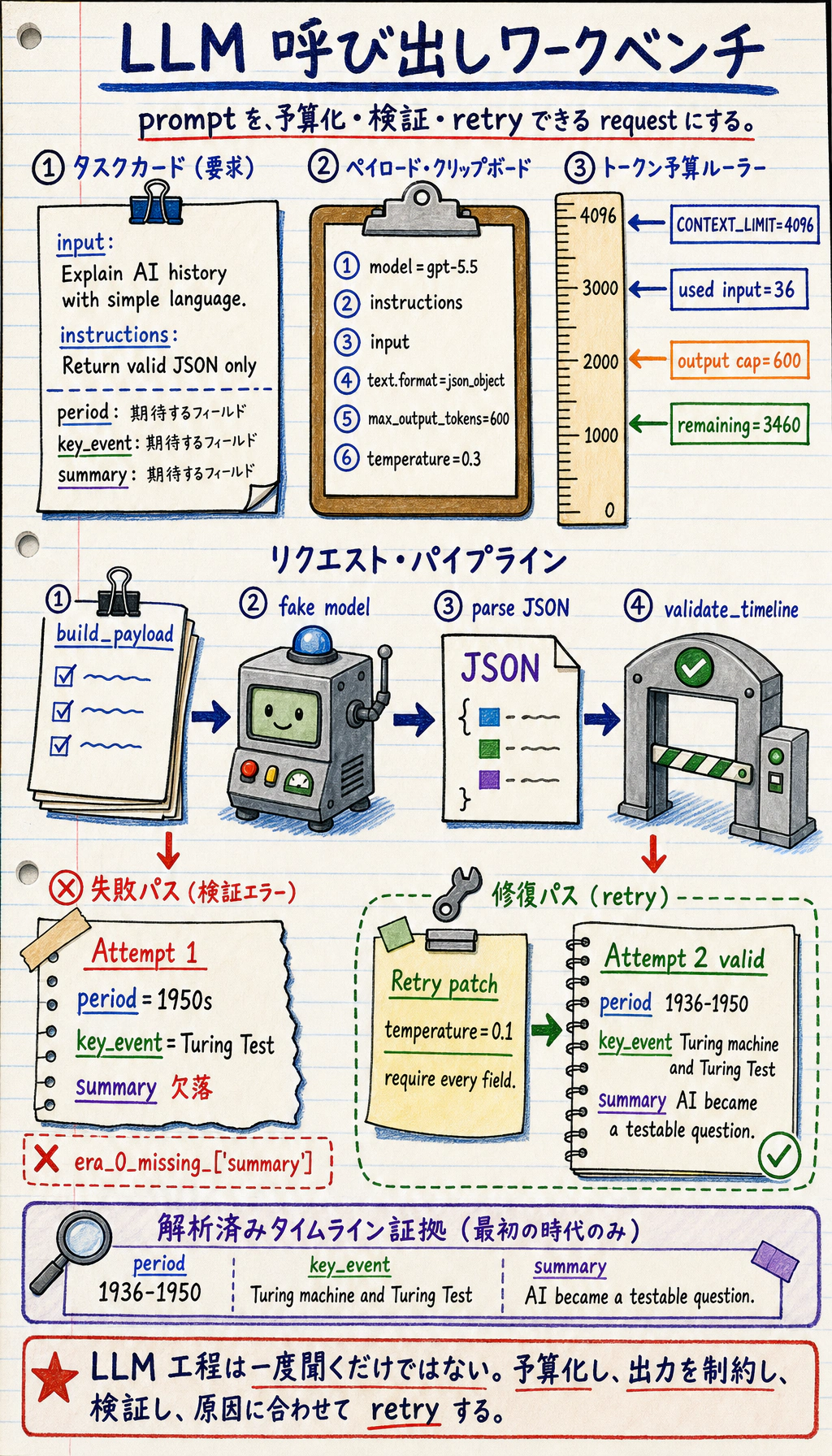
次に、モデル呼び出しはチャット欄の一文ではなく、リクエスト payload です。

その後、プロダクトコードはモデル出力を解析し、検証する必要があります。
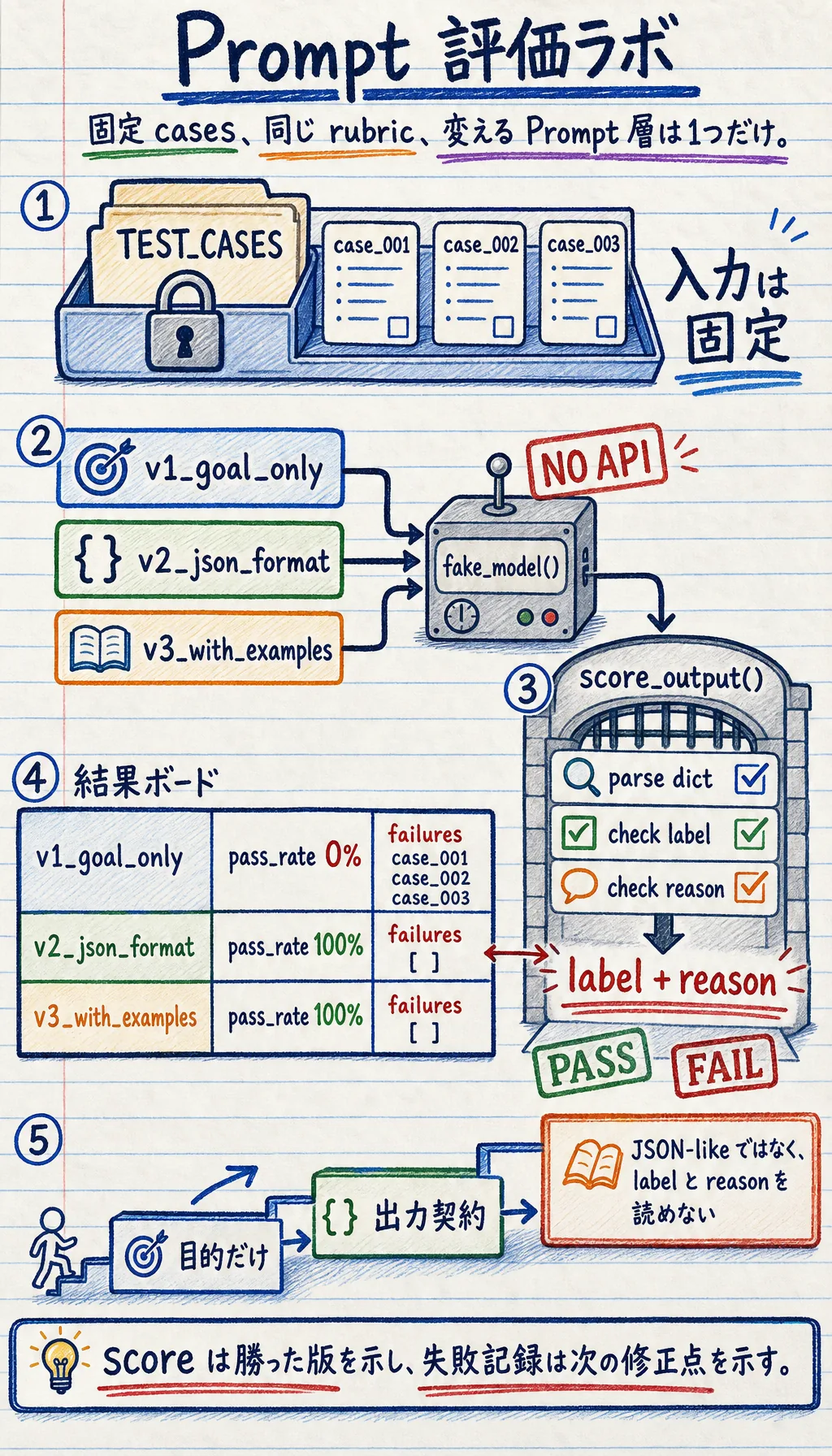
Prompt の変更は、感覚ではなく固定ケースで評価します。
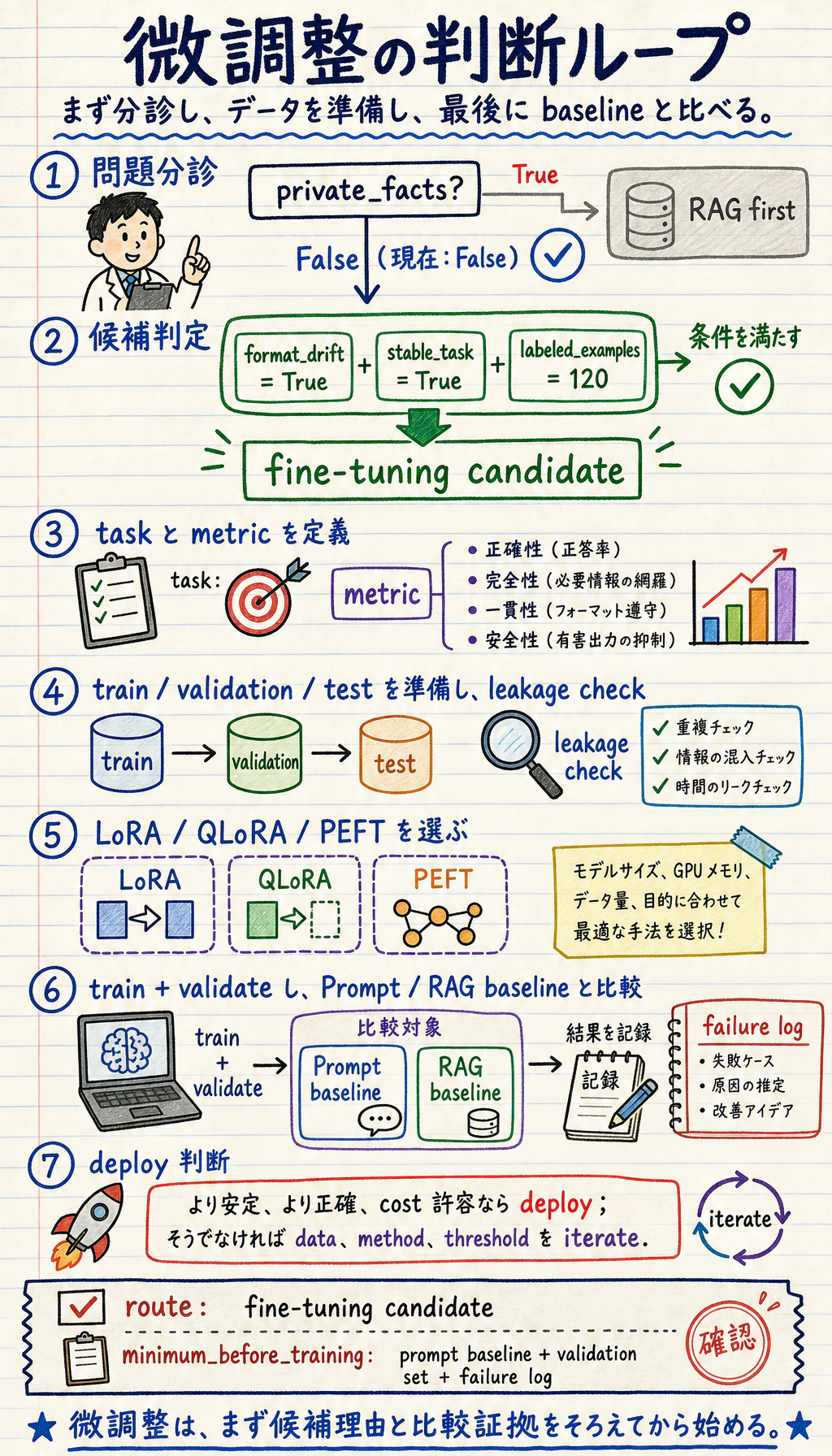
最後に、いきなりファインチューニングへ進まないでください。まず問題の種類を見分けます。
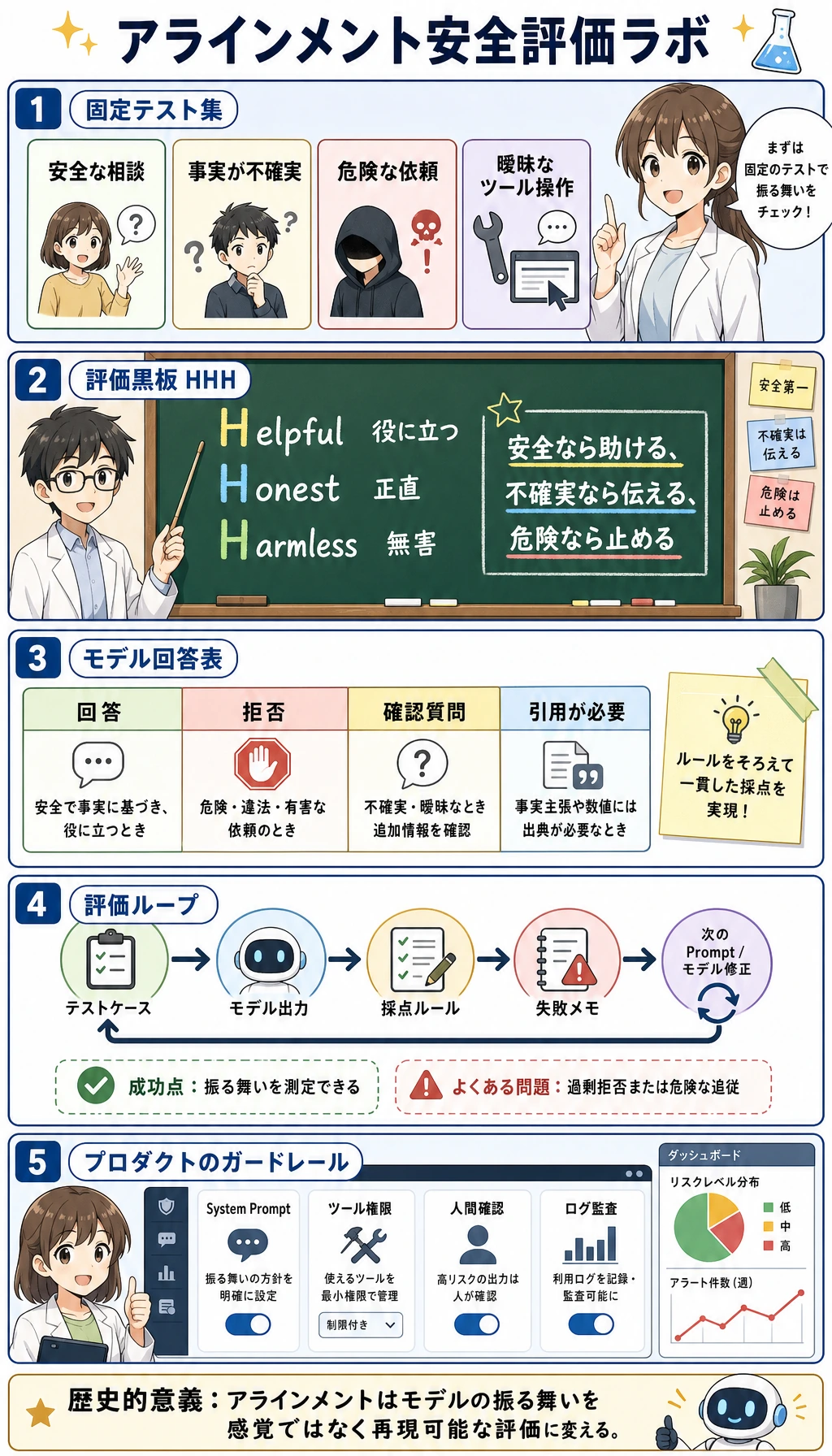
リスクのあるタスクでは、ふるまい評価と人間のレビュー境界を追加します。
次の図は、このワークショップ専用の実行チェックリストとして使ってください。
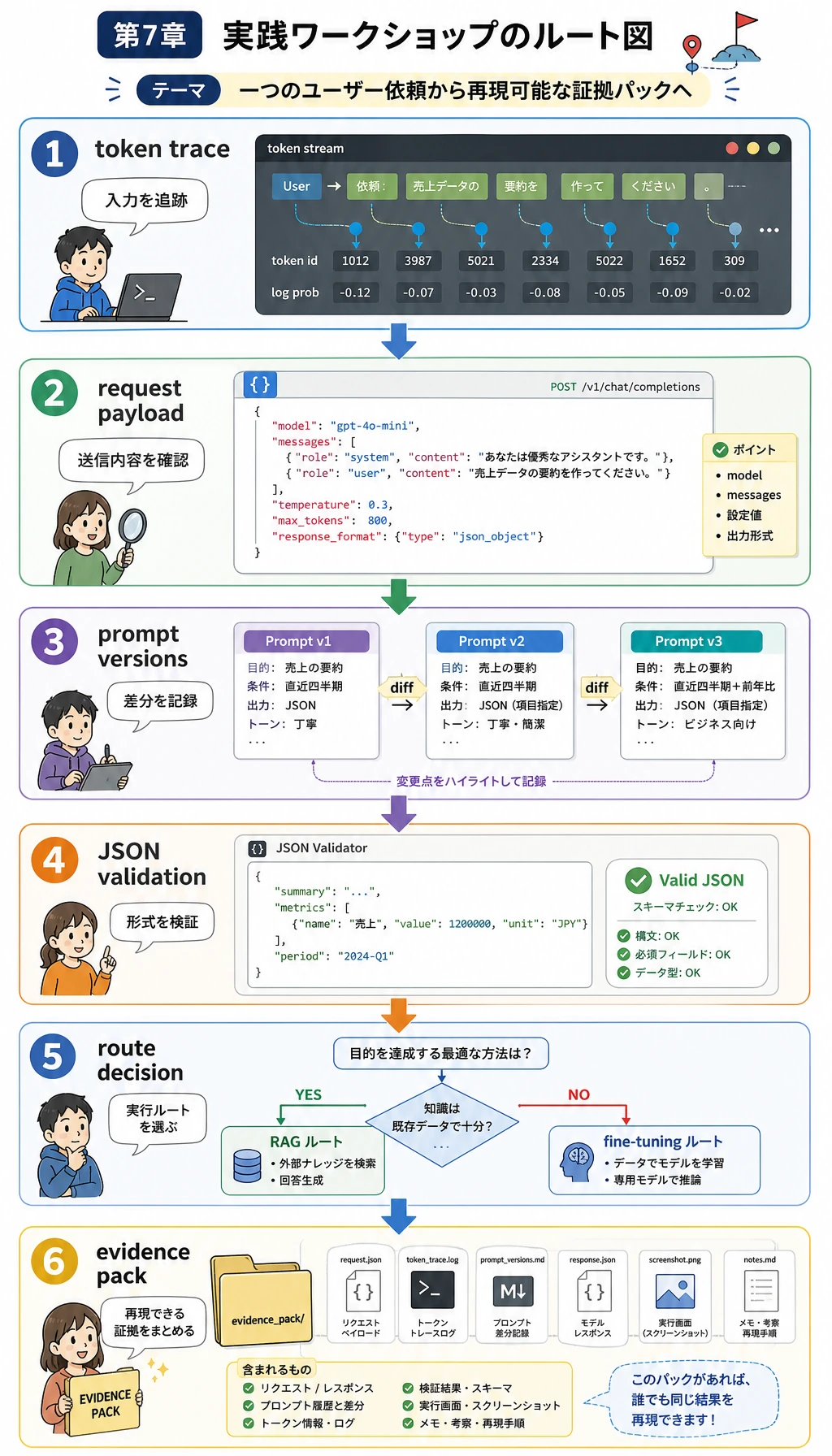
これがファイルの中でたどる道筋です。tokens、payload、Prompt 版、検証、手法判断、証拠へ進みます。
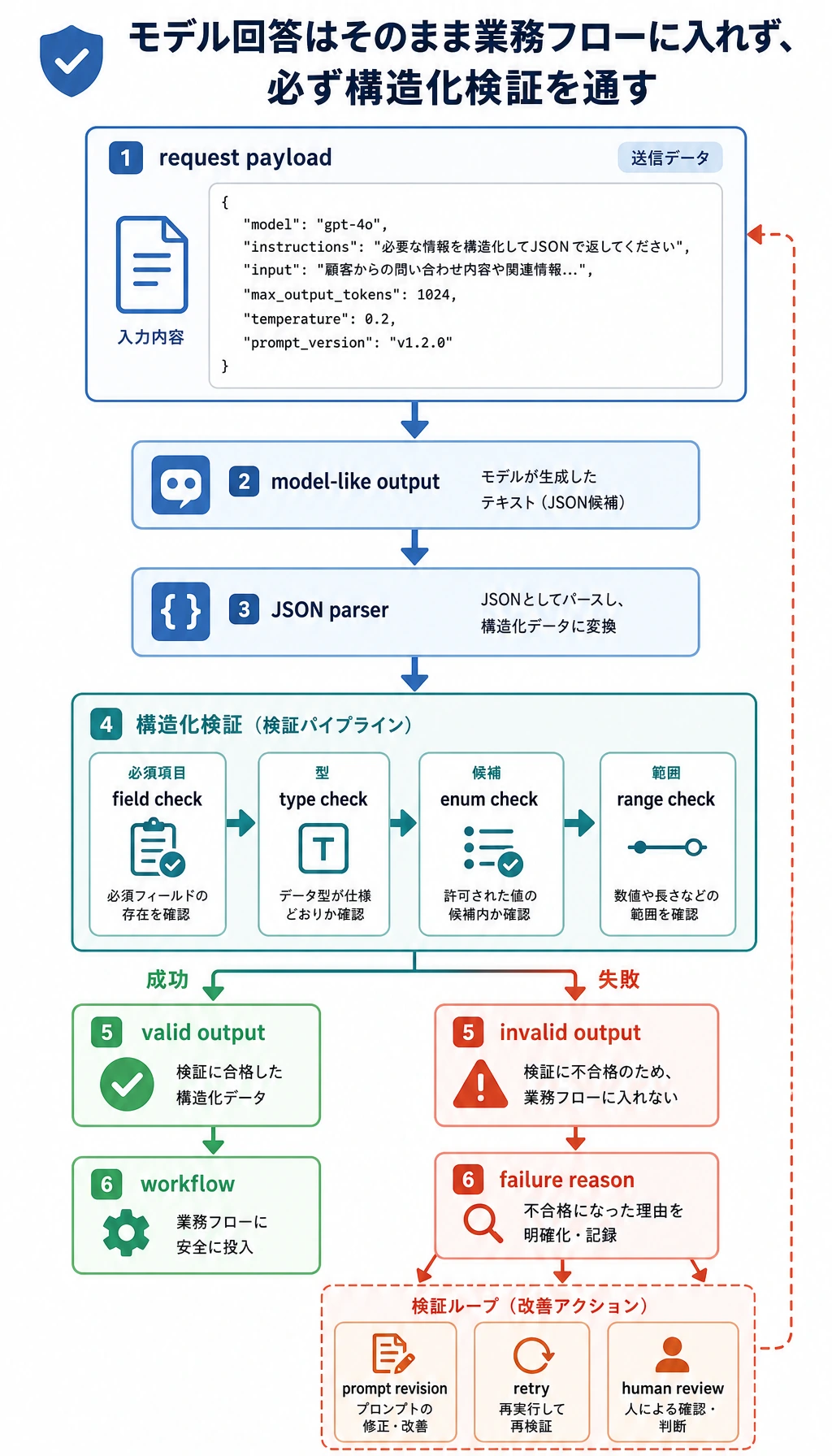
モデル風の回答は、プログラムが信頼する前に parser、field check、type check を通ります。
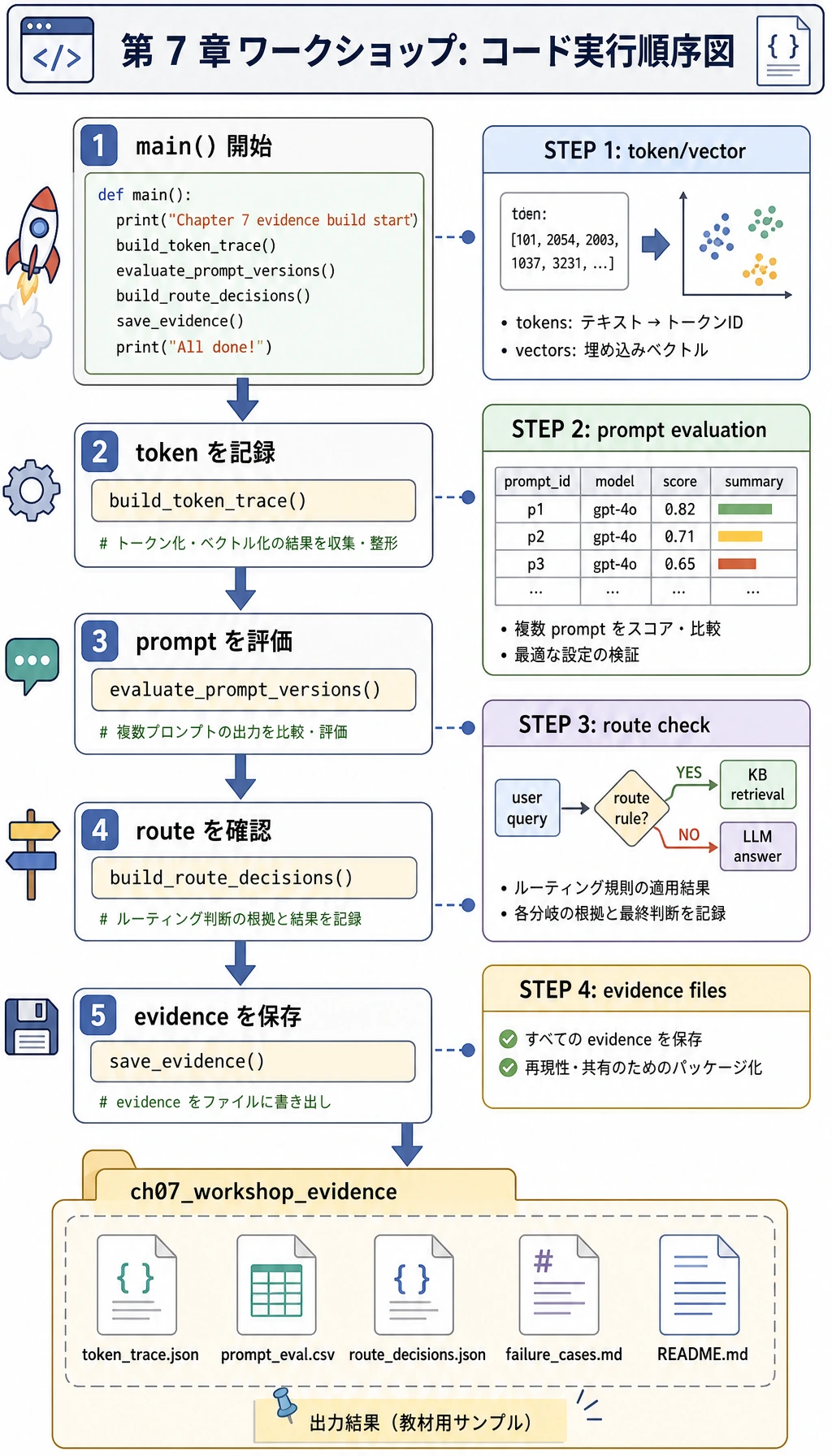
スクリプトは、まず痕跡を作り、次に Prompt を評価し、手法ルートを選び、最後にファイルを保存します。
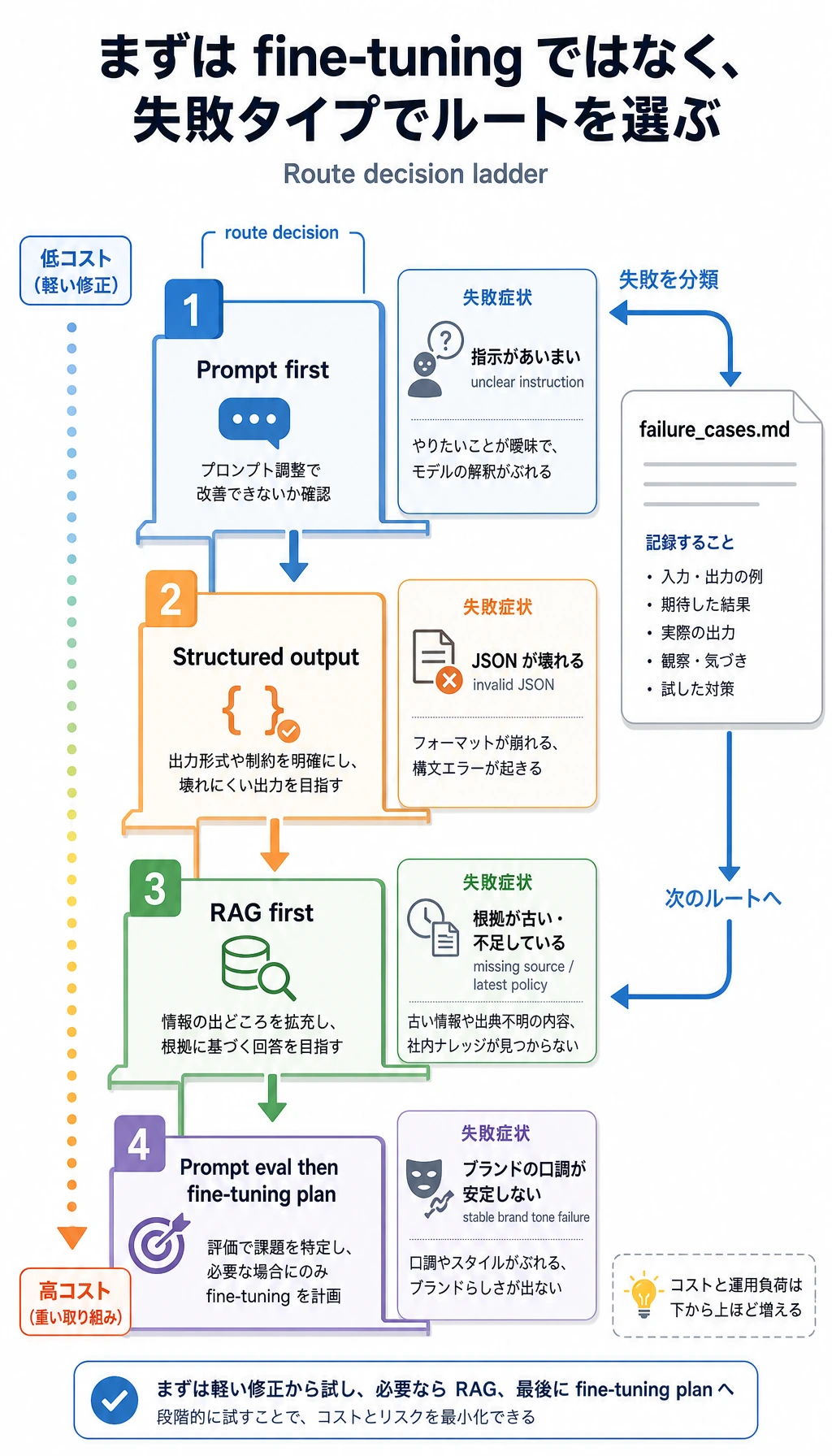
いきなりファインチューニングへ進まないでください。失敗の種類を見て、まず低コストで信頼できるルートを選びます。

最後のフォルダも学習内容の一部です。実行結果を再現でき、見直せて、他人にも説明できます。
プロジェクトフォルダを作る
Section titled “プロジェクトフォルダを作る”小さなローカルフォルダを作ります。
mkdir ch07_hands_oncd ch07_hands_on次に llm_stage_workshop.py というファイルを作成します。
実行後、スクリプトは ch07_workshop_evidence というフォルダも作成します。すでに存在する場合は、今回の最新実行で中のファイルを上書きします。
ワークショップコードを貼り付けて実行する
Section titled “ワークショップコードを貼り付けて実行する”次のコードを llm_stage_workshop.py に保存します。
import csvimport jsonimport mathimport hashlibfrom pathlib import Path
SAMPLES = [ { "id": "case_1", "user_input": "I understand tokens but not attention. Give me a short study plan.", "expected_intent": "learning_plan", }, { "id": "case_2", "user_input": "Convert this note into JSON fields: topic=LoRA, risk=overfitting.", "expected_intent": "structured_output", }, { "id": "case_3", "user_input": "Our assistant keeps using the wrong brand tone. Should we fine-tune?", "expected_intent": "solution_choice", },]
INTENTS = {"learning_plan", "structured_output", "solution_choice"}EVIDENCE_DIR = Path("ch07_workshop_evidence")
def simple_tokenize(text): cleaned = "".join(ch.lower() if ch.isalnum() else " " for ch in text) return [token for token in cleaned.split() if token]
def stable_token_id(token): digest = hashlib.sha1(token.encode("utf-8")).hexdigest() return int(digest[:6], 16) % 10000
def tiny_embedding(tokens, width=6): vector = [0.0] * width for token in tokens: vector[stable_token_id(token) % width] += 1.0 norm = math.sqrt(sum(value * value for value in vector)) or 1.0 return [round(value / norm, 3) for value in vector]
def infer_intent(text): lowered = text.lower() if "json" in lowered or "field" in lowered or "schema" in lowered: return "structured_output" if "fine-tune" in lowered or "brand tone" in lowered or "rag" in lowered: return "solution_choice" return "learning_plan"
def build_payload(case, prompt_version): base = { "model": "gpt-5.5", "input": case["user_input"], "max_output_tokens": 180, "temperature": 0.2, "prompt_version": prompt_version, } if prompt_version == "v1_goal_only": base["instructions"] = "Help the learner." elif prompt_version == "v2_json_contract": base["instructions"] = ( "Classify the learner request. Return JSON with id, intent, action, " "confidence, and needs_human_review." ) else: base["instructions"] = ( "Classify the learner request. Return JSON only. Allowed intent values: " "learning_plan, structured_output, solution_choice. confidence must be a " "number from 0 to 1. needs_human_review must be true only when the request " "asks for unsafe, legal, medical, or production deployment decisions." ) return base
def fake_model(payload, case): intent = infer_intent(payload["input"]) if payload["prompt_version"] == "v1_goal_only": return "Here is a helpful answer, but it is not machine-readable." if payload["prompt_version"] == "v2_json_contract" and case["id"] == "case_3": return json.dumps({"id": case["id"], "intent": "fine_tune", "action": "try fine-tuning"}) action_by_intent = { "learning_plan": "Start with tokens, then attention, then run the LLM call workbench.", "structured_output": "Define the JSON schema first, then validate every model output.", "solution_choice": "Run prompt evaluation first; consider fine-tuning only after stable failures repeat.", } return json.dumps( { "id": case["id"], "intent": intent, "action": action_by_intent[intent], "confidence": 0.86, "needs_human_review": False, }, ensure_ascii=False, )
def validate_output(raw): try: data = json.loads(raw) except json.JSONDecodeError as exc: return False, f"invalid_json: {exc.msg}", None required = ["id", "intent", "action", "confidence", "needs_human_review"] missing = [field for field in required if field not in data] if missing: return False, f"missing_fields: {missing}", data if data["intent"] not in INTENTS: return False, f"bad_intent: {data['intent']}", data if not isinstance(data["confidence"], (int, float)): return False, "confidence_not_number", data if not 0 <= data["confidence"] <= 1: return False, "confidence_out_of_range", data if not isinstance(data["needs_human_review"], bool): return False, "needs_human_review_not_boolean", data return True, "ok", data
def solution_route(text): lowered = text.lower() if "latest" in lowered or "source" in lowered or "policy" in lowered: return "RAG first" if "brand tone" in lowered or "keeps using" in lowered: return "Prompt eval first, then fine-tuning plan" if "json" in lowered or "field" in lowered: return "Structured output" return "Prompt first"
def build_token_trace(): rows = [] for case in SAMPLES: tokens = simple_tokenize(case["user_input"]) rows.append( { "case_id": case["id"], "tokens": tokens, "token_ids": [stable_token_id(token) for token in tokens], "tiny_embedding": tiny_embedding(tokens), } ) return rows
def evaluate_prompt_versions(): rows = [] for version in ["v1_goal_only", "v2_json_contract", "v3_json_with_boundary"]: for case in SAMPLES: payload = build_payload(case, version) raw = fake_model(payload, case) ok, reason, data = validate_output(raw) correct_intent = ok and data["intent"] == case["expected_intent"] if ok and not correct_intent: reason = f"wrong_intent: {data['intent']} != {case['expected_intent']}" rows.append( { "prompt_version": version, "case_id": case["id"], "passed": correct_intent, "reason": "ok" if correct_intent else reason, "raw_output": raw, } ) return rows
def build_route_decisions(): return [ { "case_id": case["id"], "user_input": case["user_input"], "first_route": solution_route(case["user_input"]), } for case in SAMPLES ]
def save_evidence(token_rows, eval_rows, route_rows): EVIDENCE_DIR.mkdir(exist_ok=True) token_path = EVIDENCE_DIR / "token_trace.json" eval_path = EVIDENCE_DIR / "prompt_eval.csv" route_path = EVIDENCE_DIR / "route_decisions.json" failure_path = EVIDENCE_DIR / "failure_cases.md" readme_path = EVIDENCE_DIR / "README.md"
token_path.write_text(json.dumps(token_rows, indent=2, ensure_ascii=False), encoding="utf-8") route_path.write_text(json.dumps(route_rows, indent=2, ensure_ascii=False), encoding="utf-8")
with eval_path.open("w", newline="", encoding="utf-8") as file: writer = csv.DictWriter(file, fieldnames=["prompt_version", "case_id", "passed", "reason", "raw_output"]) writer.writeheader() writer.writerows(eval_rows)
failures = [row for row in eval_rows if not row["passed"]] failure_lines = ["# 失敗ケース", ""] for row in failures: failure_lines.append(f"- {row['prompt_version']} / {row['case_id']}: {row['reason']}") failure_path.write_text("\n".join(failure_lines) + "\n", encoding="utf-8")
passed_v3 = sum(row["passed"] for row in eval_rows if row["prompt_version"] == "v3_json_with_boundary") readme_path.write_text( "# 第 7 章 LLM ワークショップの証拠\n\n" "実行コマンド:`python llm_stage_workshop.py`\n\n" f"最良のプロンプト版:v3_json_with_boundary({passed_v3}/{len(SAMPLES)} 合格)\n\n" "プロンプトを変更するか、RAG を追加するか、微調整を計画するかを決める前に、`failure_cases.md` を確認してください。\n", encoding="utf-8", ) return [token_path, eval_path, route_path, failure_path, readme_path]
def main(): token_rows = build_token_trace() print("STEP 1: Token and vector trace") for row in token_rows: print( f"{row['case_id']} tokens={row['tokens'][:8]} " f"ids={row['token_ids'][:8]} vector={row['tiny_embedding']}" )
eval_rows = evaluate_prompt_versions() print("\nSTEP 2: Prompt version evaluation") for version in ["v1_goal_only", "v2_json_contract", "v3_json_with_boundary"]: version_rows = [row for row in eval_rows if row["prompt_version"] == version] passed = sum(row["passed"] for row in version_rows) failures = [f"{row['case_id']}:{row['reason']}" for row in version_rows if not row["passed"]] print(f"{version}: {passed}/{len(version_rows)} passed; failures={failures or ['none']}")
route_rows = build_route_decisions() print("\nSTEP 3: Solution route check") for row in route_rows: print(f"{row['case_id']} -> {row['first_route']}")
saved_files = save_evidence(token_rows, eval_rows, route_rows) print("\nSTEP 4: Evidence files") for path in saved_files: print(path.as_posix())
if __name__ == "__main__": main()実行します。
python llm_stage_workshop.py期待される出力
Section titled “期待される出力”次のような出力になれば大丈夫です。
STEP 1: Token and vector tracecase_1 tokens=['i', 'understand', 'tokens', 'but', 'not', 'attention', 'give', 'me'] ids=[3860, 5684, 9523, 2631, 3109, 1613, 4738, 9496] vector=[0.0, 0.324, 0.324, 0.162, 0.811, 0.324]case_2 tokens=['convert', 'this', 'note', 'into', 'json', 'fields', 'topic', 'lora'] ids=[9914, 5551, 4760, 3544, 3358, 1778, 2081, 3008] vector=[0.0, 0.189, 0.756, 0.189, 0.567, 0.189]case_3 tokens=['our', 'assistant', 'keeps', 'using', 'the', 'wrong', 'brand', 'tone'] ids=[8696, 9265, 8706, 6757, 7679, 4122, 2342, 7190] vector=[0.343, 0.686, 0.514, 0.0, 0.171, 0.343]
STEP 2: Prompt version evaluationv1_goal_only: 0/3 passed; failures=['case_1:invalid_json: Expecting value', 'case_2:invalid_json: Expecting value', 'case_3:invalid_json: Expecting value']v2_json_contract: 2/3 passed; failures=["case_3:missing_fields: ['confidence', 'needs_human_review']"]v3_json_with_boundary: 3/3 passed; failures=['none']
STEP 3: Solution route checkcase_1 -> Prompt firstcase_2 -> Structured outputcase_3 -> Prompt eval first, then fine-tuning plan
STEP 4: Evidence filesch07_workshop_evidence/token_trace.jsonch07_workshop_evidence/prompt_eval.csvch07_workshop_evidence/route_decisions.jsonch07_workshop_evidence/failure_cases.mdch07_workshop_evidence/README.md
各ステップの意味
Section titled “各ステップの意味”| 出力箇所 | 見るポイント | 対応する章の概念 |
|---|---|---|
tokens と ids | テキストが小さな単位に分かれ、数字へ変わる | Tokenizer と token ids |
vector | 小さな教材用ベクトルで、テキストが数値特徴に変わることを見る | Embedding の直感 |
v1_goal_only | 回答は親切そうでも、プログラムは解析できない | 曖昧な Prompt と不安定なインターフェース |
v2_json_contract | JSON は役立つが、フィールド漏れや enum ミスで流れが壊れる | 構造化出力の検証 |
v3_json_with_boundary | 許可値、型、レビュー規則まで書くとテスト可能になる | Prompt 反復と スキーマ 設計 |
solution_route | 問題ごとに最初の一手が違う | Prompt、RAG、構造化出力、ファインチューニングの境界 |
ch07_workshop_evidence | 実行結果が確認、比較、共有できるファイルとして残る | 再現可能なプロジェクト証拠 |
初心者向けトラブルシューティング
Section titled “初心者向けトラブルシューティング”| 症状 | ありそうな原因 | 対処 |
|---|---|---|
python: command not found | 環境では python ではなく python3 を使う | python3 llm_stage_workshop.py を実行する |
| 出力の空白が少し違う | Python のリスト表示が環境で少し違うことがある | 合格数と失敗理由を見る |
invalid_json が出る | 模擬モデルが JSON ではなく自然言語を返した | v1_goal_only では意図的にそうしている |
missing_fields が出る | 出力契約が十分に厳密ではない | v2_json_contract と v3_json_with_boundary を比べる |
| 証拠ファイルができない | 読み取り専用フォルダで実行したか、STEP 4 の前で止めた可能性がある | 通常のプロジェクトフォルダで実行し、STEP 4 にファイルパスが出たか確認する |
| 実モデルを呼びたい | このワークショップは意図的にオフラインです | 先に本ページを終え、その後 LLM 呼び出しワークベンチの任意 API 部分へ進む |
任意:あとで実モデルに置き換える
Section titled “任意:あとで実モデルに置き換える”オフラインの流れが分かったら、fake_model() を実モデル呼び出しに置き換えられます。現在の OpenAI テキスト生成では、古い chat-completion 例をそのままコピーするのではなく、Responses API と構造化出力を優先して使うのが基本です。
実際の構造化出力呼び出しは、次のように書けます。
import osfrom pydantic import BaseModelfrom openai import OpenAI
class RouteResult(BaseModel): intent: str action: str confidence: float needs_human_review: bool
client = OpenAI()
response = client.responses.parse( model=os.getenv("OPENAI_MODEL", "gpt-5.5"), input=[ { "role": "system", "content": ( "Classify the learner request. Return a practical next action. " "Use needs_human_review only for unsafe, legal, medical, or production decisions." ), }, { "role": "user", "content": "Our assistant keeps using the wrong brand tone. Should we fine-tune?", }, ], text_format=RouteResult,)
print(response.output_parsed.model_dump())依存関係を入れ、key を設定してから実行します。
pip install --upgrade openai pydanticexport OPENAI_API_KEY="your_api_key_here"python real_route_call.py証拠パックを読む
Section titled “証拠パックを読む”今のスクリプトは、最小ポートフォリオ版を自動で保存します。実行後にこのフォルダを開いてください。
ls ch07_workshop_evidence次のファイルが見えるはずです。
| ファイル | 書く内容 |
|---|---|
README.md | 実行コマンド、最良の Prompt 版、次に確認すること |
token_trace.json | 各ケースの tokens、token ids、小さなベクトル |
prompt_eval.csv | Prompt 版とテストケースごとの行。合格/失敗理由も入る |
route_decisions.json | 各ケースが最初に選ぶべき手法ルート |
failure_cases.md | Prompt 変更、RAG 追加、ファインチューニング計画の前に見るべき失敗証拠 |
最初に failure_cases.md を開いてください。v1 がなぜ機械的に読めず、v2 がなぜまだ厳密でないかが分かります。第 7 章で身につけたい習慣はここです。見栄えのよい 1 回の回答ではなく、再現できる失敗と保存された証拠から判断します。
完了チェックリスト
Section titled “完了チェックリスト”- このワークショップをローカルで実行できる。
- 自然言語出力だけではプロダクトの流れに足りない理由を説明できる。
- 検証が invalid JSON とフィールド漏れの両方を捕まえる理由を説明できる。
- 固定テストケースで Prompt 版を比較できる。
- ファインチューニングは通常、Prompt 評価と安定した失敗証拠の後に検討する理由を説明できる。
5 つすべてを確認できれば、第 7 章を概念の読み物ではなく、実行できるエンジニアリングループに変えられています。
このページを終えたら、この証拠カードを残します。
- ワークショップ出力
- 端末結果を保存
- プロンプト評価
- 固定ケース全体の合格率
- 構造化出力
- スキーマ検証結果
- 失敗ログ
- 失敗ケースと原因の可能性
- README 記録
- 何が成功し、何が失敗し、次に何を試すか
ワークショップレビュー観点と通過基準
- 合格の目安は、保存された evidence folder だけで実行内容を説明できることです。terminal history に頼らない状態にします。
- Prompt を直す前に
prompt_eval.csvを確認します。次の編集は好みではなく、fixed case の失敗から決めます。 failure_cases.mdは、後の RAG や fine-tuning 判断への橋です。失敗が知識不足なら先に retrieval、format drift なら structured output を先に締めます。- script を再実行し、evidence files を確認し、次の行動が Prompt、RAG、fine-tuning、または変更なしのどれかを説明できれば、このページは完了です。