9.9.4 永続化と復元
- 「永続化」と「復元」が Agent タスクでどういう意味を持つか理解する
- 状態スナップショットとイベントログの2種類のデータを区別できるようになる
- 実行可能な例を通して、最小限の checkpoint + 復元フローを実装する
- 復元の流れで冪等性がなぜ重要か理解する
なぜ Agent には特に復元能力が必要なのか?
Section titled “なぜ Agent には特に復元能力が必要なのか?”なぜなら、多くのタスクは瞬時に終わらないから
Section titled “なぜなら、多くのタスクは瞬時に終わらないから”たとえば:
- 調査レポートの生成
- 複数ツールを使う承認フロー
- 複数回にわたるバックエンドの収集と整理
このようなタスクは、次のようなものをまたぐことがよくあります。
- 複数回の呼び出し
- 複数のステップ
- より長い時間範囲
復元能力がないと、どんな問題が起きるか?
Section titled “復元能力がないと、どんな問題が起きるか?”- 1回中断すると、全部やり直しになる
- 実行済みの動作が重複して実行される可能性がある
- ユーザーが現在の進捗を確認できない
永続化のない Agent は、「電源が落ちると記憶をなくす」ワークステーションのようなものです。
本当に本番で使えるシステムは、自動保存と復元ポイントがある IDE のようなものです。
永続化はいったい何を保存するのか?
Section titled “永続化はいったい何を保存するのか?”最も重要なのはタスク状態
Section titled “最も重要なのはタスク状態”たとえば:
- どこまで実行したか
- どのステップが完了したか
- 中間結果は何か
次に重要なのはイベントログ
Section titled “次に重要なのはイベントログ”イベントログが答えるのは、次のようなことです。
- これまで実際に何が起きたのか
たとえば:
- どのツールを呼び出したか
- どんな返り値を受け取ったか
- どのステップで失敗したか
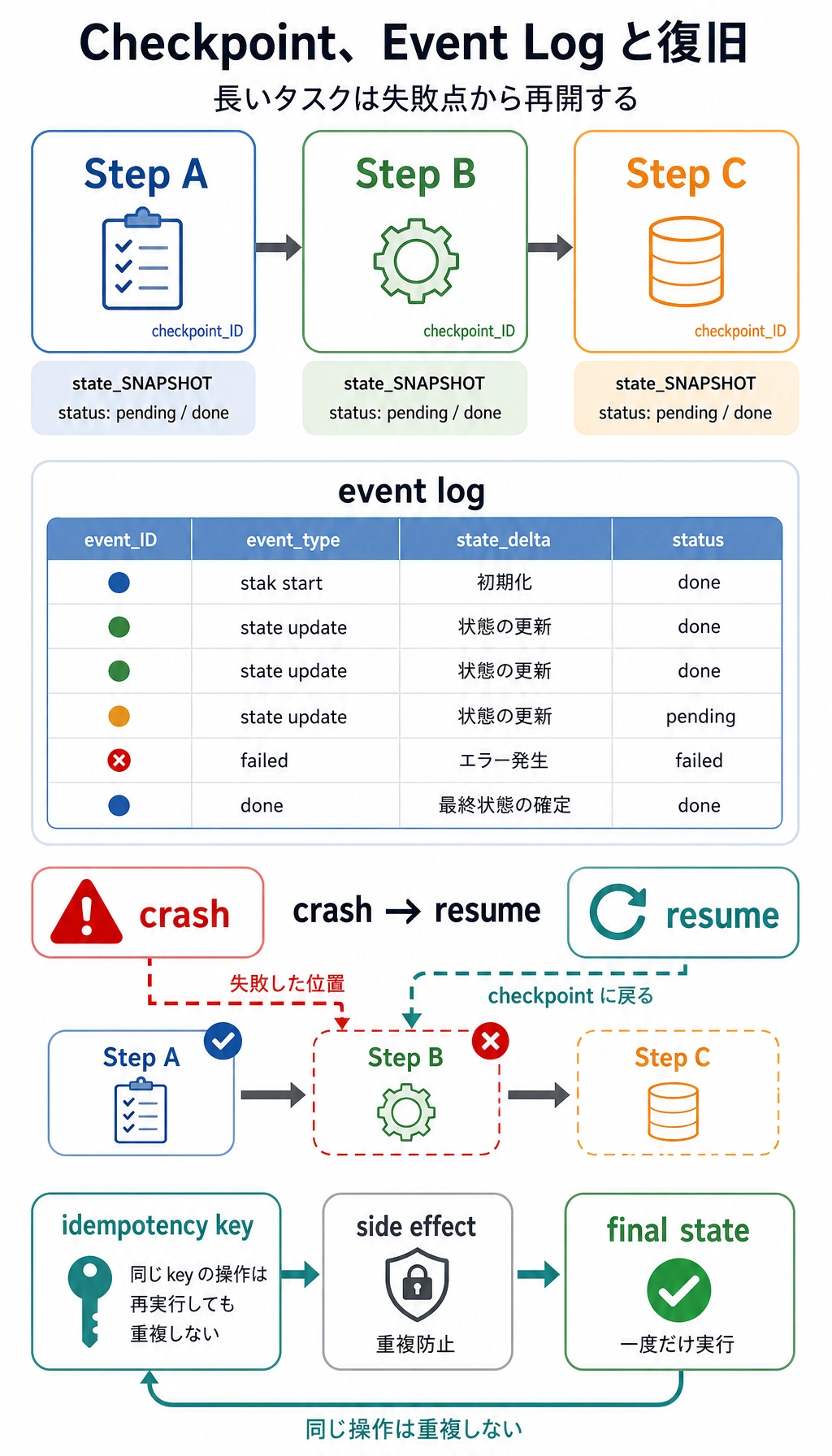
スナップショットとログの違い
Section titled “スナップショットとログの違い”まずはこう覚えるとよいです。
checkpoint / snapshot:現在状態の圧縮された断面event log:システムで起きた出来事の履歴
実際の開発では、この2つを組み合わせて使うことがよくあります。
まずは最小限の復元ワークフローを動かしてみよう
Section titled “まずは最小限の復元ワークフローを動かしてみよう”次の例では、3ステップのタスクをシミュレーションします。
- 資料を読み込む
- 要約を作る
- レポートを書き込む
システムは各ステップのあとに checkpoint を書きます。
もし第2ステップで障害が起きたら、最後の checkpoint から続けます。
import copy
TASK_PLAN = ["load_data", "summarize", "write_report"]
def execute_step(step, state): if step == "load_data": state["data"] = ["返金ルール", "請求書ルール", "住所変更ルール"] elif step == "summarize": state["summary"] = ";".join(state["data"]) elif step == "write_report": state["report"] = f"最終レポート: {state['summary']}" return state
class WorkflowRunner: def __init__(self): self.event_log = [] self.last_checkpoint = None
def checkpoint(self, state): self.last_checkpoint = copy.deepcopy(state)
def log_event(self, event_type, payload): self.event_log.append({"type": event_type, "payload": copy.deepcopy(payload)})
def run(self, fail_on_step=None): state = self.last_checkpoint or {"current_index": 0, "completed_steps": []}
while state["current_index"] < len(TASK_PLAN): step = TASK_PLAN[state["current_index"]] self.log_event("step_started", {"step": step, "state": state})
if step == fail_on_step: self.log_event("step_failed", {"step": step}) raise RuntimeError(f"crash_on_{step}")
state = execute_step(step, state) state["completed_steps"].append(step) state["current_index"] += 1
self.checkpoint(state) self.log_event("step_completed", {"step": step, "state": state})
return state
runner = WorkflowRunner()
try: runner.run(fail_on_step="summarize")except RuntimeError as e: print("最初の実行はクラッシュしました:", e)
print("クラッシュ後の checkpoint:", { "current_index": runner.last_checkpoint["current_index"], "completed_steps": runner.last_checkpoint["completed_steps"],})
final_state = runner.run()print("\n復元後の最終状態:")print({ "completed_steps": final_state["completed_steps"], "report": final_state["report"],})
print("\nevent types:")print([event["type"] for event in runner.event_log])実行結果の例:
最初の実行はクラッシュしました: crash_on_summarizeクラッシュ後の checkpoint: {'current_index': 1, 'completed_steps': ['load_data']}
復元後の最終状態:{'completed_steps': ['load_data', 'summarize', 'write_report'], 'report': '最終レポート: 返金ルール;請求書ルール;住所変更ルール'}
event types:['step_started', 'step_completed', 'step_started', 'step_failed', 'step_started', 'step_completed', 'step_started', 'step_completed']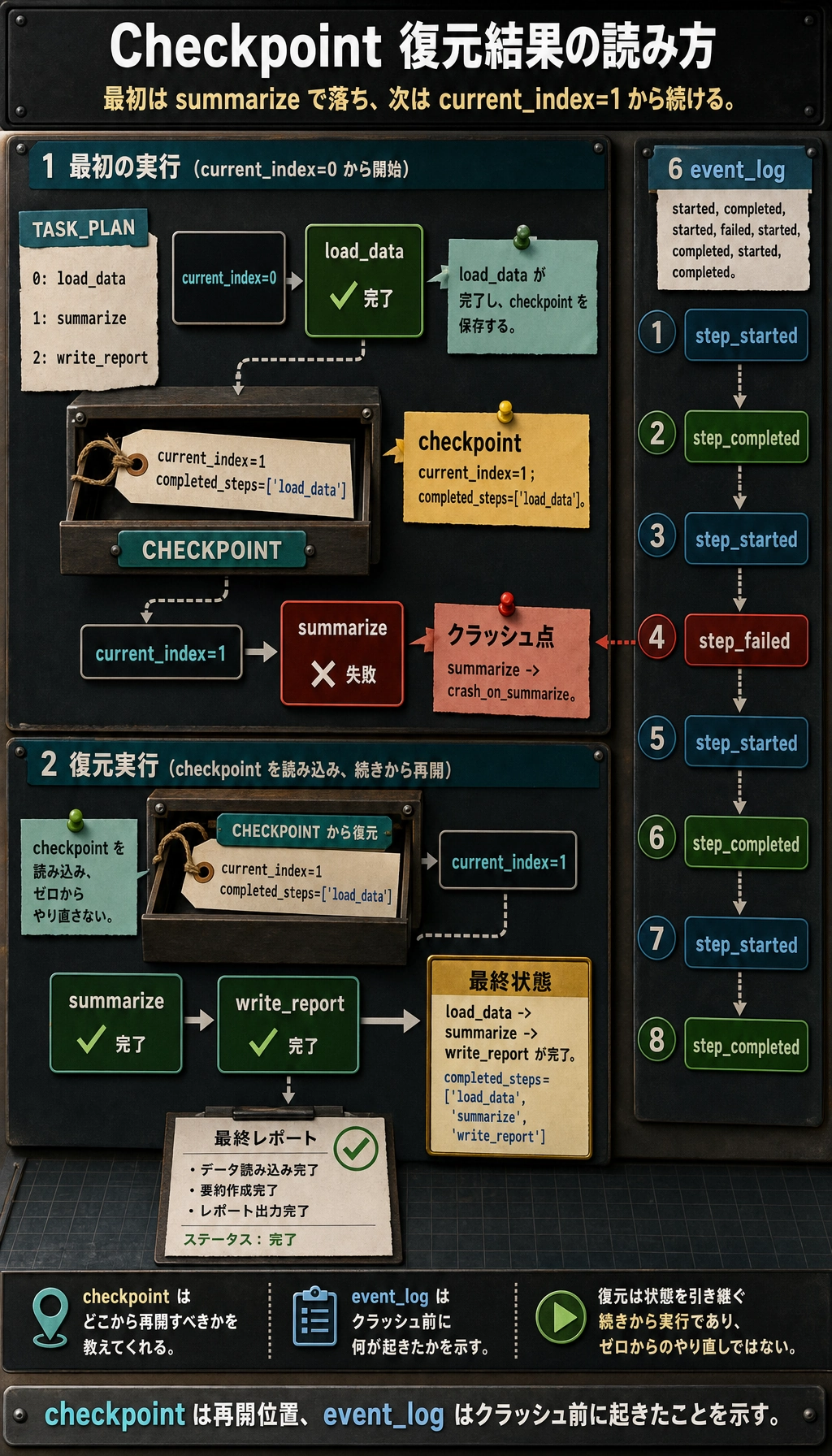
この例で特に学ぶべきことは何か?
Section titled “この例で特に学ぶべきことは何か?”復元の流れで最も重要な3つをつないでいます。
- 各ステップ完了後に checkpoint を書く
- エラー時に event log を残す
- 再起動後は最後の checkpoint から続けて実行する
なぜ checkpoint はタスクの最後だけに書いてはいけないのか?
Section titled “なぜ checkpoint はタスクの最後だけに書いてはいけないのか?”そうすると、タスクの途中でクラッシュしたときに、
何も復元できなくなってしまうからです。
そのため、長いタスクでは次のようにするのが実用的です。
- ステップ単位の checkpoint
なぜ event log が重要なのか?
Section titled “なぜ event log が重要なのか?”checkpoint だけでは「今どんな状態か」は分かりますが、
次のようなことまでは完全には分かりません。
- なぜその状態になったのか
- どこで失敗が起きたのか
ログがあると、振り返りやデバッグがしやすくなります。
なぜ冪等性が復元の核心なのか?
Section titled “なぜ冪等性が復元の核心なのか?”冪等とは何か
Section titled “冪等とは何か”冪等は、ざっくり言うと次の意味です。
- 同じ動作を何回繰り返しても、結果が同じになること
なぜ復元時に特に必要なのか
Section titled “なぜ復元時に特に必要なのか”もしシステムが「レポートを書く」直前で落ちたら、再起動後に次のどちらだったか分からないことがあります。
- その処理はもう終わっていたのか
動作が冪等でないと、次のような問題が起こります。
- 重複書き込み
- 重複課金
- 重複メッセージ送信
processed = set()
def send_email_once(task_id, address): if task_id in processed: return {"ok": True, "status": "skipped_duplicate"} processed.add(task_id) return {"ok": True, "status": f"sent_to:{address}"}
実行結果の例:
{'ok': True, 'status': 'sent_to:[email protected]'}{'ok': True, 'status': 'skipped_duplicate'}これが、最もシンプルな冪等保護の考え方です。
復元設計で見落としやすいものは何か?
Section titled “復元設計で見落としやすいものは何か?”状態に「結果」だけを保存して、「進捗」を保存しない
Section titled “状態に「結果」だけを保存して、「進捗」を保存しない”summary だけを保存して、次の情報を保存していないとします。
- いま何ステップ目か
この場合、復元しても続きから進めるのが難しくなります。
checkpoint だけ保存して、ログを保存しない
Section titled “checkpoint だけ保存して、ログを保存しない”これでも復元はできますが、なぜ失敗したのかを調べにくくなります。
外部副作用に冪等キーがない
Section titled “外部副作用に冪等キーがない”これは復元を危険にします。
なぜなら、再実行したときに重複した副作用が起きるかどうか、システムが判断できないからです。
実際のシステムでは普通どうするのか?
Section titled “実際のシステムでは普通どうするのか?”状態テーブル
Section titled “状態テーブル”次の情報を保存します。
- タスク id
- 現在のステップ
- 現在の状態スナップショット
- 更新時刻
イベントテーブル
Section titled “イベントテーブル”次の情報を保存します。
- イベントタイプ
- 時刻
- 入出力の要約
- エラー情報
役割は次の通りです。
- 再起動時に未完了タスクを探す
- 最新の checkpoint を読み込む
- 安全な位置から続ける
期待される結果:checkpoint、event log、冪等性、復旧位置を設計し、失敗後でも重複副作用を避けて安全に続行できる状態です。
このページを終えたら、この証拠カードを残します。
- ランタイム
- キュー、ワーカー、状態ストア、ツールサービス、モデルエンドポイント
- 永続化
- チェックポイント、イベントログ、メモリストア、復旧パス
- 運用シグナル
- レイテンシ、コスト、エラー率、追跡カバレッジ、飽和度
- 失敗確認
- 停止した実行、重複アクション、部分失敗、またはコスト暴走
- 復旧アクション
- 再開、ロールバック、中止、人間への引き継ぎ、または安全に劣化
よくある誤解
Section titled “よくある誤解”誤解1:データベースがあれば「復元可能」である
Section titled “誤解1:データベースがあれば「復元可能」である”違います。
重要なのは、次のような情報を保存しているかです。
- 復元に十分な情報
誤解2:復元とは「もう一度実行する」こと
Section titled “誤解2:復元とは「もう一度実行する」こと”もう一度実行すると、重複した副作用が起こりやすくなります。
復元はやり直しではなく、状態を保ったまま続けることです。
誤解3:超長時間タスクだけに復元が必要
Section titled “誤解3:超長時間タスクだけに復元が必要”外部副作用や複数ステップ実行があるなら、
復元能力は非常に重要です。
この節で最も大切なのは、本番運用の視点を持つことです。
Agent の永続化と復元は、単に結果を書き込むことではありません。checkpoint、イベントログ、冪等メカニズムを中心に設計して、失敗後でも安全に続けられるようにすることです。
この流れがきちんと設計できれば、
システムは「たまに動くデモ」から、「失敗しても続けられる本番システム」へ進化します。
- 例に
retry_countフィールドを追加して、各ステップの再試行回数を記録してみましょう。 write_reportを外部副作用を伴う動作に変更し、冪等性をどう作るか考えてみましょう。- なぜ checkpoint と event log は復元でどちらも欠かせないと言えるのでしょうか?
- タスクがとても長い場合、毎ステップ checkpoint を取るべきでしょうか、それとも数ステップごとに checkpoint を取るべきでしょうか?その理由も考えてみましょう。
参考実装と解説
retry_countは run 全体ではなく step ごとに保存します。どの step が不安定かを見られ、retry storm が final status の中に隠れるのを防げます。write_reportが external side effect を持つなら、stable operation id、existence check、deduplication、外部書き込みがすでに成功したかの記録で idempotency を実装します。- checkpoint は最新の再開可能 state を与え、event log は system がそこへどう到達したかを説明します。recovery には snapshot と decisions / side effects の履歴の両方が必要です。
- 長い task では、重要・不可逆・高コストな step の後に checkpoint し、低リスク step は数 step ごとにします。毎 step checkpoint が最も安全ですが、storage と latency overhead が増えます。