E.A.3 モデル最適化技術
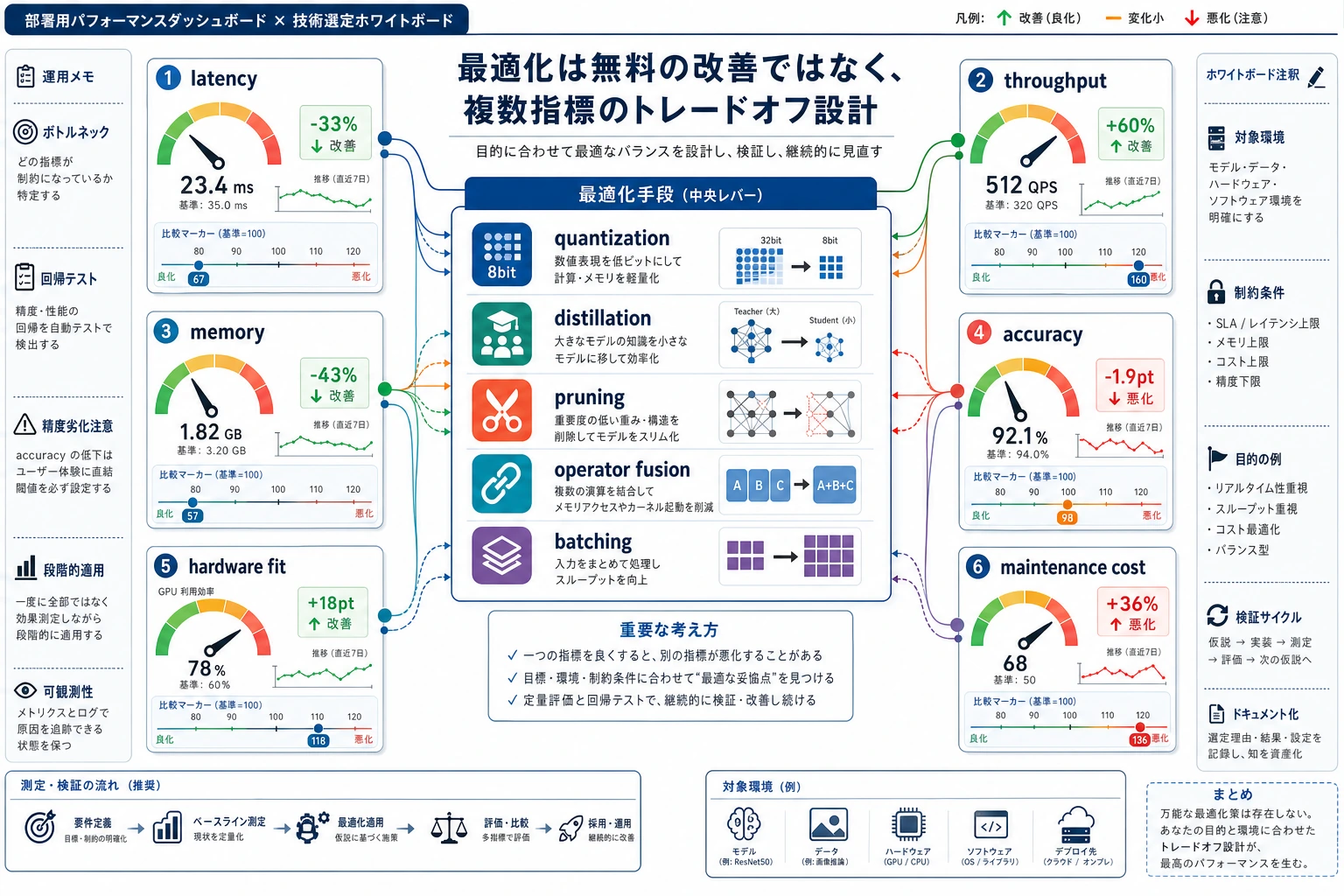
最適化は「できるだけ小さくすること」ではありません。1 つの制約を改善しながら、何を失ったかも確認することです。
小さな量子化誤差チェックを動かす
Section titled “小さな量子化誤差チェックを動かす”values = [0.1234, 0.5678, 0.9012]quantized = [round(value * 255) / 255 for value in values]errors = [abs(original - compressed) for original, compressed in zip(values, quantized)]
print([round(value, 4) for value in quantized])print(f"max_error={max(errors):.4f}")期待される出力:
[0.1216, 0.5686, 0.902]max_error=0.0018これが最小の最適化習慣です。圧縮し、誤差を測り、その誤差が許容できるか判断します。
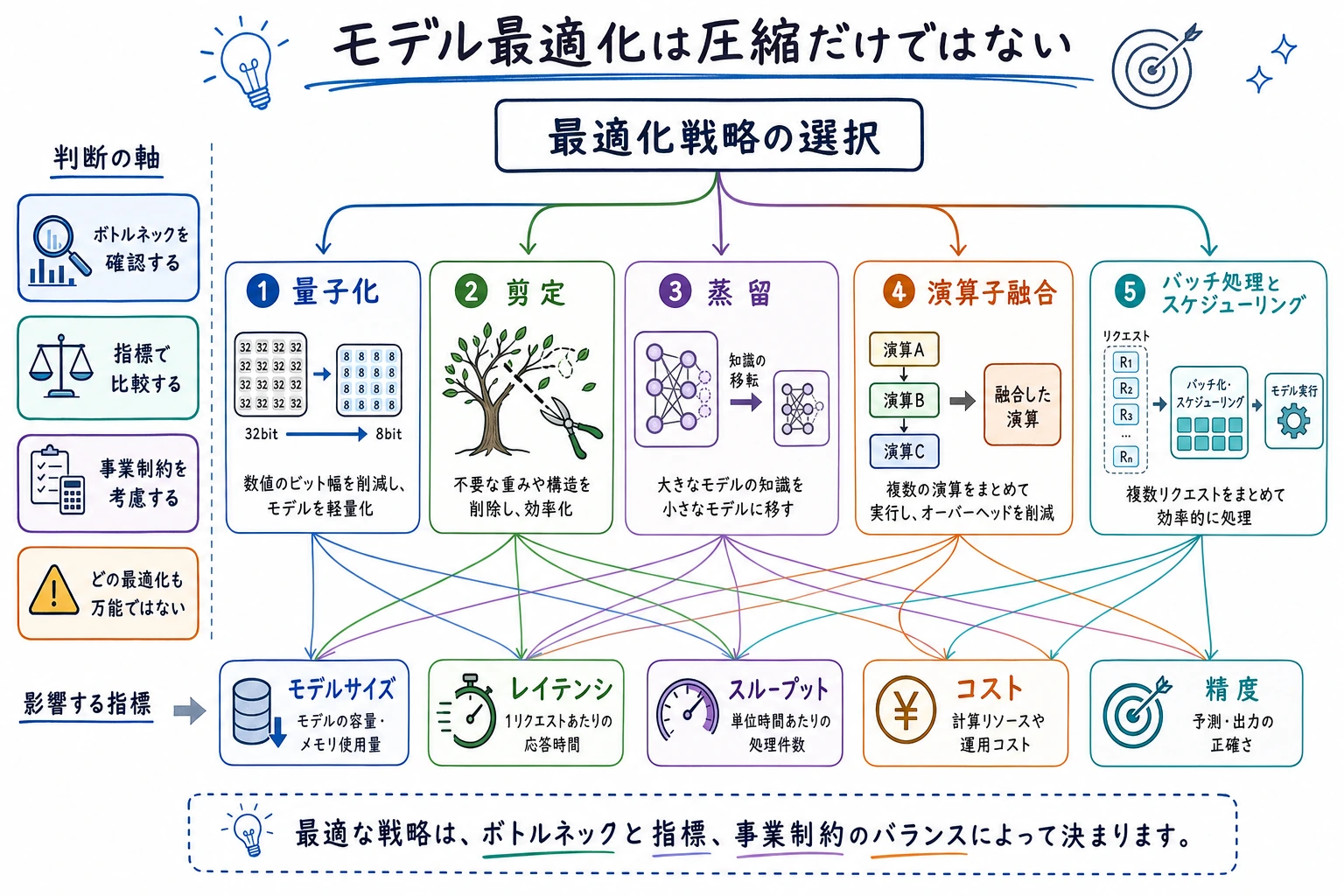
適切な最適化経路を選ぶ
Section titled “適切な最適化経路を選ぶ”| 技術 | 向いている場面 | リリース前に確認すること |
|---|---|---|
| 量子化 | 遅延とメモリが大きすぎる | 実際の検証ケースでの精度低下 |
| 枝刈り | 不要な重みやチャネルが多い | runtime が本当に速くなるか |
| 蒸留 | 小さいモデルが大きいモデルをまねられる | 小さいモデルが境界ケースで失敗しないか |
| 演算融合 | runtime overhead が大きい | エンジンが融合後のグラフを支えるか |
| Batching / scheduling | 多くのリクエストが同時に来る | tail latency とキュー待ち |
実用的な順序
Section titled “実用的な順序”- baseline の遅延、メモリ、精度を測る。
- 1 回に 1 つの最適化だけ試す。
- before/after 指標を記録する。
- 失敗例を残す。
- トレードオフが見えるときだけ出す。
最適化レビュー
Section titled “最適化レビュー”すべての最適化を小さな controlled experiment として扱います。control group は元の model と runtime です。treatment は 1 つの変更だけにします。量子化、枝刈り、batching、engine 変更を同時に行うと、結果が良くなっても理由が分からなくなります。
レビューでは、before latency、after latency、memory、model size、quality check、失敗例を 1 つの小さな表に残します。quality が落ちた場合は、どのサンプルが悪化したのかを書き、product として許容できるかを判断します。
このページを終えたら、この証拠カードを残します。
- デプロイ先
- ローカル推論、エッジデバイス、モデルサーバー、または最適化実験
- 成果物
- C++ スニペット、ベンチマーク、model artifact、serving 設定、または deployment メモ
- 指標
- レイテンシ、メモリ、スループット、モデルサイズ、accuracy 低下、または信頼性
- 失敗確認
- ABI/ビルドの問題、ハードウェア不一致、量子化損失、または配信ボトルネック
- 期待される成果
- 理論メモだけでなく、再現可能なデプロイまたは最適化の証拠
合格チェック
Section titled “合格チェック”1 つの最適化の利点、起こり得るコスト、本番デプロイ前に見るべき指標を説明できれば合格です。
確認の考え方と解説
合格する答えは、1 つの最適化手法、その利点、潜在的なコスト、そして本番前に確認すべき指標を具体的に述べます。たとえば量子化はメモリを減らせますが、検証データの精度や失敗ケースを確認する必要があります。枝刈りはモデルを小さくできますが、runtime が本当に速くなるかを確かめる必要があります。
「小さいほど良い」だけでは不十分です。何を残し、何を失い、その取捨選択がなぜ実運用で許容できるのかを説明してください。