3.5.3 SQL 基礎
- SQL の4大操作を理解する:追加、削除、更新、検索
SELECTクエリを使いこなすWHEREによる条件フィルタを学ぶJOINによる複数テーブル結合を理解するGROUP BYによるグループ化と集計を理解する
まず地図を1枚作ろう
Section titled “まず地図を1枚作ろう”SQL を新人が理解しやすい順番は、「最初から文法を丸暗記する」ではなく、まず全体像をつかむことです。
flowchart LR A["SELECT 何を選ぶか"] --> B["FROM どの表から取るか"] B --> C["WHERE まず何を除くか"] C --> D["GROUP BY どう分けるか"] D --> E["ORDER BY 最後にどう並べるか"]この節で本当に解決したいのは、次の2つです。
- SQL のクエリは頭の中でどう流れるのか
- なぜ
Pandasの絞り込み、グループ化、結合に対応づけられるのか
SQL とは?
Section titled “SQL とは?”SQL(Structured Query Language、構造化問い合わせ言語)は、データベースと「対話」するための言語です。SQLite、MySQL、PostgreSQL のどれを使っても、SQL の基本文法はほぼ共通です。
flowchart LR A["あなた(人間)"] -->|"SQL を書く"| B["データベースエンジン"] B -->|"結果を返す"| A
style A fill:#e3f2fd,stroke:#1565c0,color:#333 style B fill:#e8f5e9,stroke:#2e7d32,color:#333新人向けの、よりわかりやすい比喩
Section titled “新人向けの、よりわかりやすい比喩”SQL は次のように考えるとよいです。
- あなたがデータベースに質問している
その質問は、だいたいとても素朴です。
- どの列がほしい?
- どの行だけほしい?
- 何で分ける?
- 2つの表をどうつなぐ?
この比喩は新人にとても向いています。SQL を「別の言語」ではなく、「表にどう質問するか」として捉え直せるからです。
準備:練習用データベースを作る
Section titled “準備:練習用データベースを作る”この節の例はすべてこの練習用データベースに基づいています。先に実行してください。
import sqlite3
conn = sqlite3.connect(":memory:") # メモリ上のデータベース。閉じると消えるcursor = conn.cursor()
# users テーブルを作成cursor.execute(""" CREATE TABLE users ( id INTEGER PRIMARY KEY, name TEXT NOT NULL, age INTEGER, city TEXT, salary REAL )""")
# orders テーブルを作成cursor.execute(""" CREATE TABLE orders ( order_id INTEGER PRIMARY KEY, user_id INTEGER, product TEXT, amount REAL, order_date TEXT, FOREIGN KEY (user_id) REFERENCES users(id) )""")
# ユーザーデータを挿入users_data = [ (1, "张三", 28, "北京", 15000), (2, "李四", 35, "上海", 22000), (3, "王五", 22, "广州", 8000), (4, "赵六", 42, "北京", 35000), (5, "钱七", 30, "上海", 18000), (6, "孙八", 26, "深圳", 12000),]cursor.executemany("INSERT INTO users VALUES (?, ?, ?, ?, ?)", users_data)
# 注文データを挿入orders_data = [ (101, 1, "iPhone", 7999, "2024-11-01"), (102, 1, "AirPods", 999, "2024-11-05"), (103, 2, "MacBook", 14999, "2024-11-10"), (104, 3, "iPad", 3999, "2024-11-15"), (105, 2, "キーボード", 599, "2024-11-20"), (106, 4, "モニター", 2999, "2024-12-01"), (107, 5, "マウス", 299, "2024-12-05"),]cursor.executemany("INSERT INTO orders VALUES (?, ?, ?, ?, ?)", orders_data)
conn.commit()
# クエリを簡単に実行するための補助関数を定義def query(sql): cursor.execute(sql) cols = [desc[0] for desc in cursor.description] rows = cursor.fetchall() # ヘッダーを表示 print(" | ".join(cols)) print("-" * (len(" | ".join(cols)))) for row in rows: print(" | ".join(str(v) for v in row)) print()一、データを検索する(SELECT)
Section titled “一、データを検索する(SELECT)”SELECT は SQL の中で最もよく使う文で、テーブルからデータを取り出すために使います。
-- すべての列を検索SELECT * FROM users;
-- 指定した列だけ検索SELECT name, age, city FROM users;
-- 列に別名をつけるSELECT name AS 氏名, age AS 年齢 FROM users;query("SELECT * FROM users")# id | name | age | city | salary# 1 | 张三 | 28 | 北京 | 15000# 2 | 李四 | 35 | 上海 | 22000# ...DISTINCT:重複を除く
Section titled “DISTINCT:重複を除く”-- 重複しない都市名をすべて検索SELECT DISTINCT city FROM users;LIMIT:件数を制限する
Section titled “LIMIT:件数を制限する”-- 先頭3件だけ取得SELECT * FROM users LIMIT 3;最初にクエリを書くときの、いちばん安定した順番
Section titled “最初にクエリを書くときの、いちばん安定した順番”基本的には、次の順番が書きやすいです。
- まず
SELECT - 次に
FROM - 必要なら
WHERE - 最後に並び替えやグループ化
最初から全部の句を一気に混ぜるより、ずっと整理しやすくなります。
二、条件で絞り込む(WHERE)
Section titled “二、条件で絞り込む(WHERE)”WHERE は Pandas のブールインデックスのようなもので、条件に合う行だけを選びます。
-- 年齢が 30 より大きいSELECT * FROM users WHERE age > 30;
-- 都市が北京SELECT * FROM users WHERE city = '北京';
-- 給与が 10000 から 20000 の間SELECT * FROM users WHERE salary BETWEEN 10000 AND 20000;条件の組み合わせ
Section titled “条件の組み合わせ”-- AND:両方満たすSELECT * FROM users WHERE city = '北京' AND age > 25;
-- OR:どちらかを満たすSELECT * FROM users WHERE city = '北京' OR city = '上海';
-- IN:リストの中にあるSELECT * FROM users WHERE city IN ('北京', '上海', '深圳');
-- NOT:否定するSELECT * FROM users WHERE city NOT IN ('北京');あいまい検索(LIKE)
Section titled “あいまい検索(LIKE)”-- % は任意の文字列にマッチ(Pandas の str.contains に近い)SELECT * FROM users WHERE name LIKE '张%'; -- 「张」で始まるSELECT * FROM users WHERE name LIKE '%三'; -- 「三」で終わるSELECT * FROM users WHERE email LIKE '%@mail%'; -- 「@mail」を含むNULL の扱い
Section titled “NULL の扱い”-- 空かどうかを判定する(= NULL は使えない)SELECT * FROM users WHERE city IS NULL;SELECT * FROM users WHERE city IS NOT NULL;SQL と Pandas の対応表
Section titled “SQL と Pandas の対応表”| 目的 | SQL | Pandas |
|---|---|---|
| 年齢が 30 より大きい | WHERE age > 30 | df[df["age"] > 30] |
| 都市が北京 | WHERE city = '北京' | df[df["city"] == "北京"] |
| 複数条件 AND | WHERE age > 30 AND city = '北京' | df[(df["age"] > 30) & (df["city"] == "北京")] |
| 複数条件 OR | WHERE city IN ('北京', '上海') | df[df["city"].isin(["北京", "上海"])] |
| あいまい検索 | WHERE name LIKE '张%' | df[df["name"].str.startswith("张")] |
| 空値 | WHERE city IS NULL | df[df["city"].isna()] |
初学者が最初に覚えるとよい対応表
Section titled “初学者が最初に覚えるとよい対応表”| 頭の中の質問 | 近い SQL |
|---|---|
| 条件に合う記録だけ見る | WHERE |
| 1つの表の中の重複しない値を見る | DISTINCT |
| まず数件だけ確認する | LIMIT |
| 2つの表をつなぐ | JOIN |
| 先にグループ分けしてから集計する | GROUP BY |
この表は新人にとても役立ちます。SQL をキーワードの一覧ではなく、よくある質問の種類として整理できるからです。
三、並び替え(ORDER BY)
Section titled “三、並び替え(ORDER BY)”-- 給与の昇順(デフォルト)SELECT * FROM users ORDER BY salary;
-- 給与の降順SELECT * FROM users ORDER BY salary DESC;
-- まず都市で並べ、同じ都市の中では給与を降順にするSELECT * FROM users ORDER BY city, salary DESC;なぜ ORDER BY は最後に書くことが多いのか?
Section titled “なぜ ORDER BY は最後に書くことが多いのか?”並び替えは次のようなものだからです。
- まず結果を出して、最後にどう見せるかを決める
これは、
- 先に絞り込む
- 先にグループ化する
という処理とは、同じ段階ではありません。
四、集計関数とグループ化(GROUP BY)
Section titled “四、集計関数とグループ化(GROUP BY)”よく使う集計関数
Section titled “よく使う集計関数”| 関数 | 役割 | 例 |
|---|---|---|
COUNT(*) | 件数を数える | レコードが全部で何件あるか |
SUM(col) | 合計を出す | 総給与 |
AVG(col) | 平均を出す | 平均年齢 |
MAX(col) | 最大値を出す | 最高給与 |
MIN(col) | 最小値を出す | 最低年齢 |
-- 基本的な集計SELECT COUNT(*) AS 総人数, AVG(salary) AS 平均給与, MAX(salary) AS 最高給与FROM users;GROUP BY:グループごとに集計する
Section titled “GROUP BY:グループごとに集計する”-- 都市ごとに人数と平均給与を集計SELECT city, COUNT(*) AS 人数, AVG(salary) AS 平均給与FROM usersGROUP BY city;city | 人数 | 平均給与北京 | 2 | 25000.0上海 | 2 | 20000.0广州 | 1 | 8000.0深圳 | 1 | 12000.0HAVING:グループ化した結果を絞り込む
Section titled “HAVING:グループ化した結果を絞り込む”-- 平均給与が 15000 を超える都市を探すSELECT city, AVG(salary) AS avg_salaryFROM usersGROUP BY cityHAVING avg_salary > 15000;SQL の実行順
Section titled “SQL の実行順”SQL は、書く順番と実行順が違います。
flowchart TD A["1. FROM<br/>データの出所を決める"] --> B["2. WHERE<br/>元の行を絞る"] B --> C["3. GROUP BY<br/>グループ化する"] C --> D["4. HAVING<br/>グループを絞る"] D --> E["5. SELECT<br/>列を選ぶ"] E --> F["6. ORDER BY<br/>並び替える"] F --> G["7. LIMIT<br/>件数を制限する"]
style A fill:#e3f2fd,stroke:#1565c0,color:#333 style E fill:#fff3e0,stroke:#e65100,color:#333五、複数テーブルの結合(JOIN)
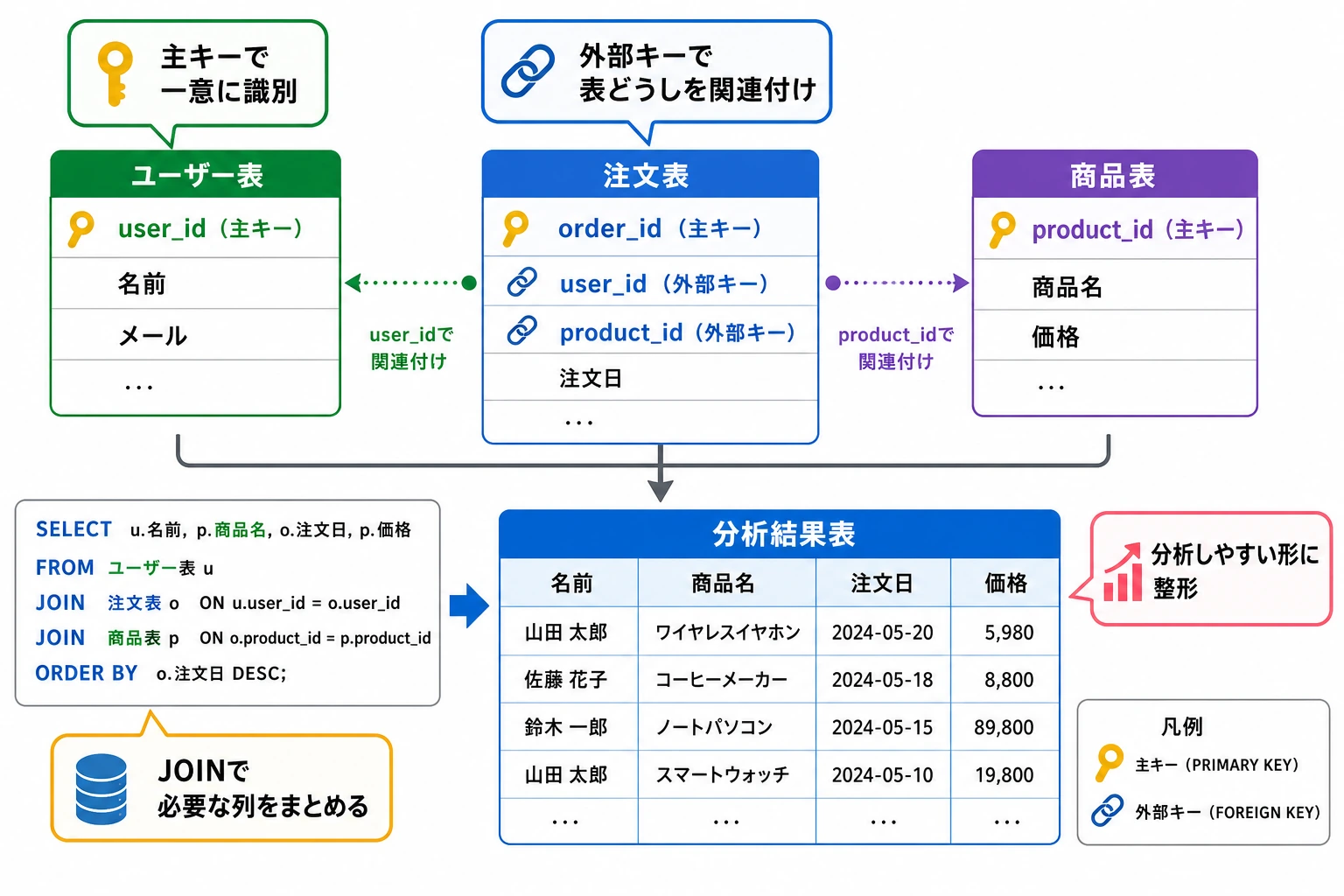
Section titled “五、複数テーブルの結合(JOIN)”JOIN は SQL の最も強力な機能の1つで、複数のテーブルのデータをまとめることができます。
INNER JOIN:内部結合
Section titled “INNER JOIN:内部結合”両方のテーブルに一致する行だけを返します。
-- 各ユーザーの注文情報を検索SELECT users.name, orders.product, orders.amountFROM usersINNER JOIN orders ON users.id = orders.user_id;| name | product | amount |
|---|---|---|
| 张三 | iPhone | 7999.0 |
| 张三 | AirPods | 999.0 |
| 李四 | MacBook | 14999.0 |
| 王五 | iPad | 3999.0 |
| 李四 | キーボード | 599.0 |
| 赵六 | モニター | 2999.0 |
| 钱七 | マウス | 299.0 |
注意:孙八 には注文がないので、結果には出てきません。
LEFT JOIN:左結合
Section titled “LEFT JOIN:左結合”左側のテーブルの行をすべて返し、右側で一致しないものは NULL になります。
-- すべてのユーザーとその注文を検索する(注文がないユーザーも表示)SELECT users.name, orders.product, orders.amountFROM usersLEFT JOIN orders ON users.id = orders.user_id;name | product | amount张三 | iPhone | 7999.0张三 | AirPods | 999.0李四 | MacBook | 14999.0...孙八 | None | None ← 注文がないが、表示されているJOIN の種類の比較
Section titled “JOIN の種類の比較”flowchart TD A["JOIN の種類"] --> B["INNER JOIN<br/>両方にあるものだけ"] A --> C["LEFT JOIN<br/>左を全部、右がなければ NULL"] A --> D["RIGHT JOIN<br/>右を全部、左がなければ NULL"] A --> E["FULL OUTER JOIN<br/>両方を全部"]
style B fill:#e8f5e9,stroke:#2e7d32,color:#333 style C fill:#e3f2fd,stroke:#1565c0,color:#333 style D fill:#fff3e0,stroke:#e65100,color:#333 style E fill:#f3e5f5,stroke:#7b1fa2,color:#333実用的な組み合わせ:JOIN + GROUP BY
Section titled “実用的な組み合わせ:JOIN + GROUP BY”-- 各ユーザーの注文総額を検索SELECT users.name, COUNT(orders.order_id) AS 注文数, SUM(orders.amount) AS 総消費額FROM usersLEFT JOIN orders ON users.id = orders.user_idGROUP BY users.id, users.nameORDER BY 総消費額 DESC;六、追加・更新・削除(INSERT / UPDATE / DELETE)
Section titled “六、追加・更新・削除(INSERT / UPDATE / DELETE)”データを追加する
Section titled “データを追加する”-- 1件追加INSERT INTO users (name, age, city, salary) VALUES ('周九', 29, '杭州', 16000);
-- 複数件追加INSERT INTO users (name, age, city, salary) VALUES ('吴十', 33, '成都', 13000), ('郑十一', 27, '南京', 11000);データを更新する
Section titled “データを更新する”-- 张三 に昇給を反映するUPDATE users SET salary = 18000 WHERE name = '张三';
-- 北京の社員全員を10%昇給するUPDATE users SET salary = salary * 1.1 WHERE city = '北京';データを削除する
Section titled “データを削除する”-- 指定したレコードを削除DELETE FROM users WHERE name = '周九';
-- 20歳未満をすべて削除DELETE FROM users WHERE age < 20;SQL を最初に学ぶときの、いちばん安定した順番
Section titled “SQL を最初に学ぶときの、いちばん安定した順番”基本的には、次の順番が学びやすいです。
- まず
SELECT / FROM / WHEREをしっかり書けるようにする - 次に
ORDER BYを足す - 次に
GROUP BY / HAVINGを足す - 最後に
JOINと追加・更新・削除を学ぶ
最初から全部の文法ブロックを覚えようとするより、ずっと混乱しにくくなります。
SQL 文の速習表
Section titled “SQL 文の速習表”| 操作 | SQL 文法 | 説明 |
|---|---|---|
| 全件検索 | SELECT * FROM 表名 | すべてのデータを取る |
| 指定列の検索 | SELECT 列1, 列2 FROM 表名 | 一部の列を取る |
| 条件フィルタ | SELECT ... WHERE 条件 | 行を絞り込む |
| 並び替え | ORDER BY 列 DESC | 降順に並べる |
| 件数制限 | LIMIT 10 | 先頭 N 件を取る |
| 重複除去 | SELECT DISTINCT 列 | 一意な値を取る |
| 集計 | COUNT / SUM / AVG / MAX / MIN | 統計計算をする |
| グループ化 | GROUP BY 列 | グループごとに集計する |
| グループの絞り込み | HAVING 条件 | 集計結果を絞る |
| 内部結合 | INNER JOIN 表 ON 条件 | 2つの表の共通部分 |
| 左結合 | LEFT JOIN 表 ON 条件 | 左表をすべて返す |
| 追加 | INSERT INTO 表 VALUES (...) | データを追加する |
| 更新 | UPDATE 表 SET 列=値 WHERE 条件 | データを変更する |
| 削除 | DELETE FROM 表 WHERE 条件 | データを削除する |
このページを終えたら、この evidence card を残します。
- スキーマ
- テーブル名、キー、関係、サンプル行
- クエリ
- 使われた SQL または Python のデータベースコード
- 出力
- result rows、row count、または保存された抽出結果
- 失敗確認
- 間違った結合キー、危険なクエリ、トランザクション不足、またはスキーマ不一致
- 期待される成果
- クエリと結果表、および1件のデータ品質メモ
SQL はデータベースと「会話する」ための言語です。核になるのは次の4種類の操作です。
| 分類 | キーワード | 役割 |
|---|---|---|
| 検索 | SELECT | データを検索する(最もよく使う) |
| 追加 | INSERT | 新しいデータを入れる |
| 更新 | UPDATE | 既存データを変更する |
| 削除 | DELETE | データを削除する |
この中でも、SELECT に WHERE、JOIN、GROUP BY を組み合わせると、データ分析のほとんどの要求に対応できます。
この節でいちばん持ち帰ってほしいこと
Section titled “この節でいちばん持ち帰ってほしいこと”- SQL で大事なのは、キーワードの数ではなく、表に安定して質問できるかどうか
- 「どの列がほしいか、どの行がほしいか、どう分けるか」を先に考えてから SQL を書くと、文法を丸暗記するよりずっと安定する
WHERE / GROUP BY / JOINの3つの考え方がわかると、その後の多くのクエリは分解して理解できる
手を動かして練習しよう
Section titled “手を動かして練習しよう”練習 1:基本検索
Section titled “練習 1:基本検索”-- 上の練習用データベースを使って、次の検索を完成させてください。-- 1. 上海のユーザーをすべて検索-- 2. 給与が高い順に上位3人を検索-- 3. 都市ごとの平均給与を検索し、平均給与の高い順に並べる練習 2:JOIN 検索
Section titled “練習 2:JOIN 検索”-- 1. すべてのユーザーの名前と、購入した商品を検索-- 2. 注文したことがないユーザーを検索-- ヒント:LEFT JOIN + WHERE orders.order_id IS NULL-- 3. 注文がないユーザーも含めて、ユーザーごとの注文総額を検索する(0 と表示)練習 3:総合分析
Section titled “練習 3:総合分析”-- 1本の SQL で次を完成させてください:-- 総消費額が 5000 を超えるユーザーの名前、注文数、総消費額を検索-- 総消費額の高い順に並べる参考実装と解説
- フィルタ問題は
WHERE、並べ替えと top-k はORDER BY ... LIMIT、都市別平均はGROUP BY cityとAVG(...)を使います。 - 注文レポートでは、注文がある顧客だけでよければ
JOIN、注文がない顧客も残すならLEFT JOINを使います。COALESCEは null の合計金額を 0 と表示するのに便利です。 - 合計金額がしきい値を超えるような集計後の条件は、先に集計して
HAVINGを使います。集計結果に依存するためWHEREではありません。