6.5.3 Transformer アーキテクチャ
- Transformer block を実行できるデータフローとして読める。
- 残差接続、LayerNorm、FFN を層名の暗記ではなく役割で説明できる。
- PyTorch の例を動かして主要な shape を読める。
- encoder-only、decoder-only、encoder-decoder を区別できる。
- 現代 LLM decoder が pre-norm、RMSNorm、RoPE、GQA/MQA、SwiGLU を使う理由を理解する。
まず Block 図を見る
Section titled “まず Block 図を見る”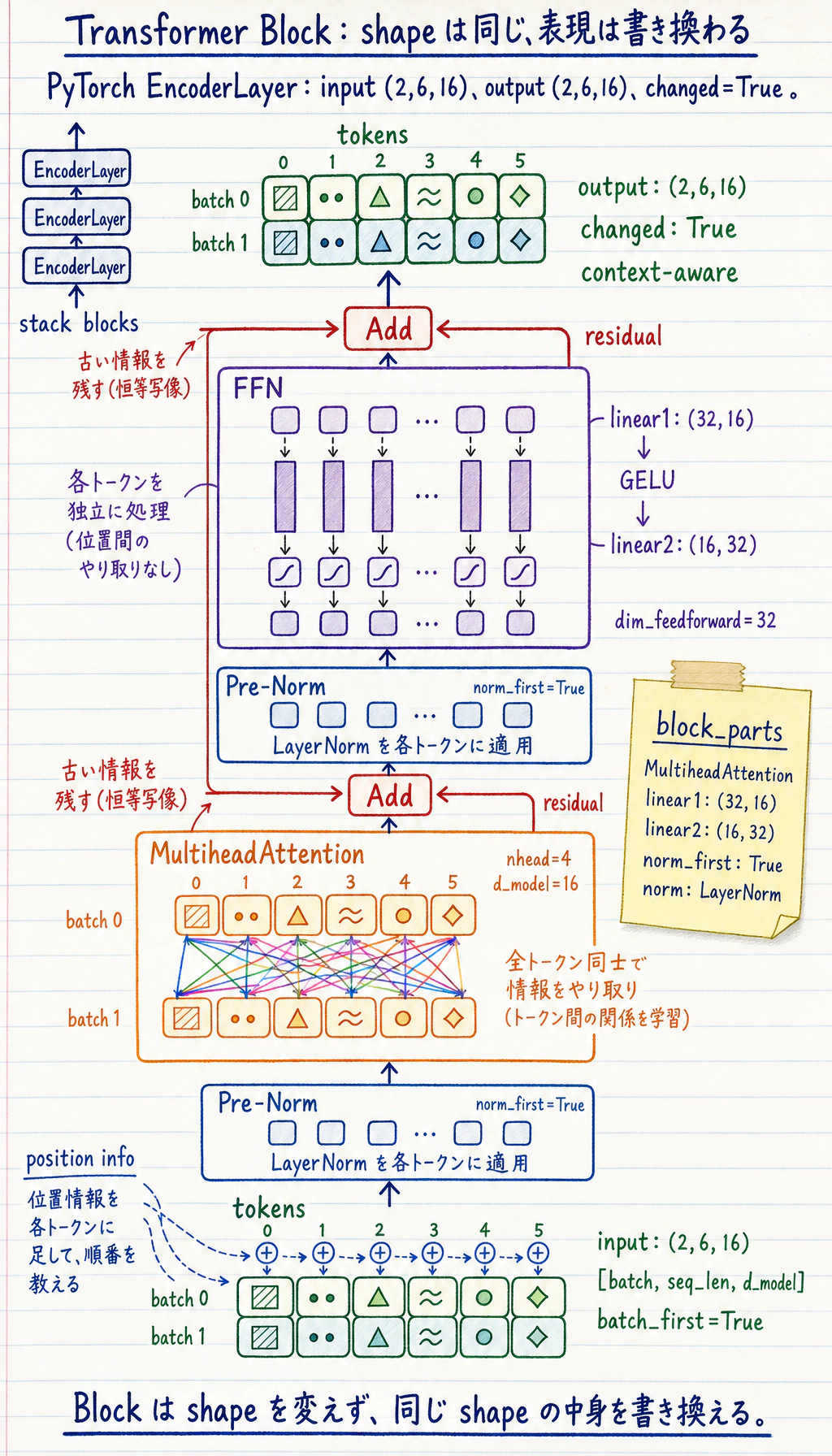
Transformer block は、多くの場合、外側の shape を保ちます。
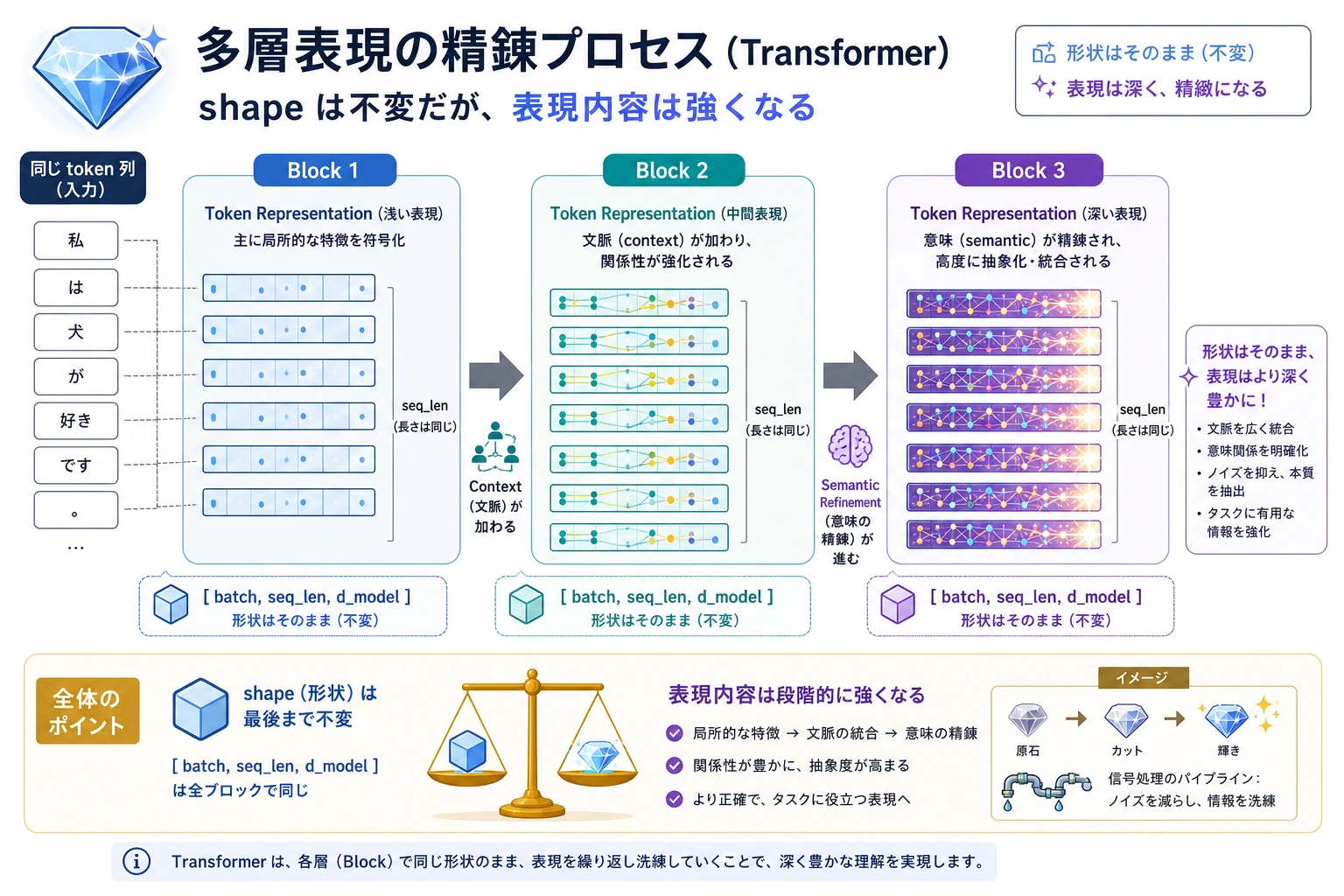
[batch, seq_len, d_model] -> [batch, seq_len, d_model]shape は同じでも、表現はより文脈を含んだものになります。
| 部品 | 何をするか | なぜ重要か |
|---|---|---|
| Multi-head attention | token 位置の間で情報を混ぜる | 文脈を作る |
| 残差接続 | 入力を足し戻す | 情報と勾配を守る |
| LayerNorm / RMSNorm | 特徴量のスケールを安定させる | 深い学習をしやすくする |
| FFN | 各位置を独立に変換する | 非線形な加工能力を足す |
| 位置情報 | token の順序を伝える | Attention だけでは順序が弱い |
実験 1:PyTorch の Transformer Block を調べる
Section titled “実験 1:PyTorch の Transformer Block を調べる”import torchfrom torch import nn
torch.manual_seed(42)
layer = nn.TransformerEncoderLayer( d_model=16, nhead=4, dim_feedforward=32, batch_first=True, norm_first=True, dropout=0.0,)
print("block_parts")print(type(layer.self_attn).__name__)print("linear1:", tuple(layer.linear1.weight.shape))print("linear2:", tuple(layer.linear2.weight.shape))print("norm_first:", layer.norm_first)print("norm:", type(layer.norm1).__name__)期待される出力:
block_partsMultiheadAttentionlinear1: (32, 16)linear2: (16, 32)norm_first: Truenorm: LayerNormパラメータの読み方:
d_model=16:各 token 表現が 16 個の特徴量を持つ。nhead=4:attention を 4 つの head に分ける。dim_feedforward=32:FFN は 16 から 32 に広げ、また 16 に戻す。batch_first=True:tensor は[batch, seq_len, d_model]を使う。norm_first=True:pre-norm を使う。深い stack でよく使われる安定した形です。
残差と正規化
Section titled “残差と正規化”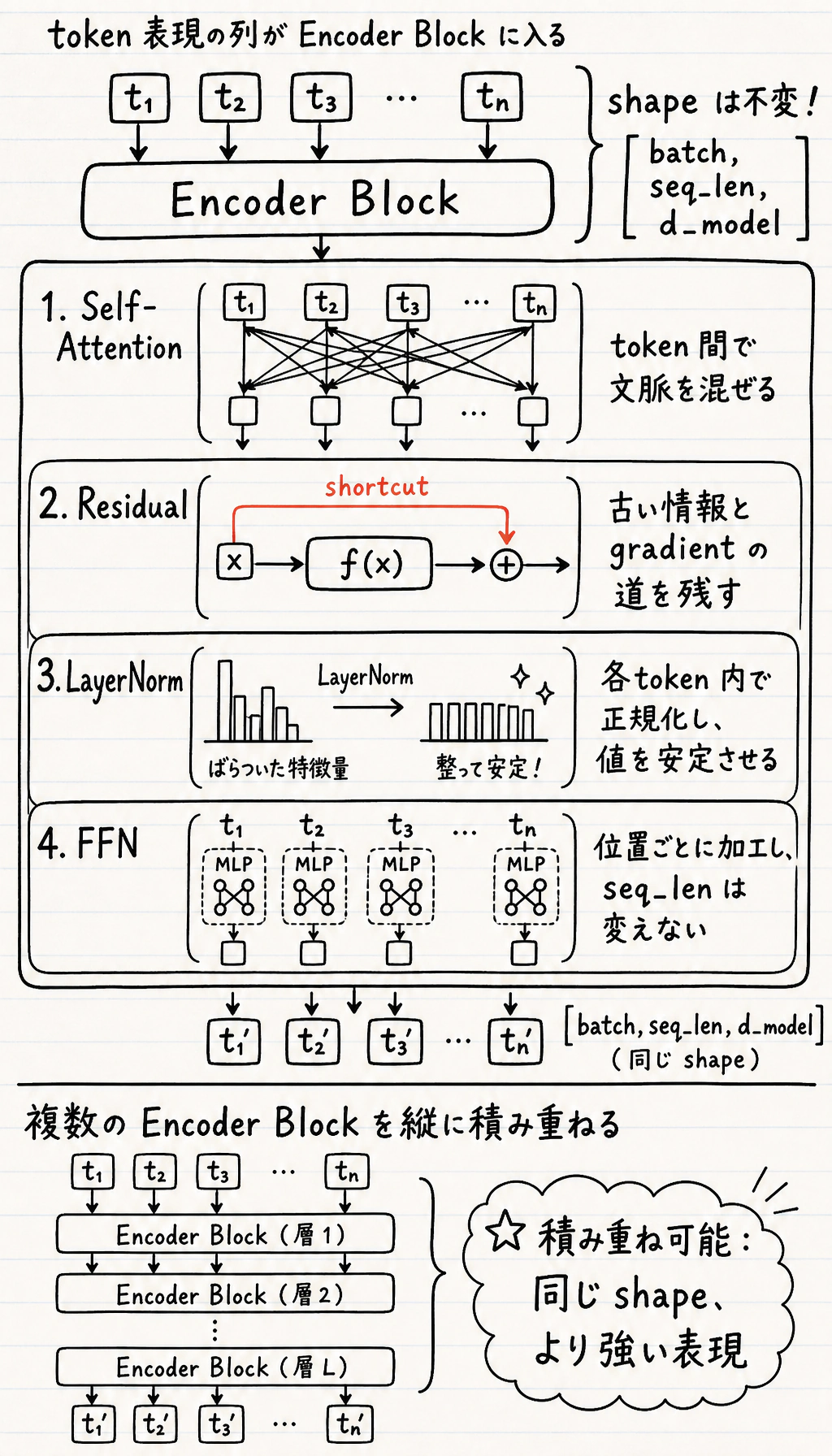
残差接続と正規化は飾りではありません。block を深く積んでも元の信号を失いにくくし、値が不安定になりすぎるのを防ぎます。
実験 2:残差接続
Section titled “実験 2:残差接続”import torch
x = torch.tensor([[1.0, 2.0, 3.0]])f_x = torch.tensor([[0.1, -0.2, 0.3]])
y = x + f_x
print("residual_lab")print(y)期待される出力:
residual_labtensor([[1.1000, 1.8000, 3.3000]])この層は、有用な更新量 f(x) を学べばよいです。元の表現 x は shortcut によって残ります。
実験 3:LayerNorm
Section titled “実験 3:LayerNorm”import torchfrom torch import nn
x = torch.tensor( [ [1.0, 2.0, 3.0, 10.0], [2.0, 2.5, 3.5, 9.0], ])
ln = nn.LayerNorm(4)y = ln(x)
print("layernorm_lab")print(torch.round(y.detach(), decimals=3))print("row_means:", torch.round(y.mean(dim=1).detach(), decimals=4))print("row_stds:", torch.round(y.std(dim=1, unbiased=False).detach(), decimals=4))期待される出力:
layernorm_labtensor([[-0.8490, -0.5660, -0.2830, 1.6970], [-0.8050, -0.6260, -0.2680, 1.6990]])row_means: tensor([0., 0.])row_stds: tensor([1., 1.])LayerNorm は各 token の特徴次元に対して正規化します。batch をまたいで正規化するわけではありません。
FFN:同じ位置を、より強く変換する
Section titled “FFN:同じ位置を、より強く変換する”Attention は位置をまたいで情報を混ぜます。その後、フィードフォワードネットワークが各位置を独立に加工します。
import torchfrom torch import nn
torch.manual_seed(42)
x = torch.randn(2, 5, 8)
ffn = nn.Sequential( nn.Linear(8, 32), nn.GELU(), nn.Linear(32, 8),)
y = ffn(x)
print("ffn_lab")print("input:", tuple(x.shape))print("output:", tuple(y.shape))期待される出力:
ffn_labinput: (2, 5, 8)output: (2, 5, 8)FFN は内部では hidden size を広げますが、最後に元の次元へ戻します。系列長は変わりません。
Self-attention は token 同士を比較できますが、token が最初なのか、2 番目なのか、最後なのかを自然には知りません。位置情報はその順序を補います。
import torch
positions = torch.arange(5).float().unsqueeze(1)dims = torch.arange(0, 8, 2).float()angle_rates = 1 / (10000 ** (dims / 8))angles = positions * angle_rates
pe = torch.zeros(5, 8)pe[:, 0::2] = torch.sin(angles)pe[:, 1::2] = torch.cos(angles)
print("positional_lab")print(torch.round(pe[:3], decimals=4))期待される出力:
positional_labtensor([[ 0.0000, 1.0000, 0.0000, 1.0000, 0.0000, 1.0000, 0.0000, 1.0000], [ 0.8415, 0.5403, 0.0998, 0.9950, 0.0100, 1.0000, 0.0010, 1.0000], [ 0.9093, -0.4161, 0.1987, 0.9801, 0.0200, 0.9998, 0.0020, 1.0000]])現代 LLM では、この古典的な sinusoidal 方式ではなく RoPE がよく使われます。実務上の目的は同じで、attention に順序と相対距離の手がかりを与えることです。
実験 4:Encoder Block を 1 つ動かす
Section titled “実験 4:Encoder Block を 1 つ動かす”import torchfrom torch import nn
torch.manual_seed(42)
encoder_layer = nn.TransformerEncoderLayer( d_model=16, nhead=4, dim_feedforward=32, batch_first=True, norm_first=True, dropout=0.0,)
tokens = torch.randn(2, 6, 16)out = encoder_layer(tokens)
print("encoder_shape_lab")print("input:", tuple(tokens.shape))print("output:", tuple(out.shape))print("changed:", bool(torch.not_equal(tokens, out).any()))期待される出力:
encoder_shape_labinput: (2, 6, 16)output: (2, 6, 16)changed: Trueshape は変わりませんが、各 token は他の token の文脈を使って書き換えられています。
Encoder、Decoder、Encoder-Decoder
Section titled “Encoder、Decoder、Encoder-Decoder”| 系統 | 代表モデル | 主な用途 | Attention のパターン |
|---|---|---|---|
| Encoder-only | BERT | 理解、分類 | 双方向 self-attention |
| Decoder-only | GPT 系 LLM | 生成 | causal self-attention |
| Encoder-decoder | T5、元の Transformer | ある系列を読み、別の系列を生成する | encoder self-attention と decoder cross-attention |
実験 5:Decoder Shape と Cross-Attention
Section titled “実験 5:Decoder Shape と Cross-Attention”import torchfrom torch import nn
torch.manual_seed(42)
decoder_layer = nn.TransformerDecoderLayer( d_model=16, nhead=4, dim_feedforward=32, batch_first=True, norm_first=True, dropout=0.0,)
target = torch.randn(2, 3, 16)memory = torch.randn(2, 5, 16)causal_mask = nn.Transformer.generate_square_subsequent_mask(target.size(1))
out = decoder_layer(target, memory, tgt_mask=causal_mask)
print("decoder_shape_lab")print("target:", tuple(target.shape))print("memory:", tuple(memory.shape))print("mask:", tuple(causal_mask.shape))print("output:", tuple(out.shape))期待される出力:
decoder_shape_labtarget: (2, 3, 16)memory: (2, 5, 16)mask: (3, 3)output: (2, 3, 16)こう読みます。
targetは decoder がここまで生成している側です。memoryは encoder の出力です。causal_maskは decoder 内で未来を見ないようにします。- Cross-attention によって decoder はエンコード済み入力を見られます。
初期 Transformer と現代 LLM Decoder
Section titled “初期 Transformer と現代 LLM Decoder”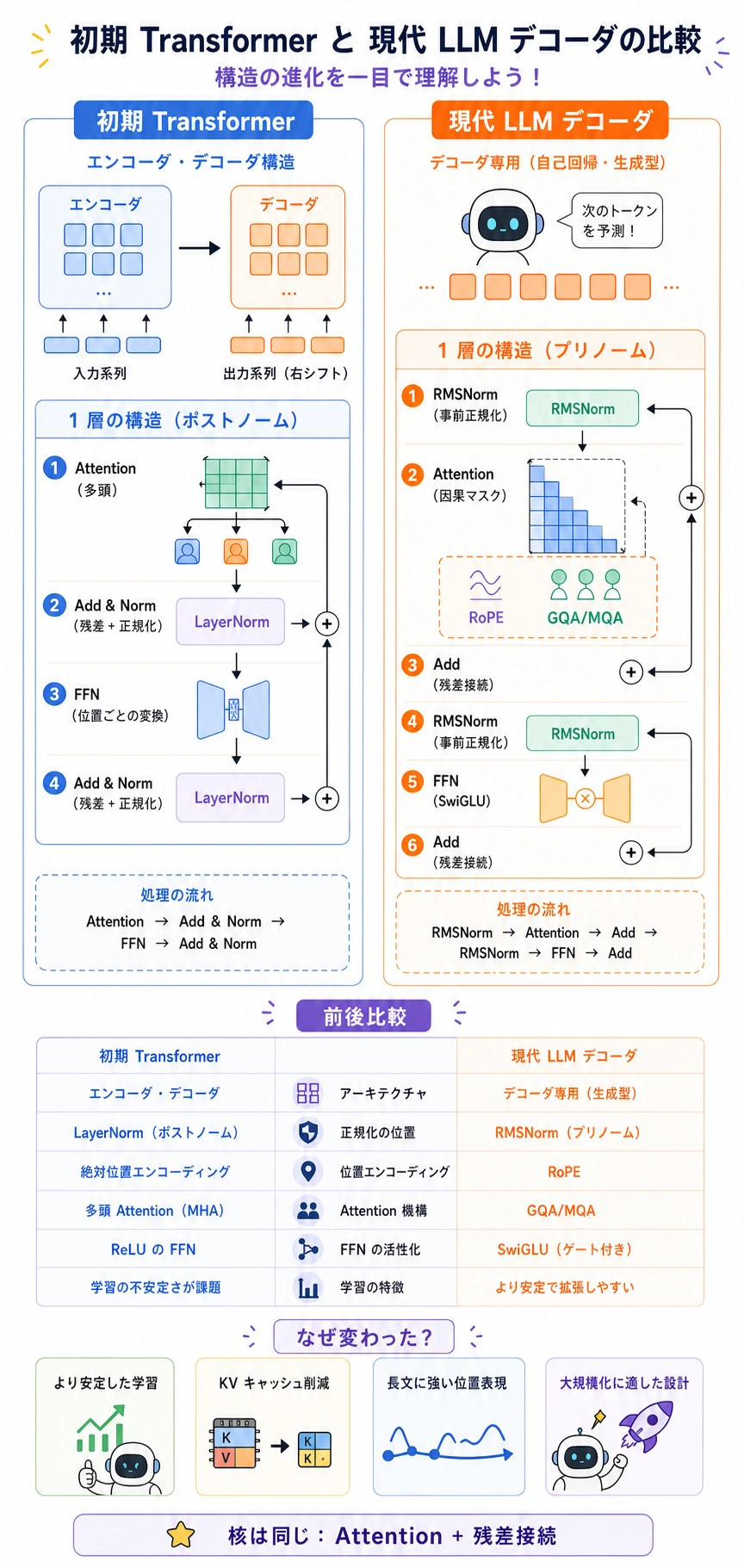
| 部分 | 初期 Transformer | 現代 LLM decoder | なぜ変わったか |
|---|---|---|---|
| 正規化 | attention/FFN の後に LayerNorm | pre-norm、よく RMSNorm | 深い stack が安定しやすい |
| 位置情報 | absolute または sinusoidal position | RoPE | 相対位置を扱いやすい |
| attention head | 通常の multi-head attention | 多くのモデルで GQA または MQA | 推論時の KV-cache メモリを減らす |
| FFN | ReLU/GELU FFN | SwiGLU 系のゲート付き FFN | スケーリングしやすい |
| アーキテクチャ | encoder-decoder が多い | decoder-only が多い | next-token prediction が大規模化しやすい |
用語をやさしく読むと:
- RMSNorm:特徴量の root mean square でスケールを整える、比較的軽い正規化。
- RoPE:位置情報を attention 空間に回転として入れ、相対距離を使いやすくする方法。
- GQA:grouped-query attention。複数の query head が key/value head を共有する。
- MQA:multi-query attention。多くの query head が 1 組の key/value を共有する。
- SwiGLU:ゲート付き FFN。変換された情報をどれだけ通すかを調整する。
重要な理解:
元の Transformer は block の型を示した。現代 LLM decoder は、その block を超深い生成モデル向けに訓練しやすく、推論しやすくした。LLM への橋:block 出力から次の token へ
Section titled “LLM への橋:block 出力から次の token へ”Transformer block は、ユーザーに直接「答える」わけではありません。token 表現を書き換えます。Decoder-only LLM はこの block を何層も積み、最後の表現を語彙スコアへ写します。
tokens-> embeddings + position-> repeated decoder blocks-> final hidden states-> vocabulary logits-> next-token choice最後の 2 つの手順を丁寧に読みます。
| 手順 | やさしい意味 | 第 7 章で重要な理由 |
|---|---|---|
| vocabulary logits | 次に来る可能性のある各 token へのスコア | モデルはここで続き候補を順位づけする |
| decoding | そのスコアから次の token を選ぶ、またはサンプリングする | temperature、top-p、停止ルールが見える挙動を変える |
橋渡しはこうです。
第 6 章:block が表現をどう書き換えるか。第 7 章:書き換えられた表現がどう生成テキストになるか。これにより Prompt が重要な理由も分かります。Prompt は入力 token と文脈を変え、それが hidden states を変え、最終的に next-token score を変えます。
Transformer block card を 1 つ残します。
- ブロック形状
- [batch, seq_len, d_model] が同じまま
- 内容変化
- トークン表現が文脈を考慮するようになる
- 安定性要素
- residual + norm
- トークン構成
- attention は位置を混合し、FFN は各位置を変換する
- 生成への橋渡し
- 最終隠れ状態 → 語彙ロジット → 次のトークン
よくある間違い
Section titled “よくある間違い”| 間違い | 直し方 |
|---|---|
| Transformer は attention だけだと思う | 残差、正規化、FFN、位置情報も一緒に見る |
| tensor shape だけを見る | shape が同じでも表現の中身は変わる |
| encoder と decoder を混同する | 未来 token が見えるか、cross-attention があるかを見る |
batch_first を無視する | [batch, seq, dim] か [seq, batch, dim] かを必ず確認する |
| 現代 LLM block を 2017 年版と同じだと思う | pre-norm、RMSNorm、RoPE、GQA/MQA、ゲート付き FFN を学ぶ |
- 実験 4 で
d_modelを32に変えてください。他にどのパラメータを変える必要がありますか。 - 実験 1 で
norm_first=Falseにしてください。これはどのアーキテクチャパターンを表しますか。 - FFN は内部で次元を広げるのに、なぜ出力 shape が入力と同じなのか説明してください。
- 実験 5 で
targetの長さを3から4に変えてください。causal_maskはどう変わる必要がありますか。 - GQA/MQA が推論メモリに効く理由を 1 段落で説明してください。
参考実装と解説
- Embedding、positional encoding、attention layer、FFN の入出力次元を
d_model=32にそろえる必要があります。また、nheadが32を割り切れることも確認します。 norm_first=Falseは post-norm Transformer block を表します。residual addition の後に normalization を置く形です。- FFN は内部で hidden dimension を広げ、非線形を通したあと、再び
d_modelに射影します。だから元の tensor と residual addition できます。 - target sequence length が
4になるので、causal_maskも対応する4 x 4mask になり、未来位置を遮る必要があります。 - GQA/MQA は key/value heads を共有または削減し、autoregressive decoding 中の KV cache を小さくします。これによりメモリ帯域と使用量が下がり、長い context の推論が軽くなります。
- Transformer block は attention に加えて、安定化と変換の仕組みを持つ。
- 残差接続は古い情報を残し、各層が更新量を学べるようにする。
- 正規化は深い stack を訓練しやすくする。
- FFN は attention が文脈を混ぜたあと、各 token をさらに加工する。
- 現代 LLM decoder は Transformer の考え方を保ちつつ、規模と推論効率に合わせて最適化されている。