11.0 学習チェックリスト:自然言語処理
このページは印刷用チェックリストとして使います。詳しい説明が必要なときは、第 11 章入口ページ に戻ってください。
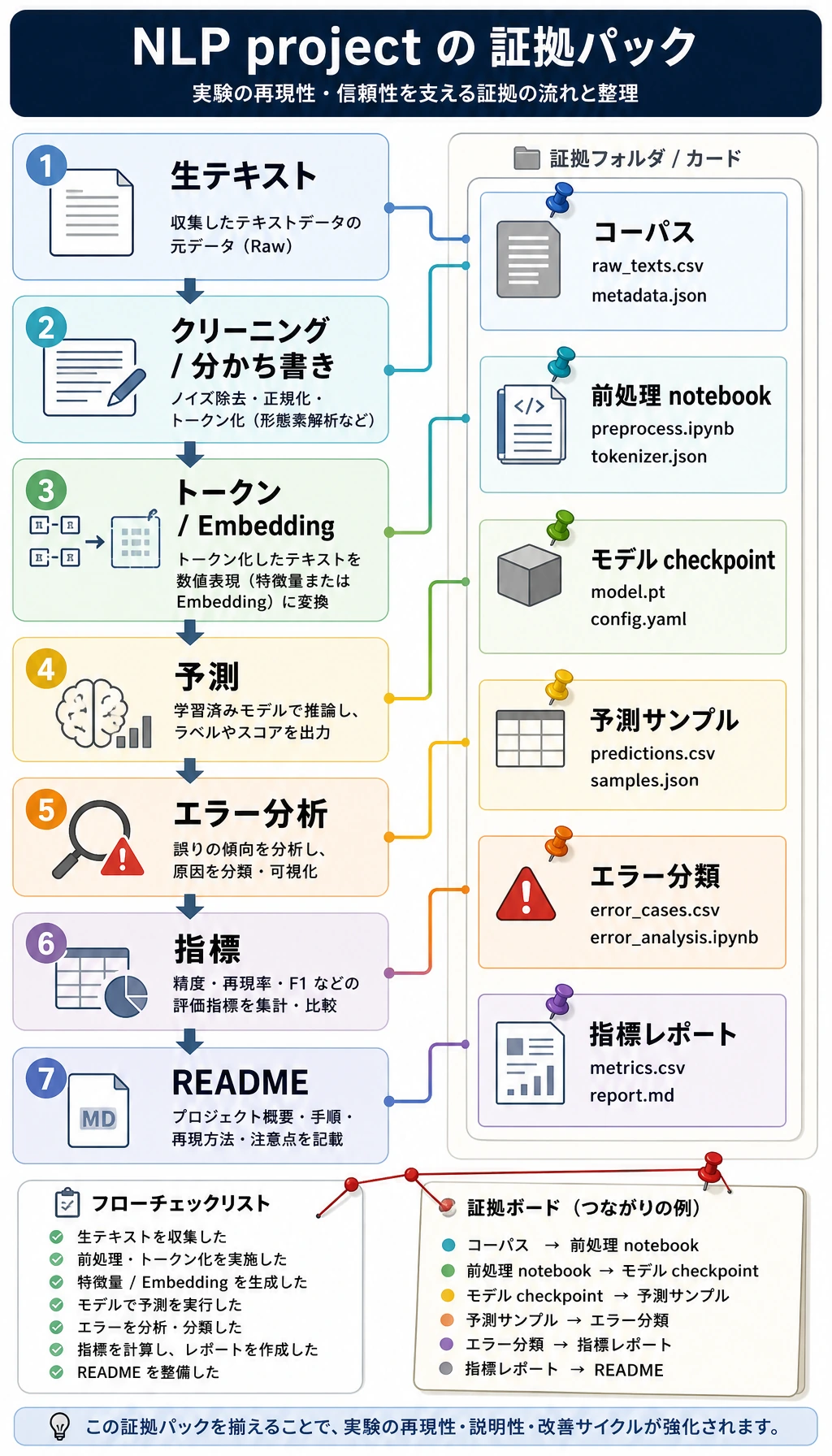
2時間の初回通読
Section titled “2時間の初回通読”| 時間 | やること | ここまで言えたら止める |
|---|---|---|
| 20 分 | テキストからタスクへの流れを見る | 「NLP は生テキストから始まり、評価可能な出力で終わる。」 |
| 25 分 | ラベル評価スクリプトを動かす | 「予測ラベルと期待ラベルを比較できる。」 |
| 25 分 | 11.1 テキスト前処理をざっと読む | 「cleaning は意味によって助けにも害にもなる。」 |
| 25 分 | 分類、抽出、生成のロードマップをざっと読む | 「タスクは出力で定義される。」 |
| 25 分 | タスク出力図を読む | 「出力タイプから指標を選べる。」 |
必ず残す証拠
Section titled “必ず残す証拠”| 証拠 | 最小版 |
|---|---|
text_cleaning.py | cleaning、tokenization、before/after 例 |
label_guide.md | label 定義、境界ケース、正例と反例 |
classification_report.md | 指標、混同行列またはエラー表、モデル比較 |
extraction_examples.jsonl | 元文、抽出フィールド、検証結果 |
failure_cases.md | 紛らわしいラベル、欠損フィールド、根拠なし事実、悪い要約 |
README.md | タスク目標、実行コマンド、入出力、指標、制限 |
| ゲート | 合格条件 |
|---|---|
| ラベル/schema 境界 | ラベルまたはフィールドに positive、negative、境界例がある。 |
| ベースライン | ルール、TF-IDF、シンプルモデル、LLM ベースラインが同じ固定評価ケースで動く。 |
| 事実性 | 生成された summary/answer が fluency だけでなく出典証拠で確認される。 |
| エラーレビュー | 混同、欠落フィールド、根拠のない事実、悪い要約に原因と次のテストがある。 |
章を出る前の質問
Section titled “章を出る前の質問”- 生テキストが token とモデル入力になる流れを説明できますか?
- training や prompting の前にラベル境界を定義できますか?
- タスクが分類、抽出、検索、生成のどれを必要とするか判断できますか?
- 要約や回答の事実一貫性を評価できますか?
- 伝統的 NLP 手法で足りる場合と、LLM が役立つ場合を説明できますか?
答えがすべて「はい」なら、NLP の考え方を Prompt、RAG、Agent memory、マルチモーダル作業により安定して使えます。
確認の考え方と解説
- 良い答えは、raw text から tokens、representation、model input、prediction、metric、failure case までの流れを説明できます。
- label boundary は、positive examples、negative examples、edge cases、意見が分かれたときの rule があるときに準備できたと言えます。
- fixed labels なら classification、fields なら extraction、evidence lookup なら retrieval、新しい text なら generation を選びます。複数 step が必要なら hybrid にします。
- factual consistency とは、generated summary/answer の各主張を source evidence に戻せることです。fluency だけでは不十分です。
- task が小さく透明で安定しているなら traditional NLP で十分なことがあります。言語の揺れ、generation、context reasoning が大きい場合は LLM が役立ちます。
このページを終えたら、この evidence card を残します。
- タスク出力
- ラベル、entity fields、要約、回答、retrieval 結果、または semantic graph
- 成果物
- 生テキスト、処理済みテキスト、予測、metrics、失敗ケース
- 指標
- accuracy/F1、precision/recall、検索ヒット率、忠実性、またはスキーマ妥当性
- 失敗確認
- 不明確なラベル、過度なクリーニング、境界エラー、ハルシネーション、または裏付けのない回答
- 期待される成果
- 指標と例を含む再現可能なテキストパイプラインフォルダ