5.2.6 SVM:最大マージンとカーネル法
この節では、SVM を小さな実験として動かします。
- 曲がったデータセットで
linearとrbfカーネルを比較する; - SVM で
StandardScalerが重要な理由を実験で確認する; Cとgammaを変え、サポートベクトル数を見る;- SVM を試すべき場面と、集成モデルのほうが楽な場面を判断する。
実務で覚えておきたい一文です。
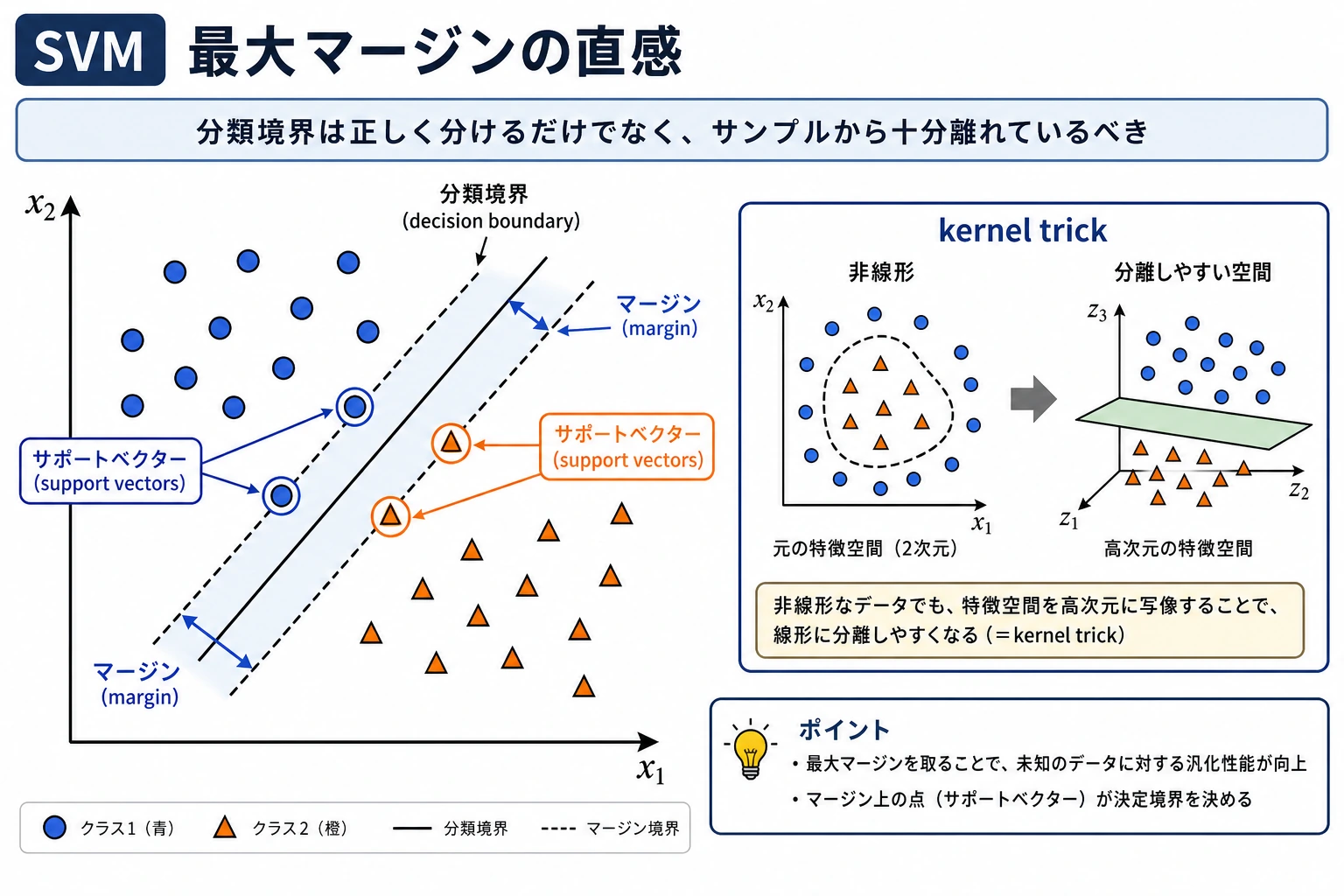
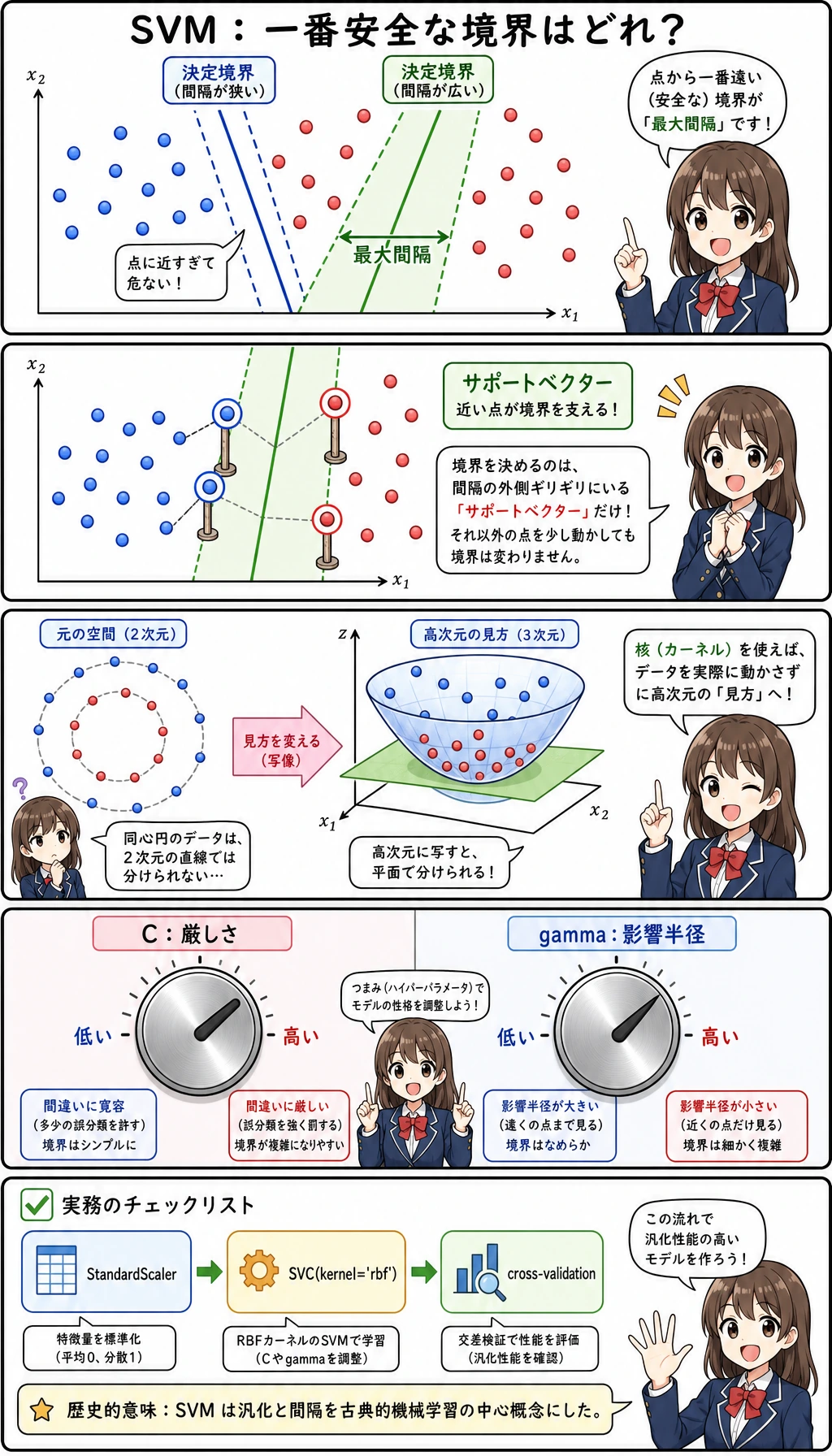
SVM は「分類できたか」だけでなく、「最も近いサンプルから十分に離れた境界を置けるか」を考える。
| 用語 | 実用上の意味 |
|---|---|
SVM | Support Vector Machine。大きなマージンを持つ境界を探す分類器 |
margin | 決定境界から最も近いサンプルまでの距離 |
support vector | 境界の位置に影響する、境界に近い訓練サンプル |
kernel | 非線形境界を作れるようにする類似度関数 |
RBF | Radial Basis Function。よく使われる非線形カーネル |
C | 誤分類への罰則。大きいほど訓練点に強く合わせる |
gamma | RBF におけるサンプルの影響範囲。大きいほど局所的な境界になる |
SVC | sklearn のサポートベクトル分類器 |
セットアップ
Section titled “セットアップ”python -m pip install -U scikit-learnSVM は特徴量の尺度に敏感です。そのため、例では Pipeline(StandardScaler(), SVC(...)) を使います。これは飾りではなく、モデル手順そのものです。
完全な実験を実行する
Section titled “完全な実験を実行する”svm_lab.py を作成します。
from itertools import productfrom sklearn.datasets import make_moonsfrom sklearn.metrics import accuracy_scorefrom sklearn.model_selection import train_test_splitfrom sklearn.pipeline import make_pipelinefrom sklearn.preprocessing import StandardScalerfrom sklearn.svm import SVC
X, y = make_moons(n_samples=400, noise=0.25, random_state=42)X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25, random_state=42, stratify=y)
print("kernel_comparison")for kernel in ["linear", "rbf"]: model = make_pipeline(StandardScaler(), SVC(kernel=kernel, C=1.0, gamma="scale")) model.fit(X_train, y_train) svc = model.named_steps["svc"] print( f"kernel={kernel:<6} " f"accuracy={accuracy_score(y_test, model.predict(X_test)):.3f} " f"support_vectors={int(svc.n_support_.sum())}" )
print("scaling_check")X_bad_scale = X.copy()X_bad_scale[:, 1] *= 100X_train2, X_test2, y_train2, y_test2 = train_test_split( X_bad_scale, y, test_size=0.25, random_state=42, stratify=y)raw = SVC(kernel="rbf", C=1.0, gamma="scale")raw.fit(X_train2, y_train2)scaled = make_pipeline(StandardScaler(), SVC(kernel="rbf", C=1.0, gamma="scale"))scaled.fit(X_train2, y_train2)print(f"without_scaling={accuracy_score(y_test2, raw.predict(X_test2)):.3f}")print(f"with_scaling={accuracy_score(y_test2, scaled.predict(X_test2)):.3f}")
print("c_gamma_lab")for C, gamma in product([0.1, 1.0, 10.0], [0.1, 1.0]): model = make_pipeline(StandardScaler(), SVC(kernel="rbf", C=C, gamma=gamma)) model.fit(X_train, y_train) svc = model.named_steps["svc"] print( f"C={C:<4} gamma={gamma:<3} " f"accuracy={accuracy_score(y_test, model.predict(X_test)):.3f} " f"support_vectors={int(svc.n_support_.sum())}" )実行します。
python svm_lab.py期待される出力:
kernel_comparisonkernel=linear accuracy=0.920 support_vectors=125kernel=rbf accuracy=0.950 support_vectors=98scaling_checkwithout_scaling=0.880with_scaling=0.950c_gamma_labC=0.1 gamma=0.1 accuracy=0.940 support_vectors=187C=0.1 gamma=1.0 accuracy=0.960 support_vectors=173C=1.0 gamma=0.1 accuracy=0.950 support_vectors=134C=1.0 gamma=1.0 accuracy=0.930 support_vectors=87C=10.0 gamma=0.1 accuracy=0.960 support_vectors=111C=10.0 gamma=1.0 accuracy=0.920 support_vectors=57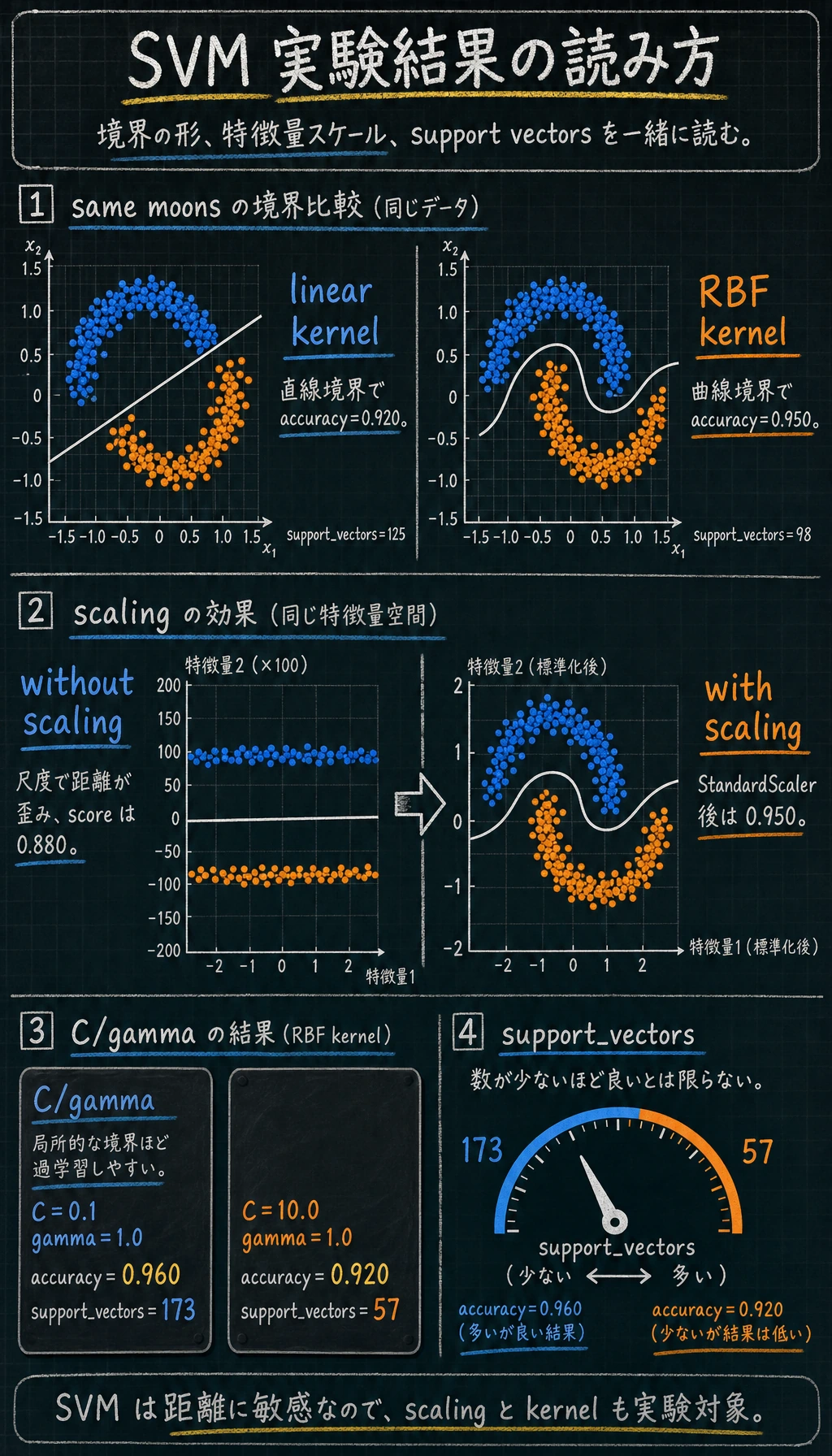
カーネルの結果を読む
Section titled “カーネルの結果を読む”make_moons は曲がったデータセットで、直線境界が少し不利になるように作られています。
kernel=linear accuracy=0.920 support_vectors=125kernel=rbf accuracy=0.950 support_vectors=98linear カーネルは直線で分けようとします。rbf カーネルは局所的な類似度を見るため、曲がった境界を作れます。まずは次の目安で選びます。
| 状況 | SVM の最初の選択 |
|---|---|
| 境界がほぼ直線に見える | kernel="linear" |
| 境界が曲がっていて、データが巨大ではない | kernel="rbf" |
| 行数や特徴量が多い | ロジスティック回帰、線形 SVM、木の集成を先に試す |
スケーリングは任意ではない
Section titled “スケーリングは任意ではない”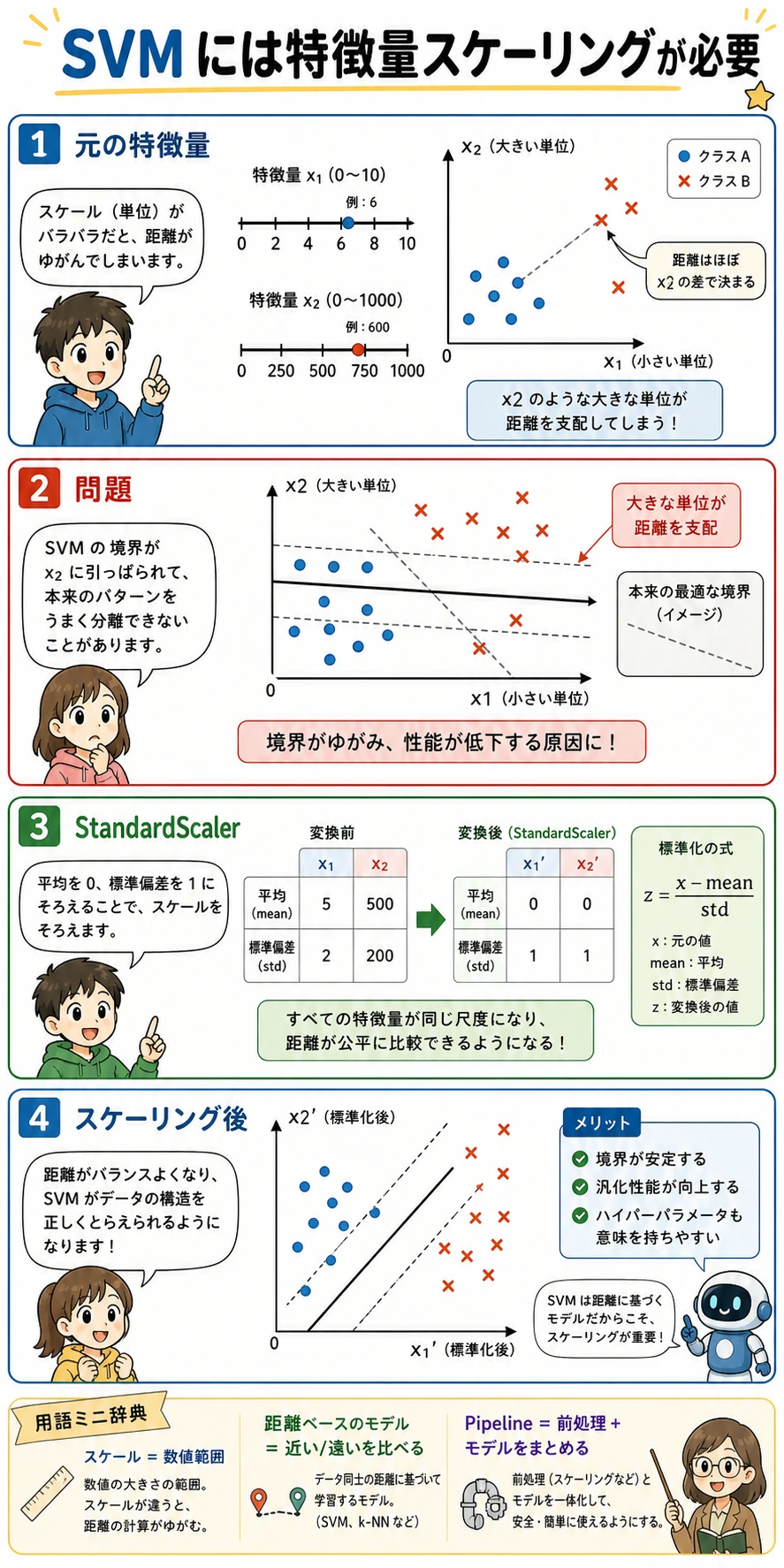
SVM は距離と類似度に依存します。ある特徴量が 0-1、別の特徴量が 0-1000 の範囲を持つと、後者が意味以上に境界を支配することがあります。
実験結果ではっきり見えます。
without_scaling=0.880with_scaling=0.950だから StandardScaler は Pipeline に入れます。スケーラーは訓練 fold だけで fit され、検証/テストデータへ安全に適用されます。
C と gamma を理解する
Section titled “C と gamma を理解する”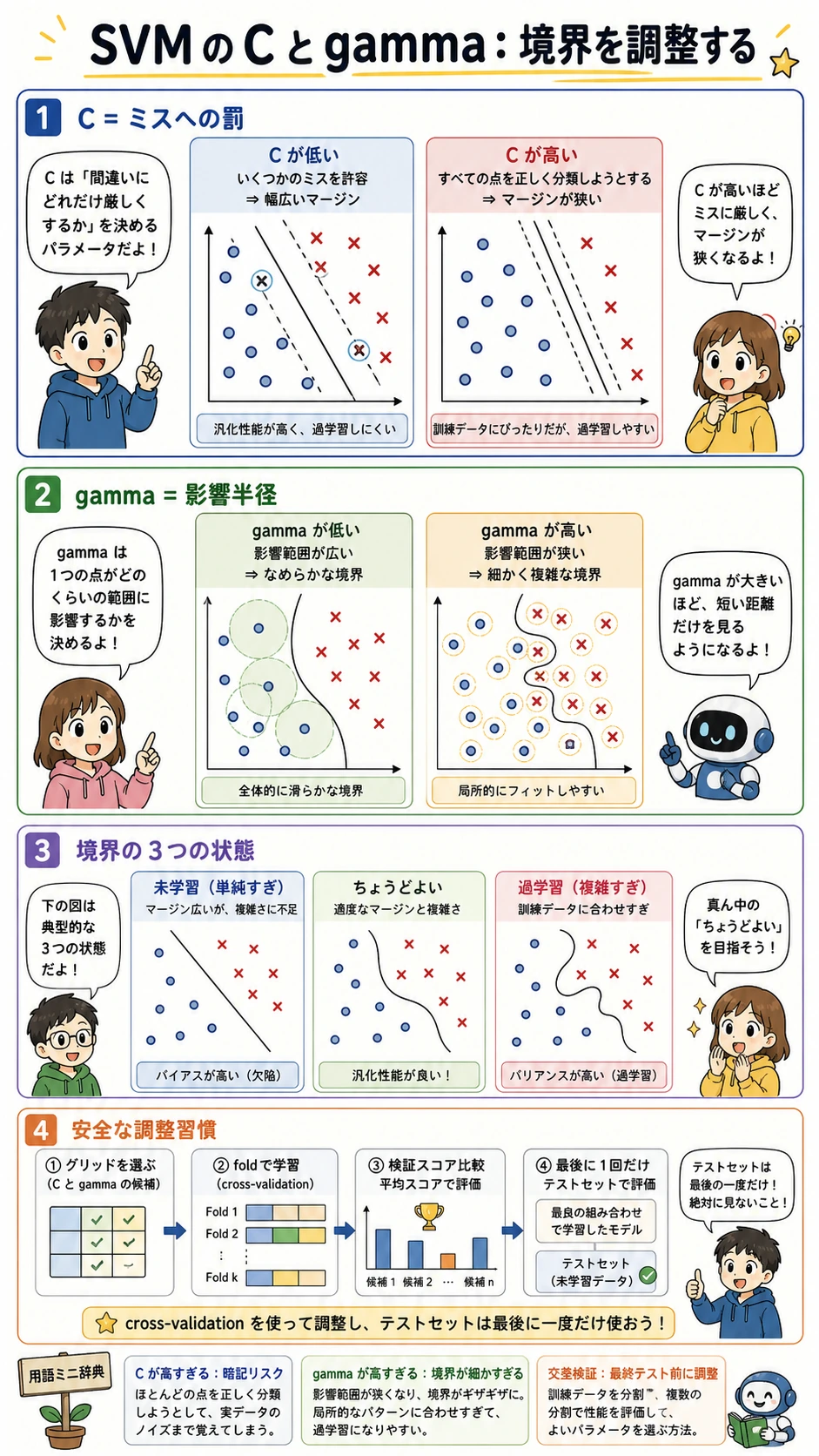
C と gamma は境界の別々の性質を制御します。
| パラメータ | 小さすぎると | 大きすぎると |
|---|---|---|
C | ミスを許しやすく、マージンが広く滑らか | 訓練点を強く追いかける |
gamma | 影響範囲が広く、境界が単純になりやすい | 影響範囲が局所的で、境界が複雑になりやすい |
出力は 2 つの信号を一緒に見ます。
C=0.1 gamma=1.0 accuracy=0.960 support_vectors=173C=10.0 gamma=1.0 accuracy=0.920 support_vectors=57後者はサポートベクトルが少ないのに、テスト accuracy は悪くなっています。サポートベクトルが少ないことは、常に良いわけではありません。境界が鋭すぎて汎化しにくい可能性があります。
経験者向け:C と gamma は交差検証で一緒に調整し、ロジスティック回帰や集成モデルのベースラインとも比較してください。1 回の train-test split だけで SVM を選ばないようにします。
実務でのサポートベクトル
Section titled “実務でのサポートベクトル”サポートベクトルは、境界に近く、境界に影響するサンプルです。直感的な診断に使えます。
- サポートベクトルが多い場合、境界が不確か、またはマージンが柔らかい可能性がある;
- サポートベクトルが少ないのにテストスコアが悪い場合、境界が鋭すぎる可能性がある;
- サポートベクトル数は診断の手がかりであり、最終指標ではない。
校正された確率が必要な場合、SVC(probability=True) は追加の校正ステップを走らせるため学習が重くなります。確率の品質が重要なら、CalibratedClassifierCV を使うほうが設計として明確なことが多いです。
SVM を使う場面
Section titled “SVM を使う場面”SVM を試す価値がある場面:
- データが小規模から中規模;
- 特徴量が数値中心で、安定してスケーリングできる;
- ニューラルネットワークを使わずに強めの非線形分類器がほしい;
- マージンベースの分類を理解したい。
他のモデルを優先したい場面:
- データが非常に大きく、学習速度が重要;
- カテゴリ特徴量が多く、前処理が重い;
- プロダクトが信頼できる確率に強く依存する;
- 木の集成モデルのほうが、少ない調整で高精度かつ安定。
このページを終えたら、この evidence card を残します。
- タスク
- target 定義のある regression または classification 問題
- モデル
- 線形/ロジスティック/木/アンサンブル/SVM の構成と train/test 分割
- 指標
- 回帰誤差、accuracy/F1、閾値曲線、または confusion matrix
- 失敗確認
- 過学習、学習不足、特徴量スケーリング、閾値選択、またはクラス不均衡
- 期待される成果
- モデル結果とエラーサンプル、または残差レビュー
よくあるトラブル
Section titled “よくあるトラブル”| 症状 | よくある原因 | 修正 |
|---|---|---|
| SVM が予想よりかなり悪い | 特徴量をスケーリングしていない | Pipeline 内で StandardScaler を使う |
| 学習が遅い | RBF SVM は大規模データに向きにくい | 線形モデル、LinearSVC、集成モデルを試す |
| 境界が複雑すぎる | gamma または C が大きい | gamma と C を下げ、交差検証する |
| 曲がったパターンを拾えない | 非線形問題に linear を使っている | kernel="rbf" と比較する |
| 信頼できる確率が必要 | 生の SVM スコアは校正確率ではない | 校正を使い、確率指標を確認する |
make_moons()のnoiseを0.25から0.1と0.4に変えてください。SVM が簡単になる/難しくなる設定はどれですか?- グリッドに
gamma=5.0を追加してください。accuracy とサポートベクトル数はどう変わりますか? - 線形の場合に
SVCをLinearSVCに置き換えてください。利用できる属性はどう変わりますか? - 同じデータセットでロジスティック回帰を実行し、RBF SVM と比較してください。
- 1 回の分割ではなく、交差検証で
Cとgammaを選んでください。
参考実装と解説
noise=0.1はクラス境界がはっきりし、SVM にとって簡単です。noise=0.4はクラスが混ざり、過学習と underfitting のバランスが難しくなります。gamma=5.0は RBF kernel の影響範囲を狭くし、境界を曲げやすくします。accuracy は上がることも下がることもあり、サポートベクトル数が多い場合は多くの境界サンプルに依存している可能性があります。LinearSVCは大きめの線形問題に向きますが、support_vectors_は通常なく、predict_proba()も直接は使えません。比較するときはdecision_function、accuracy、学習時間を見ます。- ロジスティック回帰は強い baseline です。RBF SVM が少ししか改善せず、遅くて説明しにくいなら選ぶ価値は限定的です。非線形性が強いデータでは RBF SVM の優位が出やすくなります。
- スケーリングと SVM を同じ
Pipelineに入れ、GridSearchCVでCとgammaを選びます。こうすると各 fold でスケーリングも訓練 fold だけから学びます。
合格チェック
Section titled “合格チェック”次を説明できれば、この節はクリアです。
- SVM は大きなマージンを持つ境界を探す;
- サポートベクトルは境界に重要な訓練サンプル;
- RBF カーネルは曲がった境界を表現できる;
- SVM は距離を使うのでスケーリングが重要;
Cとgammaは一緒に調整し、できれば交差検証を使う。