7.3.1 Transformer 深掘りロードマップ:Block、Mask、コスト
この章では Transformer の内部を少し深く見ます。LLM の挙動をデバッグし、context length、attention、KV cache、モデル変種がなぜ重要かを理解します。
まず内部フローを見る
Section titled “まず内部フローを見る”

2枚目の図はデバッグ経路として読みます。情報の流れ、計算コスト、タスク適合を一緒に確認します。
causal mask を作る
Section titled “causal mask を作る”seq_len = 4mask = []for query_pos in range(seq_len): row = [] for key_pos in range(seq_len): row.append("allow" if key_pos <= query_pos else "block") mask.append(row)
for row in mask: print(row)期待される出力:
['allow', 'block', 'block', 'block']['allow', 'allow', 'block', 'block']['allow', 'allow', 'allow', 'block']['allow', 'allow', 'allow', 'allow']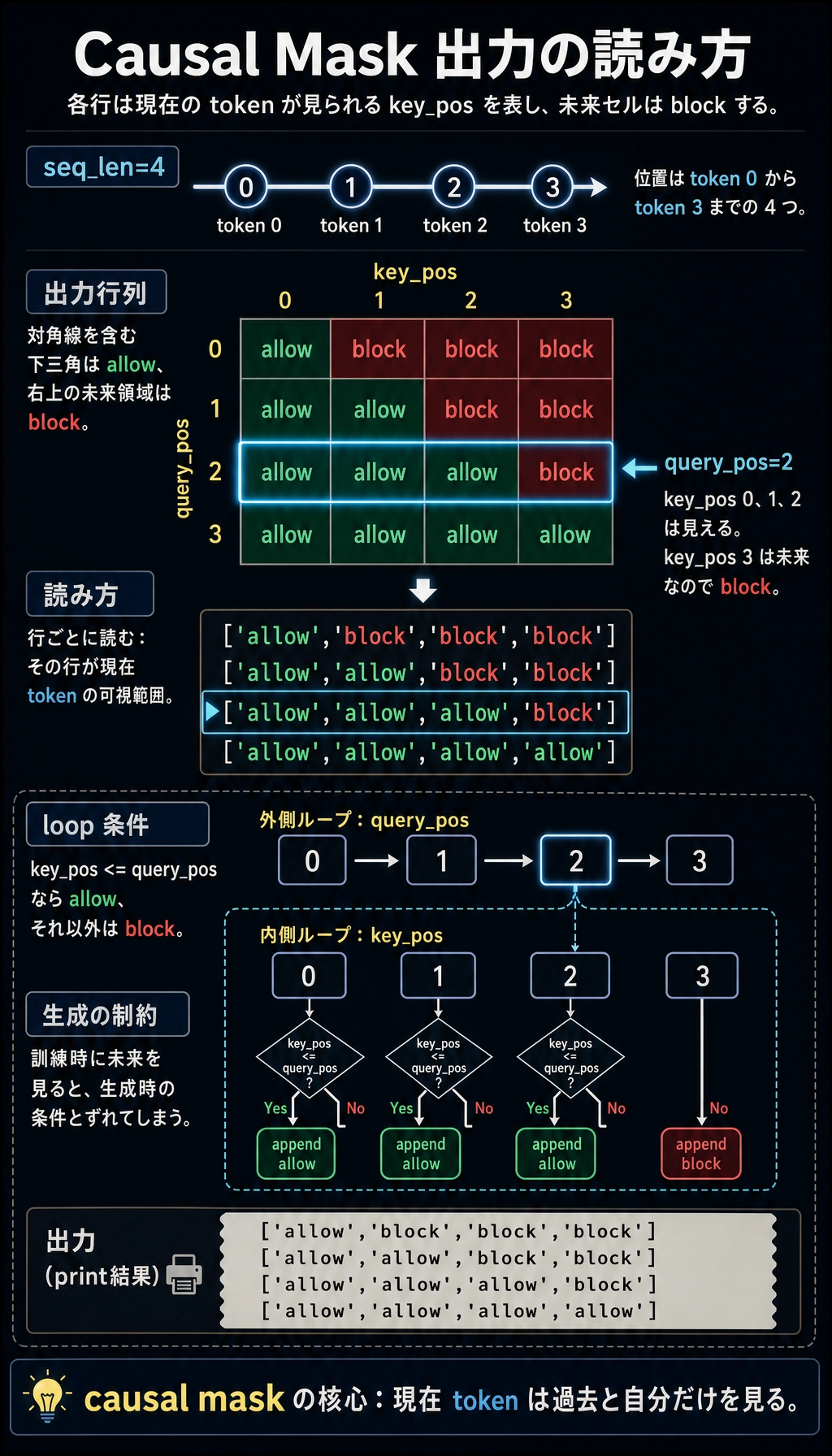
生成ではこの「未来を見ない」ルールを使います。token は前の token を見られますが、未来 token は見られません。
この順番で学ぶ
Section titled “この順番で学ぶ”| 順番 | 読む | まず見ること |
|---|---|---|
| 1 | 7.3.2 アーキテクチャ復習 | attention、残差、正規化 |
| 2 | 7.3.3 現代デコーダーブロック | デコーダーのみの LLM ブロック |
| 3 | 7.3.4 モデル変種 | エンコーダー、デコーダー、エンコーダー-デコーダー |
| 4 | 7.3.5 効率的 Attention | KV cache、MQA/GQA、長い コンテキスト |
| 5 | 7.3.6 スケールと計算 | コスト、遅延、メモリ |
このページを終えたら、この証拠カードを残します。
- ブロック契約
- [batch, seq, d_model] が入力と出力
- マスク確認
- 因果マスクが未来の位置をブロックする
- KVキャッシュの理由
- 推論で過去の key と value を再利用する
- 計算メモ
- アテンションの計算コストは系列長とともに増える
- 橋渡し
- これらの詳細は、アプリ内のレイテンシーとコンテキスト制限を説明します
decoder-only モデルになぜ causal mask が必要か、context が長くなるほど attention が高価になる理由、KV cache が生成を助ける理由を説明できれば合格です。
確認の考え方と解説
- 合格レベルの答えでは、token、context、attention、prompt、生成挙動が1回の request-response path でどうつながるかを説明します。
- 証拠には、再現できる prompt または structured-output test を1つ残し、出力が通った理由または失敗した理由を書きます。
- prompt 設計、RAG、fine-tuning、alignment を切り分け、観察した問題を直す最も軽い方法を選べれば十分です。