9.4.4 長期記憶
- 長期記憶と短期記憶の役割の境界を理解する
- ユーザーの好み、安定した背景、一時的な事実の3種類を区別できるようになる
- 長期記憶の書き込み、更新、衝突処理、読み出しの基本戦略を理解する
- 実行可能なサンプルを通して、最小限の長期記憶ストアの使い方を身につける
まず地図を作ろう
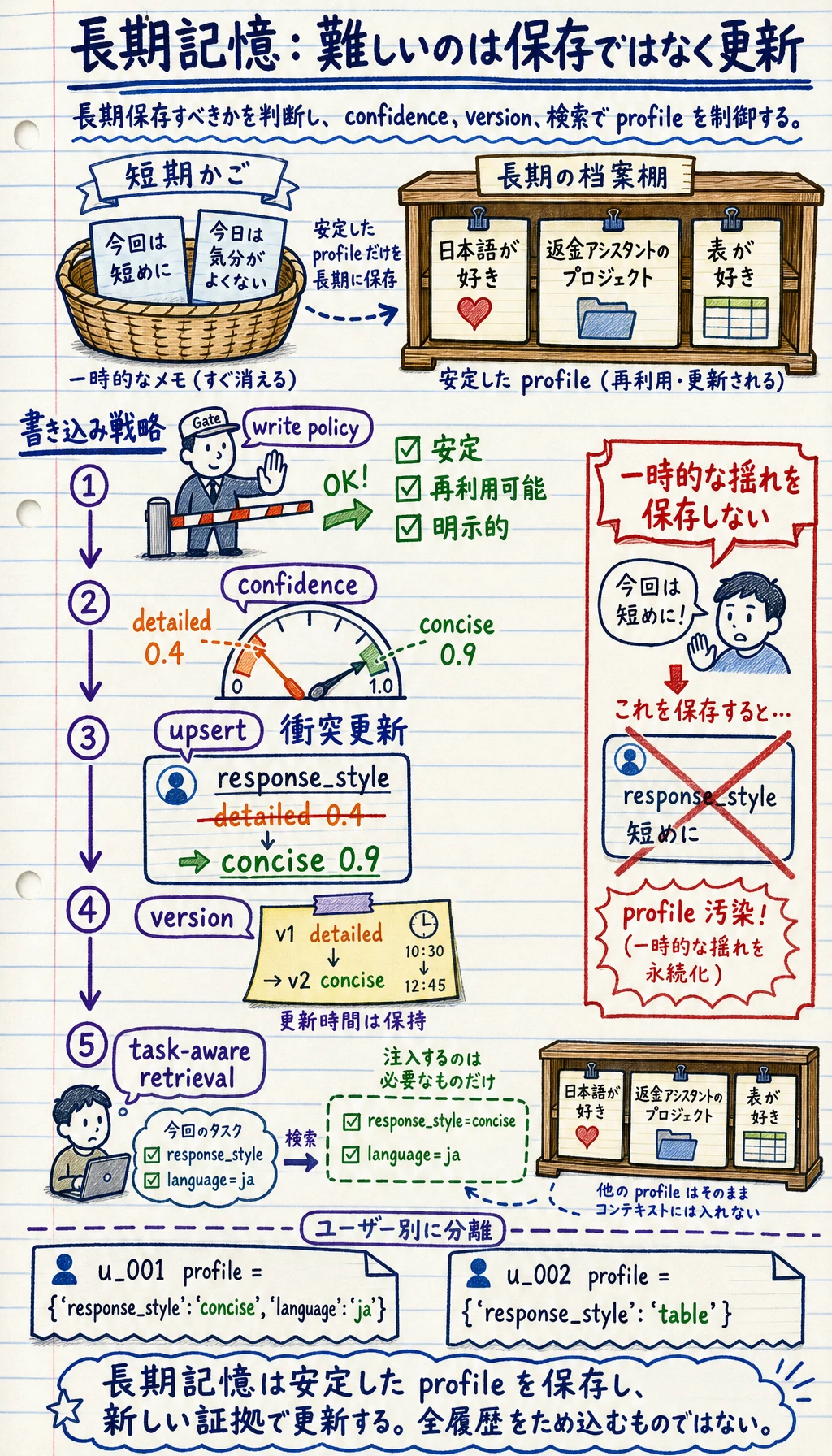
Section titled “まず地図を作ろう”長期記憶は、「何を保存するか -> どう更新するか -> どう取り出すか」という流れで考えると理解しやすいです。
flowchart LR A["ユーザーとプロジェクトの情報"] --> B["長期保存に値するかを判断"] B --> C["長期記憶に書き込む"] C --> D["衝突の更新とバージョン選択"] D --> E["現在のタスクに関連する情報を検索"]この節で本当に知りたいのは、次の2点です:
- 長期記憶はなぜ「少し多めに保存する」だけではないのか
- なぜ書き込み戦略と読み出し戦略の両方が重要なのか
どんな情報が長期記憶に向いているのか?
Section titled “どんな情報が長期記憶に向いているのか?”将来また使う可能性が高い
Section titled “将来また使う可能性が高い”長期記憶で最も大事なのは「見た目が重要そうか」ではなく、
次の点です:
- 将来、再利用する価値があるか
たとえば:
- ユーザーの好み:簡潔な回答が好き
- ユーザーの背景:初学者である
- プロジェクトの背景:現在は返金アシスタントを作っている
こうした情報は、何度も会話をまたいで役立つ可能性があります。
一時的な変化ではなく、比較的安定している
Section titled “一時的な変化ではなく、比較的安定している”たとえば:
- 「今日は気分がよくない」
これは短期的な文脈に近い - 「長期的には表でまとめるのが好き」
これは長期的な特徴に近い
短期的な揺れまで長期記憶に入れてしまうと、
システムはすぐにノイズをたくさん覚えてしまいます。
たとえで考える
Section titled “たとえで考える”長期記憶は「チャット履歴のバックアップ箱」ではなく、
「ユーザープロファイル」や「プロジェクトプロファイル」に近いです。
プロファイルが重視するのは:
- 安定性
- 再利用しやすさ
- バージョン感
初学者によりわかりやすいたとえ
Section titled “初学者によりわかりやすいたとえ”長期記憶は次のように考えるとよいです:
- ユーザーとプロジェクトの「カード」を管理する
そのカードに書くべきなのは:
- 将来も何度も使う情報
逆に、書くべきでないのは:
- 今回の会話でたまたま出た感情の揺れ
- その場で何気なく言った一度きりの要望
このたとえはとても重要です。最初から長期記憶を「無限のチャットログ」にしてしまうのを防げるからです。
長期記憶に入ることが多い3種類の情報
Section titled “長期記憶に入ることが多い3種類の情報”ユーザーの好み
Section titled “ユーザーの好み”たとえば:
- 簡潔なのが好き
- 日本語が好き
- 出力には表をつけたい
安定した背景情報
Section titled “安定した背景情報”たとえば:
- ユーザーの役割は運営担当
- ユーザーは RAG プロジェクトを進めている
- 所属チームでは主に Python を使っている
長期的なタスク背景
Section titled “長期的なタスク背景”たとえば:
- 今週は返金モジュールの改善が重点
- 現在のプロジェクトで何を成功とするか
こうした情報は「直近3件のメッセージ」のように短命ではなく、
また、状況ごとの一回限りの出来事を記録するエピソード記憶とも少し違います。
長期記憶で一番難しいのは「保存」ではなく「更新」
Section titled “長期記憶で一番難しいのは「保存」ではなく「更新」”新しい情報が古い情報を覆すことがあるから
Section titled “新しい情報が古い情報を覆すことがあるから”たとえば、以前の記録にこうあったとします:
- ユーザーは詳しい説明が好き
その後、ユーザーが何度もこう言ったら:
- これからはできるだけ簡潔にしてほしい
このとき、システムは単純に2つを同時に残すだけではいけません。
読み出し時に矛盾してしまうからです。
そのため、長期記憶には通常次のような要素が必要です:
Section titled “そのため、長期記憶には通常次のような要素が必要です:”- タイムスタンプ
- 信頼度
- 更新戦略
よく使われる戦略は次のとおりです:
- 新しい記録で古い記録を上書きする
- 新旧を両方残し、信頼度の高い方を優先する
- 履歴は保持し、読み出し時に最新のものを選ぶ
なぜ「信頼度」が大事なのか?
Section titled “なぜ「信頼度」が大事なのか?”ユーザーの何気ない一言を、ずっと固定して記憶すべきとは限らないからです。
たとえば:
- 「今回は表を使わなくていい」
これは必ずしも次を意味しません:
- 「今後は永遠に表を使わないで」
だから長期記憶にはできれば次の情報を持たせるとよいです:
- 観測回数
- 明確さ
- 信頼度
初学者が最初に覚えるとよい書き込み判断表
Section titled “初学者が最初に覚えるとよい書き込み判断表”| 情報の種類 | 短期向きか長期向きか |
|---|---|
| 今回は少し簡潔にしてほしい | どちらかというと短期 |
| ユーザーは長期的に日本語が好き | どちらかというと長期 |
| 現在のプロジェクトは返金アシスタント | どちらかというと長期的なタスク背景 |
| 今日は気分がよくない | どちらかというと短期 |
この表は初心者にとても役立ちます。
まず次の最も混乱しやすい問いに答えやすくなるからです:
- 何を長期記憶に入れるべきか
まずは最小限の長期記憶ストアを動かしてみよう
Section titled “まずは最小限の長期記憶ストアを動かしてみよう”このサンプルでは次の4つを行います:
- 長期記憶に書き込む
- 既存の記憶を更新する
- 信頼度と時刻で並べて読み出す
- ユーザーごとに記憶を分ける
from dataclasses import dataclass
@dataclassclass LongTermFact: user_id: str key: str value: str confidence: float updated_at: int
class LongTermMemoryStore: def __init__(self): self.items = [] self.clock = 0
def _tick(self): self.clock += 1 return self.clock
def upsert(self, user_id, key, value, confidence=0.6): now = self._tick()
for item in self.items: if item.user_id == user_id and item.key == key: # 新しい値の信頼度が高ければ、古い値を上書きする if confidence >= item.confidence: item.value = value item.confidence = confidence item.updated_at = now return item
fact = LongTermFact( user_id=user_id, key=key, value=value, confidence=confidence, updated_at=now, ) self.items.append(fact) return fact
def get_profile(self, user_id): records = [item for item in self.items if item.user_id == user_id] records.sort(key=lambda x: (x.confidence, x.updated_at), reverse=True) return {item.key: item.value for item in records}
store = LongTermMemoryStore()store.upsert("u_001", "response_style", "detailed", confidence=0.4)store.upsert("u_001", "response_style", "concise", confidence=0.9)store.upsert("u_001", "language", "ja", confidence=0.8)store.upsert("u_002", "response_style", "table", confidence=0.7)
print("u_001 profile:", store.get_profile("u_001"))print("u_002 profile:", store.get_profile("u_002"))期待される出力:
u_001 profile: {'response_style': 'concise', 'language': 'ja'}u_002 profile: {'response_style': 'table'}この例で一番注目すべき点は?
Section titled “この例で一番注目すべき点は?”「保存できるか」ではなく、次の点です:
- 同じ key は更新される
- 信頼度の高い情報が古い値を上書きする
- 読み出しはユーザー単位で profile としてまとめる
これは「文字列をただ list に append する」より、かなり本物の長期記憶に近いです。
なぜここで key-value を使うのが自然なのか?
Section titled “なぜここで key-value を使うのが自然なのか?”長期記憶には、もともと profile 型の情報が多いからです:
response_stylelanguageproject_name
こうした情報は、プレーンテキストの段落よりも、キーと値の形のほうが扱いやすいです。
どんなときにこの形式は向かないのか?
Section titled “どんなときにこの形式は向かないのか?”情報が物語や体験談のような形なら、
そのほうが向いているのは:
- エピソード記憶
であって、単純な key-value ではありません。
さらに最小の「書き込み判断」の例を見る
Section titled “さらに最小の「書き込み判断」の例を見る”facts = [ {"text": "以後はできるだけ日本語で", "stability": "high", "target": "long_term"}, {"text": "今回は少し短めに", "stability": "low", "target": "short_term"},]
for fact in facts: print(fact)期待される出力:
{'text': '以後はできるだけ日本語で', 'stability': 'high', 'target': 'long_term'}{'text': '今回は少し短めに', 'stability': 'low', 'target': 'short_term'}この例はとても小さいですが、初学者がまず次の習慣を身につけるのに役立ちます:
- 記憶に書き込む前に、この情報は長期か短期かを先に考える
長期記憶はどう読み出せば「多すぎて乱れる」ことを防げるのか?
Section titled “長期記憶はどう読み出せば「多すぎて乱れる」ことを防げるのか?”読み出し時に全部をコンテキストへ入れない
Section titled “読み出し時に全部をコンテキストへ入れない”長期記憶にたくさん保存されていても、
現在の質問に全部関係あるとは限りません。
よりよい方法は:
- まずユーザーで絞る
- 次に key やテーマで絞る
- 最後に今いちばん関連する数件だけを取り出す
テーマで絞る最小例
Section titled “テーマで絞る最小例”def select_relevant_profile(profile, query): selected = {} if "回答" in query or "スタイル" in query: if "response_style" in profile: selected["response_style"] = profile["response_style"] if "日本語" in query or "言語" in query: if "language" in profile: selected["language"] = profile["language"] return selected
profile = store.get_profile("u_001")print(select_relevant_profile(profile, "これからは回答スタイルを統一して"))期待される出力:
{'response_style': 'concise'}これは、長期記憶の有効性が
読み出し戦略にも依存することを示しています。
最初に長期記憶システムを作るときの、いちばん堅い順番
Section titled “最初に長期記憶システムを作るときの、いちばん堅い順番”一般に、次の順番が安定です:
- まず最も安定したユーザーの好みだけを保存する
- まずはシンプルな key-value profile にする
- 衝突時の更新ルールをはっきり決める
- そのあとで、より複雑な読み出しや検索戦略を足す
こうすると、最初から「大きくて全部入りの記憶システム」を作るより、ずっと安定します。
もし目標が「知識ベース駆動の SOP 文書アシスタント」なら、どんな情報を長期記憶に入れるべきか?
Section titled “もし目標が「知識ベース駆動の SOP 文書アシスタント」なら、どんな情報を長期記憶に入れるべきか?”このタイプのプロジェクトでよくあるミスは:
- 毎回の SOP テーマをそのまま長期記憶に入れてしまう
でも実際には、多くのテーマは一回限りのタスクであり、
長期保存には向きません。
より長期記憶に向いているのは、次のような安定した好みです:
| 情報 | 長期向きか短期向きか |
|---|---|
| ユーザーが長期的に Word 出力を好む | 長期 |
| ユーザーが長期的に簡潔なチェックリスト形式を好む | 長期 |
| 今回は「返金エスカレーション SOP」を作る | 短期 |
| 今回は対応済みケースが2件だけ必要 | どちらかというと短期 |
| ユーザーが長期的に frontline support 向けに文書を書く | 長期または半長期 |
これを一言でまとめると、次のようになります:
長期記憶には好みと安定した背景を入れ、短期状態には今回のタスクの詳細を入れる。
より実際のプロジェクトらしい長期 profile の例
Section titled “より実際のプロジェクトらしい長期 profile の例”profile = { "preferred_doc_format": "word", "preferred_style": "簡潔なチェックリスト", "preferred_language": "zh/en/ja", "default_audience": "frontline support", "prefer_source_refs": True,}
print(profile)期待される出力:
{'preferred_doc_format': 'word', 'preferred_style': '簡潔なチェックリスト', 'preferred_language': 'zh/en/ja', 'default_audience': 'frontline support', 'prefer_source_refs': True}この例で初学者が特に注目すべきなのは、次の点です:
- 長期記憶は「今回何を書くか」を覚えるためのものではない
- システムが「普段どう書くのが好まれるか」を覚えるためのもの
長期記憶で特にハマりやすい落とし穴
Section titled “長期記憶で特にハマりやすい落とし穴”罠1:一度言ったら永久に保存してしまう
Section titled “罠1:一度言ったら永久に保存してしまう”これだと、たまたまの好みが永遠に固定されてしまいます。
罠2:長期記憶と短期記憶を分けない
Section titled “罠2:長期記憶と短期記憶を分けない”その結果:
- 現在の会話情報と長期プロファイルがごちゃ混ぜになる
システムはどんどん扱いづらくなります。
罠3:書き込みだけして、更新と衝突処理をしない
Section titled “罠3:書き込みだけして、更新と衝突処理をしない”衝突を処理しないと、長期記憶はやがて矛盾だらけになります。
もしこれをプロジェクトやシステム設計として見せるなら、何を強調すべきか
Section titled “もしこれをプロジェクトやシステム設計として見せるなら、何を強調すべきか”本当に見せる価値があるのは、次のような点です:
- 「たくさん過去情報を保存した」こと
- ではなく、
- どの情報が長期記憶に入るのか
- 衝突する情報をどう更新するのか
- 現在のタスクではどの関連プロファイルだけを取り出すのか
- なぜこの戦略でシステムが保存しすぎて乱れないのか
これが伝わると、相手にも次のことが伝わりやすくなります:
- あなたは単なるメッセージ倉庫ではなく、長期プロファイルシステムを理解している
このページを終えたら、この証拠カードを残します。
- メモリ種別
- 短期、長期、エピソード記憶、または手続き記憶
- 書き込みルール
- メモリが作成または更新されるとき
- 取得ルール
- クエリ、関連性、鮮度、権限チェック
- 失敗確認
- 古い記憶、プライバシー漏えい、矛盾、または過剰検索
- クリーンアップ操作
- 要約、統合、期限切れ、削除、または確認を求める
この節で最も大事なのは、長期記憶を「もっと多く保存する仕組み」として理解することではありません。
本質は次のとおりです:
長期記憶とは、時間とともに更新される安定したプロファイルを Agent に作ることであり、履歴メッセージをため込むことではない。
「安定」「再利用可能」「更新可能」という3つのキーワードを押さえておけば、
あとで長期プロファイルシステムを設計するときに、方向を間違えにくくなります。
- サンプルに
sourceフィールドを追加して、「ユーザーが明示した情報」と「システムが推測した情報」を区別し、書き込み戦略で差をつけてみましょう。 今回は少し簡潔にが、なぜそのまま長期的な好みとして保存するのに向かないのか考えてみましょう。- ユーザーの好みが頻繁に変わる場合、上書き、バージョン保持、信頼度の減衰のどれを使いますか? その理由は何ですか?
- 長期記憶と短期記憶をどう組み合わせれば、現在の回答に役立つでしょうか。
参考実装と解説
sourcefield があると、「ユーザーの明示発言」と「システム推論」を分けられます。明示発言はより信頼し、推論された preference は確認してから長期保存します。Keep it concise for this oneは現在タスクだけの指示です。ユーザーが長期的な好みとして明示しない限り、短期記憶に置きます。- 好みがよく変わる場合、単純な overwrite より version retention と confidence decay が安全です。履歴を残し、古い memory の影響を下げられるからです。
- 長期記憶は安定した好みや事実に使い、短期記憶は現在の goal、constraints、recent corrections、retrieved evidence に使います。回答時は両方を組み合わせます。