9.1.6 TD-Gammon から AlphaGo へ:強化学習は Agent にどう影響したのか
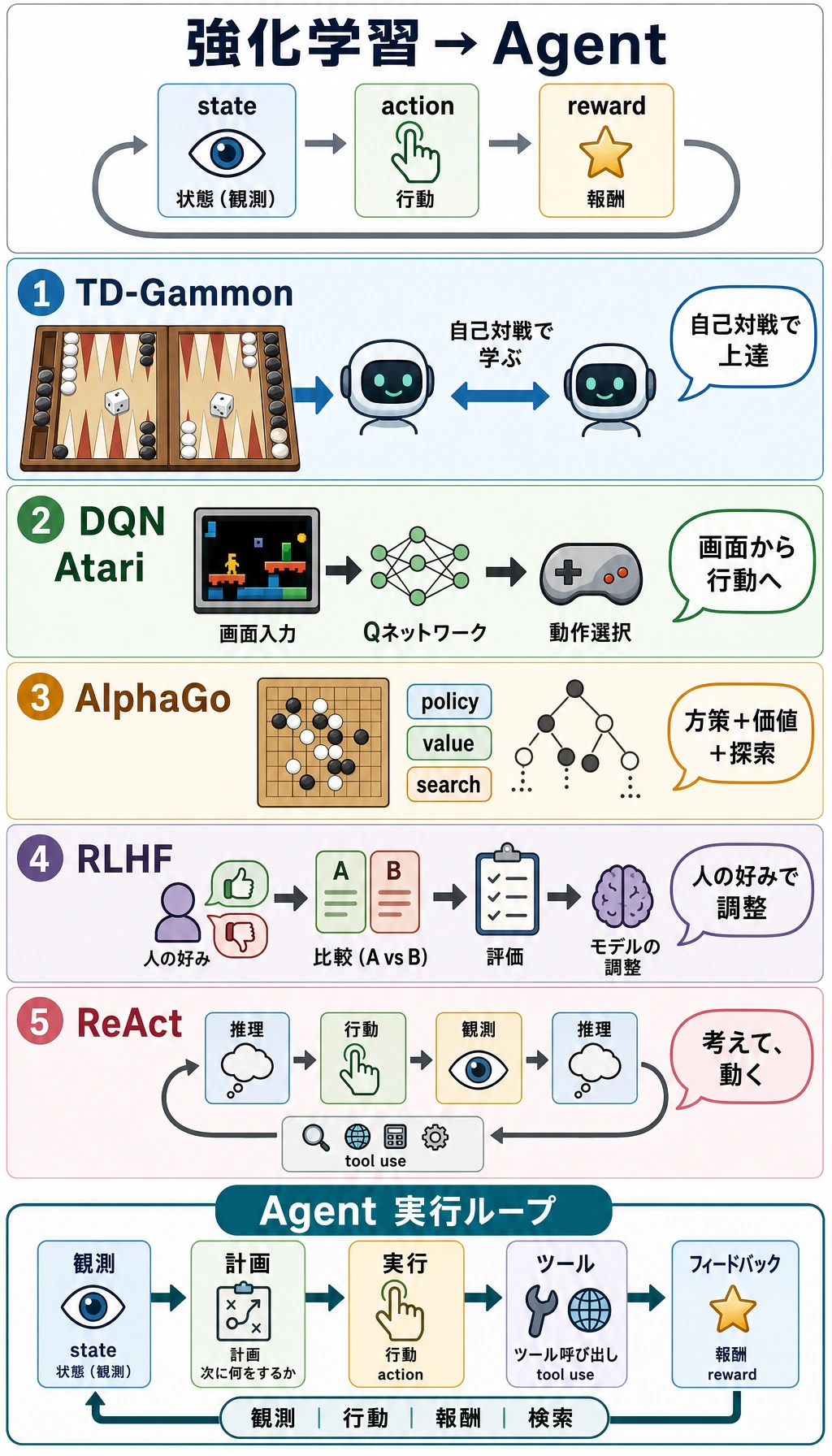
なぜ Agent の講義で強化学習の歴史を学ぶのか?
Section titled “なぜ Agent の講義で強化学習の歴史を学ぶのか?”Agent が気にするのは、次のようなことです。
- 環境の中で状態を観察する
- 次の行動を決める
- フィードバックに応じて方策を調整する
- 長期目標のために計画する
これは、強化学習の基本問題ととてもよく似ています。
| 強化学習の言葉 | Agent システムの言葉 |
|---|---|
| state | 現在のコンテキスト、タスクの状態 |
| action | ツール呼び出し、応答、計画ステップ |
| reward | ユーザーのフィードバック、評価スコア、タスク完了の有無 |
| policy | 意思決定方策、ツールを呼び出すルール |
| environment | 外部システム、知識ベース、ブラウザ、コードリポジトリ |
そのため、強化学習の歴史は脇役ではありません。
Agent がなぜフィードバック、計画、試行錯誤、安全境界を気にするのかを理解する助けになります。
TD-Gammon:自己対戦から方策を学ぶ
Section titled “TD-Gammon:自己対戦から方策を学ぶ”1992 年ごろ、Gerald Tesauro の TD-Gammon は、時系列差分学習を使ってバックギャモンで非常に高い実力を達成しました。
この手法のとても魅力的な点は次の通りです。
システムは人間の棋譜をただ真似するのではなく、大量の自己対戦を通じて、結果のフィードバックから判断を改善していきます。
初心者向けには、次のように考えると分かりやすいです。
| 普通の教師あり学習 | TD-Gammon の特徴 |
|---|---|
| 各ステップに正解がある | 多くの場合、最後の勝敗フィードバックしかない |
| ラベルに当てはめることが中心 | 長期的な方策を学ぶことが中心 |
| データはたいてい人が用意する | システムが自己対戦で経験を生み出せる |
このことは、その後の強化学習やゲーム AI にとって重要な発想を開きました。
システムが自分で経験を作れるなら、人手によるラベル付きデータに完全には縛られない。
DQN Atari:ピクセルから行動へ
Section titled “DQN Atari:ピクセルから行動へ”2015 年、DeepMind の DQN は Atari ゲームでブレークスルーを起こしました。
その重要性は、深層学習と強化学習を組み合わせたことにあります。
- 入力はゲーム画面のピクセル
- 出力は次の行動
- フィードバックはゲームスコア
これは、モデルに「画面を見る」ことからゲームを学ばせるようなものです。
これが現代の Agent に与えた示唆は次の通りです。
- Agent は静的なテキストだけを扱うとは限らない
- Agent は環境の中で連続して行動できる
- 行動はその後の状態を変える
- 評価は毎ステップすぐに出るとは限らない
だからこそ、Agent の評価は普通の質問応答の評価より難しいのです。
AlphaGo:学習・探索・計画をひとつにする
Section titled “AlphaGo:学習・探索・計画をひとつにする”2016 年、AlphaGo が李世乭に勝利したことで、多くの人が AI の飛躍を非常に直感的に感じました。
AlphaGo の重要な点は、「1つのニューラルネットワークがそのまま指す」ことではなく、複数の能力を組み合わせていたことです。
| 能力 | AlphaGo での役割 | Agent への示唆 |
|---|---|---|
| 方策ネットワーク | 次の候補手を判断する | 実行可能な行動を生成する |
| 価値ネットワーク | 局面の良し悪しを見積もる | 現在の計画を評価する |
| モンテカルロ木探索 | 先の展開を何手か読んで結果を見る | 計画と探索を行う |
| 自己対戦 | さらに多くの学習経験を作る | フィードバックから改善する |
Agent にとって、この示唆はとても重要です。
強いシステムは、たいてい1つのモデルだけで強くなるのではなく、モデル・探索・ツール・フィードバック・制約が一緒に動いて強くなります。
この流れは LLM Agent とどう関係するのか?
Section titled “この流れは LLM Agent とどう関係するのか?”現代の LLM Agent の中心は、必ずしも RL アルゴリズムではありません。
しかし、強化学習が扱ってきた多くの問題を受け継いでいます。
| 典型的な RL の問題 | LLM Agent での対応 |
|---|---|
| 報酬をどう定義するか | タスク成功、引用の正しさ、ユーザー満足度をどう測るか |
| 探索が危険ではないか | ツール呼び出しでファイルを誤削除したり、誤送信したりしないか |
| 長期目標をどう分解するか | 複数ステップのタスクをどう計画・実行・修正するか |
| 方策をどう評価するか | Agent ベンチマーク、ログ再生、手動レビュー |
そのため、後で ReAct、Plan-and-Execute、ツール呼び出し、Agent 評価を学ぶときは、次のように考えるとよいです。
これは、言語モデルの時代における「行動・フィードバック・計画」という古くて重要な問題の新しい実装だ。
この歴史の節目を講義の章に対応づける
Section titled “この歴史の節目を講義の章に対応づける”| 歴史的な節目 | 解決した問題 | 対応する講義章 |
|---|---|---|
| TD-Gammon | 自己対戦と長期フィードバックから方策を学ぶ | 9.1 Agent の歴史的背景、9.2 推論と計画 |
| DQN / Atari | 深層ネットワークが環境フィードバックから行動を学ぶ | 9.8 Agent 評価、安全性、環境との相互作用 |
| AlphaGo | 学習・探索・計画を強いシステムとして統合する | 9.2 計画、9.7 マルチ Agent / 複雑システム |
| RLHF | 人間の好みでモデルの振る舞いを調整する | 第7章 アラインメント、9.8 安全性評価 |
| ReAct | 推論と行動を交互に行わせる | 9.2 ReAct、9.3 ツール呼び出し |
この節を学び終えたときに持ってほしい感覚
Section titled “この節を学び終えたときに持ってほしい感覚”Agent は、「モデルを自由に動かす」だけのものではありません。
むしろ、次の要素のあいだで常にバランスを取るシステムに近いです。
- 目標
- 行動
- 環境
- フィードバック
- 計画
- 安全上の制約
TD-Gammon、DQN、AlphaGo の物語が教えてくれるのは、次のことです。
本当に強い知能システムは、ただ質問に答えるだけではなく、環境の中で行動し、そのフィードバックに応じて方策を修正できるのです。
期待される結果:行動、フィードバック、計画、安全上の制約が、TD-Gammon、DQN、AlphaGo と再生可能な LLM Agent 設計をどうつなぐか説明できる状態です。
このページを終えたら、この証拠カードを残します。
- エージェント境界
- これが chatbot や固定ワークフローとどう違うか
- 目標/状態/行動
- 目標、現在の状態、次の行動、観測
- アーキテクチャ要素
- planner、tools、memory、guardrails、evaluator
- 失敗確認
- 自律性が高すぎる、あいまいな目標、状態不足、または trace がない
- 次の行動
- 追跡可能な最小の single-agent ループを構築する
レビュー観点と通過基準
- 合格の目安は、歴史上のシステムを 1 つの Agent design choice に対応づけられることです。self-play は feedback data、DQN は environment actions、AlphaGo は search and planning、RLHF は preference shaping です。
- goal、state、action、observation、evaluator、safety constraint を含む loop を 1 つ書くか描きます。どれかが欠けると、Agent を信頼してレビューできません。
- Agent が誤った action を取った trace を 1 つ残し、原因が goal、state、tool permission、planner、evaluator のどこにあるかを説明します。
- traceable Agent は、instruction が多い chatbot ではなく controlled action system だと説明できれば、このページは完了です。