9.2.3 チェーン推論戦略
- チェーン推論戦略がなぜ複数ステップのタスク性能を高めるのかを理解する
- CoT がどんなタスクに向き、どんなタスクに向かないかを理解する
- 実行できるサンプルを通して、「直接答える」と「段階的に答える」の違いを理解する
- 本番環境で、無制限な長文ではなく構造化された推論をどう使うかを理解する
なぜ「先に手順を考える」と役立つのか?
Section titled “なぜ「先に手順を考える」と役立つのか?”なぜなら、多くの問題は一気にゴールへ飛べないから
Section titled “なぜなら、多くの問題は一気にゴールへ飛べないから”たとえば、この問題です。
- サポートキューには未対応チケットが18件あり、そのうち4件は重複として統合します。そのあと緊急チケットが7件届きます。最終的に何件をトリアージする必要がありますか?
モデルがそのまま答えを生成すると、
とても典型的なミスをしやすくなります。
- 重複チケットを減らすのではなく、新規チケットとして足してしまう
- あとから届いた緊急チケットを忘れる
- 手順の順番を間違える
一方、先に流れを分けると、次のようになります。
18 - 4 = 1414 + 7 = 21
最終的な答えは、たいていより安定します。
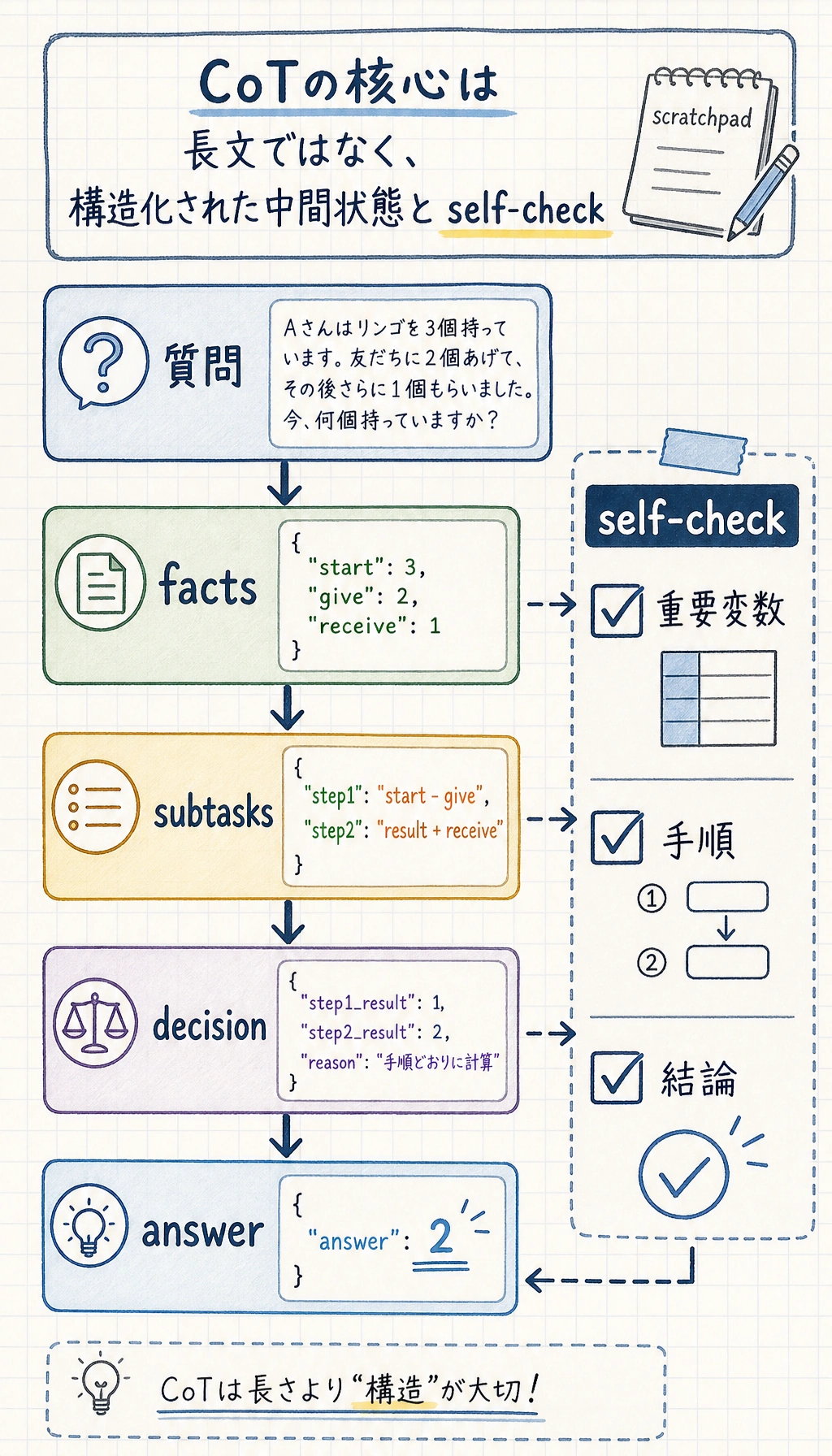
CoT の核心は「たくさん書くこと」ではなく、「中間構造を見えるようにすること」
Section titled “CoT の核心は「たくさん書くこと」ではなく、「中間構造を見えるようにすること」”これはとても重要です。
チェーン推論で本当に役立つのは、次のようなことではありません。
- 出力を長くすること
本当に重要なのは、次の内容を明示することです。
- 局所的な事実
- 中間変数
- 手順の依存関係
たとえ話:下書きメモは、真面目さを見せるためではない
Section titled “たとえ話:下書きメモは、真面目さを見せるためではない”運用チームが複雑なケースを確認するときに下書きメモを使うのは、答えを長く見せるためではありません。 むしろ、次のためです。
- 頭の中の状態が抜け落ちるのを防ぐ
- 複雑な問題を小さく分ける
- 後で見直しやすくする
CoT がモデルに対して果たす役割は、これにとてもよく似ています。
まず「直接答える」方法と「チェーン推論」の比較を見てみよう
Section titled “まず「直接答える」方法と「チェーン推論」の比較を見てみよう”次の例では LLM は呼び出しません。
でも、次のことをとてもはっきり示せます。
- なぜ「雑に直接対応させる」だけだとミスしやすいのか
- なぜ「先に手順を分けてから計算する」と安定しやすいのか
import re
problem = "サポートキューには未対応チケットが18件あり、4件は重複として統合し、そのあと緊急チケットが7件届きます。最終的に何件をトリアージしますか?"
def bad_direct_answer(text): numbers = list(map(int, re.findall(r"\d+", text))) open_tickets, duplicates, urgent = numbers # よくあるミス:重複チケットを減らすのではなく、新規チケットとして足してしまう return open_tickets + duplicates + urgent
def chain_reason_answer(text): open_tickets, duplicates, urgent = map(int, re.findall(r"\d+", text))
steps = [] unique_tickets = open_tickets - duplicates steps.append(f"まず重複チケットを除く:{open_tickets} - {duplicates} = {unique_tickets}")
final_count = unique_tickets + urgent steps.append(f"次に緊急チケットを加える:{unique_tickets} + {urgent} = {final_count}")
return final_count, steps
print("problem:", problem)print("bad direct answer:", bad_direct_answer(problem))
answer, steps = chain_reason_answer(problem)print("\nchain reasoning steps:")for step in steps: print("-", step)print("final answer:", answer)期待される出力:
problem: サポートキューには未対応チケットが18件あり、4件は重複として統合し、そのあと緊急チケットが7件届きます。最終的に何件をトリアージしますか?bad direct answer: 29
chain reasoning steps:- まず重複チケットを除く:18 - 4 = 14- 次に緊急チケットを加える:14 + 7 = 21final answer: 21このコードがいちばんよく示していることは?
Section titled “このコードがいちばんよく示していることは?”次のことです。
- 直接対応させるだけだと、問題文の意味を誤解しやすい
- 手順を明示的に分けると、ミスが見えやすくなる
たとえばここでは、
- 「4件の重複」は
+4なのか、それとも-4なのか
この1点をきちんと書くだけで、
間違いは隠れにくくなります。
なぜ CoT は数学、論理、計画系タスクで特に有効なことが多いのか?
Section titled “なぜ CoT は数学、論理、計画系タスクで特に有効なことが多いのか?”これらのタスクには、たいてい次の特徴があります。
- 中間変数がはっきりしている
- 手順の順序がはっきりしている
- 局所的な依存関係がはっきりしている
これはチェーン推論と自然に合っています。
なぜ CoT は、すべてのタスクで使うべきとは限らないのか?
Section titled “なぜ CoT は、すべてのタスクで使うべきとは限らないのか?”すべての問題に段階分けが必要なわけではないからです。
たとえば、
- 「フランスの首都はどこですか?」
このような問題は、どちらかというと検索に近く、長い推論は必要ありません。
つまり CoT は、常に多ければよいわけではありません。
むしろ、
- 複数ステップの問題でこそ価値が高い
のです。
Agent では CoT を通常どう使うのか?
Section titled “Agent では CoT を通常どう使うのか?”まず分解してから、ツールを呼ぶ
Section titled “まず分解してから、ツールを呼ぶ”多くの Agent タスクでは、CoT は必ずしもそのまま計算に使うわけではありません。
代わりに、次の判断に使われます。
- まず何をするか
- 次に何をするか
- どのステップでツールが必要か
たとえば、次のような流れです。
- 問題の種類を識別する
- 先にポリシーを調べるか、在庫を調べるかを決める
- 取得した観測結果をもとに結論をまとめる
より構造化された「推論スロット」にすることもできる
Section titled “より構造化された「推論スロット」にすることもできる”本番環境では、モデルに大きな自然言語の思考過程を出力させる必要は必ずしもありません。
多くのシステムでは、代わりに次のような短くて構造化された形式にします。
factssubtasksdecisionnext_action
このような構造は、たいてい次の点で扱いやすくなります。
- 検証しやすい
- 記録しやすい
- デバッグしやすい
CoT は自己チェックと組み合わせることも多い
Section titled “CoT は自己チェックと組み合わせることも多い”とてもよくある強化方法は、次の流れです。
- まず推論する
- 次に重要な手順をチェックする
- 最後に答えを出す
こうすると、うっかりミスを一部減らせます。
どんなときに CoT が最も役立つのか?
Section titled “どんなときに CoT が最も役立つのか?”手順分解が必要な問題
Section titled “手順分解が必要な問題”たとえば、次のようなものです。
- 複数ステップの計算
- 条件による選別
- 組み合わせた意思決定
- 複雑なルール判定
途中の理由を説明したい問題
Section titled “途中の理由を説明したい問題”たとえば、次のようなものです。
- なぜこの案をおすすめするのか
- なぜこの依頼は実行できないのか
- なぜこの答えがルールに合っているのか
システムが結論だけでなく理由も示す必要があるとき、
明示的な中間過程はとても価値があります。
間違いのコストが高い問題
Section titled “間違いのコストが高い問題”もし、1回でも計算ミスや判断ミスをすると、
影響が大きいなら、
明示的な手順を入れる価値は高くなります。
どんなときに CoT はかえって足を引っ張るのか?
Section titled “どんなときに CoT はかえって足を引っ張るのか?”簡単な検索問題
Section titled “簡単な検索問題”問題自体が段階分けを必要としないなら、
無理に長い過程を出させても、たいてい次のようになるだけです。
- 遅くなる
- 長くなる
- コストが上がる
推論チェーンが長すぎると、自分で自分を迷わせることがある
Section titled “推論チェーンが長すぎると、自分で自分を迷わせることがある”チェーンが長くなると、モデルは次のような状態になりえます。
- 先頭の手順は正しいのに、後半でずれる
- 同じ説明を繰り返す
- 中間状態の前後が一致しなくなる
つまり、CoT は無限に長くすればよいわけではありません。
外部公開のときは、そのまま見せるのが適切でない場合がある
Section titled “外部公開のときは、そのまま見せるのが適切でない場合がある”多くの製品では、次のやり方のほうが適切です。
- 内部では推論構造を持つ
- ユーザーには要点だけを見せる
なぜなら、ユーザーが本当に必要なのはたいてい次のものだからです。
- わかりやすい結論
- 必要最小限の理由
長い下書きそのものではありません。
より実用的な構造化 CoT の書き方
Section titled “より実用的な構造化 CoT の書き方”次の例は、Agent により向いた書き方を示しています。
- 大きな自由文を出力しない
- 固定されたスロットに分ける
ticket = { "question": "返金キューには未対応チケットが18件あり、4件は重複として統合し、そのあと緊急チケットが7件届きます。最終的に何件をトリアージしますか?", "policy": "重複したサポートチケットは、トリアージ前に統合します。",}
def structured_reasoning(ticket): facts = [ "重複したサポートチケットは、トリアージ前に統合する", "キューは18件から始まり、4件の重複を除き、そのあと7件の緊急チケットを受け取る", ] calculation = ["18 - 4 = 14", "14 + 7 = 21"] decision = "チームは21件のチケットをトリアージする必要がある。"
return { "facts": facts, "calculation": calculation, "decision": decision, }
result = structured_reasoning(ticket)print(result)期待される出力:
{'facts': ['重複したサポートチケットは、トリアージ前に統合する', 'キューは18件から始まり、4件の重複を除き、そのあと7件の緊急チケットを受け取る'], 'calculation': ['18 - 4 = 14', '14 + 7 = 21'], 'decision': 'チームは21件のチケットをトリアージする必要がある。'}この形式の利点は次の通りです。
- 読みやすい
- テストしやすい
- 後処理しやすい
このページを終えたら、この証拠カードを残します。
- タスク目標
- Agent が解決しようとしていること
- 計画またはトレース
- 推論手順、計画、ReAct trace、または実行グラフ
- 観察
- 各アクションの後に何が変わったか
- 失敗確認
- 幻覚のステップ、古い観測、ループ、または未検証の結論
- 評価アクション
- 期待結果と比較して計画を修正する
よくある誤解
Section titled “よくある誤解”誤解その1:CoT は、モデルを少しおしゃべりにすること
Section titled “誤解その1:CoT は、モデルを少しおしゃべりにすること”違います。
核心は、
- 中間構造を明示すること
です。
誤解その2:すべてのタスクでデフォルト CoT にすべき
Section titled “誤解その2:すべてのタスクでデフォルト CoT にすべき”違います。
有効かどうかは、その問題が本当に複数ステップかどうかで決まります。
誤解その3:CoT があれば、答えは必ず正確になる
Section titled “誤解その3:CoT があれば、答えは必ず正確になる”これも違います。
チェーン推論は安定性を高めますが、
すべての誤りを自動で消してくれるわけではありません。
この節でいちばん大事なのは、Chain-of-Thought という英語名を覚えることではありません。
むしろ、実用的な判断基準を身につけることです。
問題が複数ステップの中間状態に依存するなら、モデルにまず手順を明示的に分解させると、安定性が上がることが多い。ただし CoT の価値は構造化された中間過程にあり、出力を無限に長くすることではない。
この理解ができていれば、
この先に出てくる次の内容も理解しやすくなります。
- ReAct
- Plan-and-Execute
- 自己チェックと評価
これらはすべて、CoT の上にさらに組織化を重ねたものだとわかるはずです。
- 例のチケットキュー問題を、自分の多段階の運用問題に置き換えて、
bad_direct_answerとchain_reason_answerを比べてみましょう。 - なぜ CoT の核心は「出力を長くすること」ではなく「中間構造を明示すること」だと言えるのでしょうか?
- CoT に向かない簡単な問題を 1 つ考えて、理由を説明してみましょう。
- CoT を製品に使うなら、自由文と構造化スロットのどちらを選びますか? その理由は何ですか?
参考実装と解説
- chain 版は途中の小さな結果を見せるべきです。一方、bad direct 版は仮定や計算ミスを最終回答の中に隠してしまいがちです。
- CoT が価値を持つのは、追跡すべき依存関係があるタスクです。構造のない長文は、単に冗長な出力です。
- 「日本の首都はどこですか?」のような単純な検索問題には CoT は不要です。中間推論はノイズとコストを増やすだけになりやすいからです。
- 製品では構造化スロットを選ぶことが多いです。検証、ログ化、評価がしやすく、必要に応じてユーザーに見せない設計もしやすいからです。