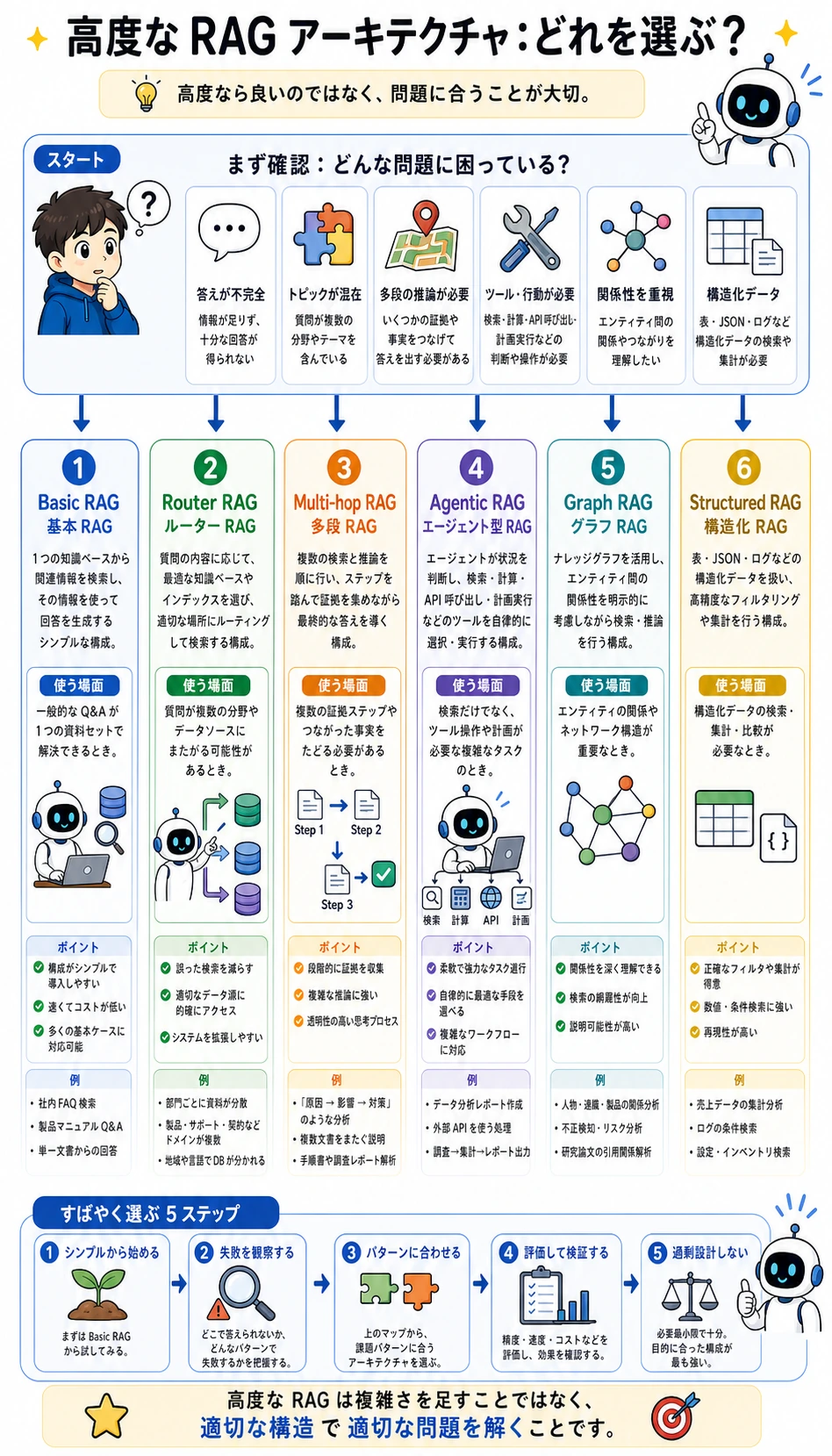
8.1.7 高度な RAG アーキテクチャ
この節が終わると、あなたは次のことができるようになります。
- 基本の RAG が複雑な場面でなぜ足りなくなるのかを理解する
- ルーティング型、多段型、Agentic RAG などのよくあるアーキテクチャを知る
- 「複数ナレッジベースのルーティング」のおもちゃ例を動かす
- いつ RAG アーキテクチャをアップグレードすべきか、いつすべきでないかを判断する
一、なぜ基本の RAG にはいずれ限界が来るのか?
Section titled “一、なぜ基本の RAG にはいずれ限界が来るのか?”基本の RAG は「1回の質問 -> 1回の検索 -> 1回の回答」に向いている
Section titled “基本の RAG は「1回の質問 -> 1回の検索 -> 1回の回答」に向いている”これは多くの FAQ や簡単な QA には十分です。
しかし、問題が複雑になるとボトルネックが出てきます。
たとえば:
- 複数のナレッジベースをまたぐ必要がある
- まず規約を確認してから、具体的な製品ドキュメントを調べる必要がある
- 複数のサブ問題に分解する必要がある
よくある複雑な場面
Section titled “よくある複雑な場面”たとえば、ユーザーがこう聞いたとします。
「この受講者は返金できますか? できないなら、延長の方法はありますか?」
これは実際には、複数の行動を含んでいます。
- 返金ポリシーを確認する
- 現在の条件が満たされているか判断する
- さらに延長方法を確認する
このとき、「1回だけ検索する」では足りないことが多いです。
この図のポイントはとてもシンプルです。いきなり一番複雑な構成にするのではなく、本当に失敗している部分を最小の構成で直すことです。
二、ルーティング型 RAG:まず、どこを調べるかを決める
Section titled “二、ルーティング型 RAG:まず、どこを調べるかを決める”1つのナレッジベースで足りないなら、まずルーティングする
Section titled “1つのナレッジベースで足りないなら、まずルーティングする”多くのシステムには、1つの文書庫だけでなく、次のようなものがあります。
- ポリシー庫
- 製品庫
- 技術ドキュメント庫
- FAQ 庫
すべての問い合わせを同じ庫に入れると、ノイズが大きくなります。
このとき、よりよい方法は次のとおりです。
まず問題がどの庫に属するかを判断してから、検索する。
複数の庫を使う、実行可能なルーティング例
Section titled “複数の庫を使う、実行可能なルーティング例”policy_docs = [ "返金ポリシー:コース購入後 7 日以内なら返金申請できます。", "証明書ポリシー:テスト合格後に証明書を取得できます。"]
tech_docs = [ "ログイン失敗時は、まずアカウントとパスワード、ネットワーク接続を確認してください。", "API 呼び出しで 401 エラーが出る場合は、通常、認証失敗を意味します。"]
def route_query(query): query_lower = query.lower() if "返金" in query_lower or "証明書" in query_lower: return "policy" if "ログイン" in query_lower or "api" in query_lower or "401" in query_lower: return "tech" return "default"
def retrieve_simple(query, docs): query_lower = query.lower() keywords = []
if "返金" in query_lower: keywords.extend(["返金", "返金ポリシー"]) if "証明書" in query_lower: keywords.extend(["証明書", "証明書ポリシー"]) if "ログイン" in query_lower or "401" in query_lower or "api" in query_lower: keywords.extend(["ログイン", "401", "api"]) if not keywords: keywords = query_lower.split()
return [doc for doc in docs if any(keyword in doc.lower() for keyword in keywords)]
queries = ["どうやって返金しますか", "401 エラーはどう対処しますか"]
for q in queries: route = route_query(q) if route == "policy": hits = retrieve_simple(q, policy_docs) elif route == "tech": hits = retrieve_simple(q, tech_docs) else: hits = [] print(q, "-> ルーティング先", route, "->", hits)期待される出力:
どうやって返金しますか -> ルーティング先 policy -> ['返金ポリシー:コース購入後 7 日以内なら返金申請できます。']401 エラーはどう対処しますか -> ルーティング先 tech -> ['API 呼び出しで 401 エラーが出る場合は、通常、認証失敗を意味します。']これは、最もシンプルな「Router RAG」です。 Router RAG は、それだけで検索が賢くなる魔法ではありません。先に検索範囲を狭め、retriever が余計な資料と戦わなくてよい状態を作るのが価値です。
三、多段 RAG:問題を複数のステップに分ける
Section titled “三、多段 RAG:問題を複数のステップに分ける”1回で答えきれない問題もある
Section titled “1回で答えきれない問題もある”たとえば、次のような質問です。
「この人はどんな条件を満たしていて、証明書取得まであと何が必要ですか?」
この種の問題では、たいてい次のことが必要です。
- 証明書のルールを確認する
- ユーザーの達成状況を確認する
- その後で比較する
多段 RAG は「問題を解く」感覚に近い
Section titled “多段 RAG は「問題を解く」感覚に近い”資料を一気に全部探すのではなく、
- まず最初のサブ問題を解く
- その中間結果を使って、さらに検索する
という流れです。
これは Agent の考え方にかなり近いです。
四、エージェント型 RAG(Agentic RAG):検索を固定の流れにしない
Section titled “四、エージェント型 RAG(Agentic RAG):検索を固定の流れにしない”普通の RAG と何が違うのか?
Section titled “普通の RAG と何が違うのか?”普通の RAG は、固定された流れに近いです。
- 検索する
- コンテキストを組み立てる
- 回答する
それに対して、Agentic RAG は次のように動くことがあります。
- 検索が必要か判断する
- 何回検索するか決める
- クエリを書き換えるか、データソースを切り替えるか決める
- さらに行動を続けるか判断する
メリットとコスト
Section titled “メリットとコスト”メリット:
- より柔軟
- 複雑なタスクを扱いやすい
コスト:
- デバッグが難しい
- 遅くなりやすい
- コストが高い
なので、すべての RAG を Agent 化すべきではありません。
五、構造化検索:すべての知識をプレーンテキストに入れるべきではない
Section titled “五、構造化検索:すべての知識をプレーンテキストに入れるべきではない”データ自体に構造があるとき
Section titled “データ自体に構造があるとき”たとえば:
- 注文テーブル
- ユーザー状態
- チケットシステム
- 成績表
このようなデータは、多くの場合、次の方法のほうが向いています。
- SQL クエリ
- API クエリ
- グラフデータベース
むりにプレーンテキストへ変換してから検索するより適しています。
よくあるアップグレードの考え方
Section titled “よくあるアップグレードの考え方”実際のシステムでは、次のものを組み合わせることがよくあります。
- 非構造化文書の RAG
- 構造化データベース検索
- ツール呼び出し
これが、「高度な RAG」が Agent と結びつきやすい理由です。
六、グラフ RAG(Graph RAG)とナレッジグラフ的な考え方
Section titled “六、グラフ RAG(Graph RAG)とナレッジグラフ的な考え方”何を解決するのか?
Section titled “何を解決するのか?”知識同士に明確な関係があるとき、純テキストのチャンク分割だけでは不十分なことがあります。
たとえば:
- 人物関係
- 会社の組織構造
- 製品の依存関係
このとき、グラフ構造のほうが「ノード同士のつながり」を表しやすいです。
どんなときに検討する価値があるか?
Section titled “どんなときに検討する価値があるか?”次のような質問が多いなら、グラフ型の検索を検討できます。
- 複数のエンティティをまたいで移動する
- 関係の連鎖をたどる
- 構造化された推論をする
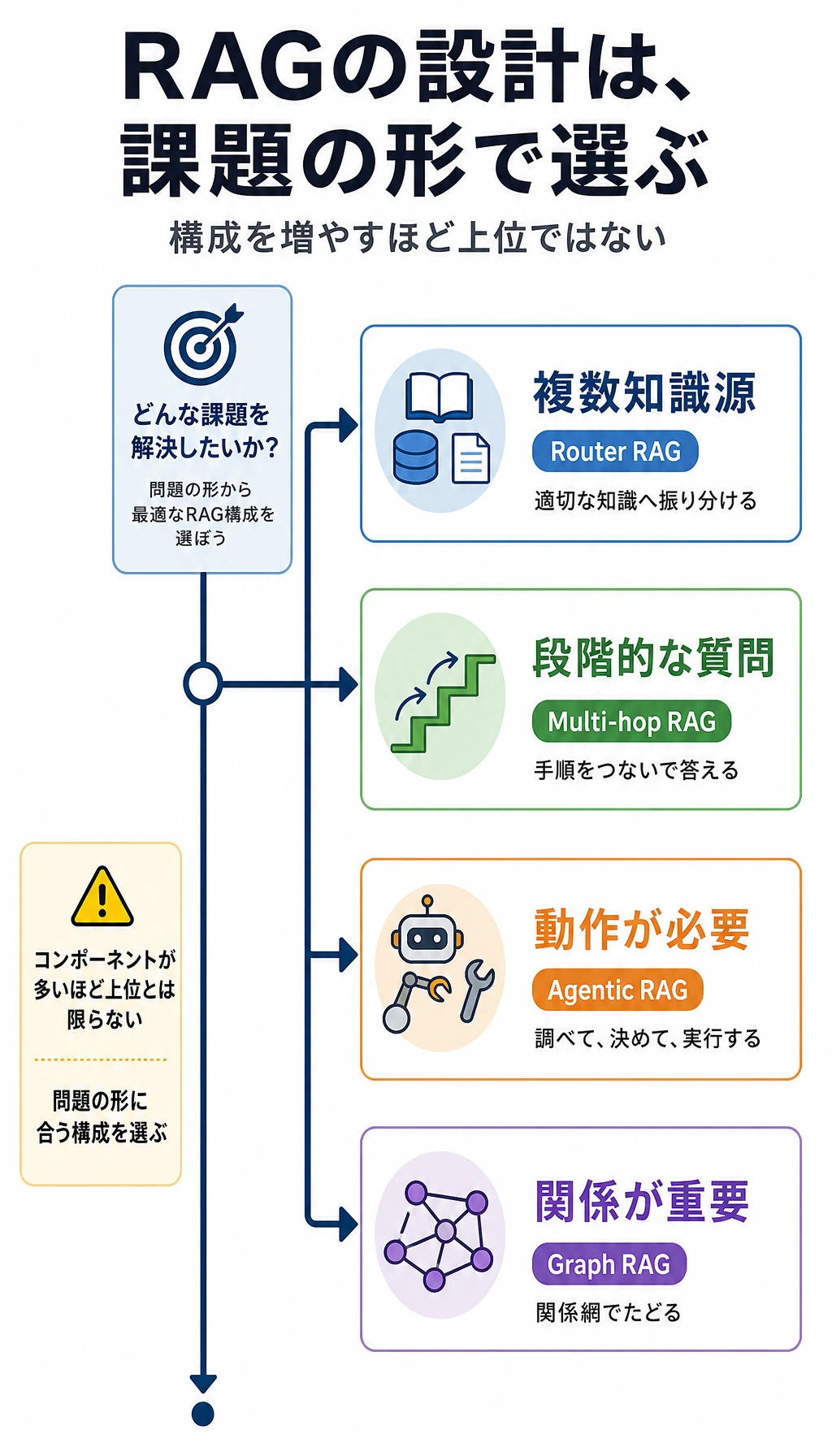
七、いつ高度な RAG にアップグレードすべきか?
Section titled “七、いつ高度な RAG にアップグレードすべきか?”アップグレードする価値があるサイン
Section titled “アップグレードする価値があるサイン”すでに次のような問題にぶつかっているなら、アーキテクチャのアップグレードを考えてよいです。
- 複数のナレッジベースが互いに干渉している
- 1回の検索では足りないことが多い
- 構造化データとの連携が必要
- 問題が明らかに複数ステップに分かれている
まだアップグレードしないほうがよいサイン
Section titled “まだアップグレードしないほうがよいサイン”もし今、基本の RAG すらまだ安定していないなら、
- chunk が適切でない
- 評価セットがない
- top-k の調整もしていない
この状態で、急いで高度なアーキテクチャに進む必要はありません。
八、初心者がよくやる誤解
Section titled “八、初心者がよくやる誤解”複雑なタスクを見るとすぐエージェント型 RAG(Agentic RAG)にしたくなる
Section titled “複雑なタスクを見るとすぐエージェント型 RAG(Agentic RAG)にしたくなる”多くの場合、まずルーティングと検索戦略を整えるだけで、大半の問題は解決できます。
「高度」を「コンポーネントが多いほど高度」と考える
Section titled “「高度」を「コンポーネントが多いほど高度」と考える”コンポーネントが増えても、必ずしもシステムがよくなるわけではありません。
ただ保守が難しくなるだけかもしれません。
評価せずにアーキテクチャをむやみにアップグレードする
Section titled “評価せずにアーキテクチャをむやみにアップグレードする”評価がなければ、アップグレードが本当に改善なのか、それとも「見た目が複雑になっただけ」なのか分かりません。
このページを終えたら、この証拠カードを残します。
- クエリ
- 1つのユーザー質問またはテストケース
- 検索チャンク
- chunk id、スコア、ソースタイトル
- 回答
- 引用または出典メモ付きの最終回答
- 失敗確認
- 証拠不足、誤ったチャンク、古い文書、または裏付けのない主張
- 次の行動
- chunking、embedding、reranking、prompt、または eval の変更
この節で最も大事なのは、次の考え方です。
高度な RAG は見栄えのためではなく、基本の RAG では複雑な問題をカバーできないときに、システムへより賢い検索の組み立て方を追加するためのものです。
まずはシンプルなアーキテクチャをしっかり磨いてから、アップグレードするかどうかを決める。
これが、より成熟したエンジニアリングの進め方です。
- ルーティング例に「コース内容庫」を追加して、
route_query()のルールを拡張してみましょう。 - 自分のプロジェクトでは、実はどのデータがプレーンテキスト検索より SQL / API クエリに向いているか考えてみましょう。
- 多段検索が必須になる質問の例を 1 つ考えてみましょう。
プロジェクト参考とレビュー観点
- よい route は、シラバス、レッスン、練習問題に関する質問をコース内容の knowledge base に送り、account、payment、policy の質問はそれぞれ別 route に残します。Route decision は確認しやすい形にします。
- Order status、enrollment record、inventory、permission、grade、live price などの構造化事実は、SQL や API のほうが向いていることが多いです。Text retrieval は、説明、policy、manual、長文知識に向いています。
- Multi-hop question は複数箇所の証拠を必要とします。たとえば「vector database を教える lesson はどれで、その概念を後で使う project はどれか?」です。片方の retrieval で lesson、もう片方で project connection を探します。