13.5 Open-Weight Model Landscape: gpt-oss、Qwen、DeepSeek、Llama
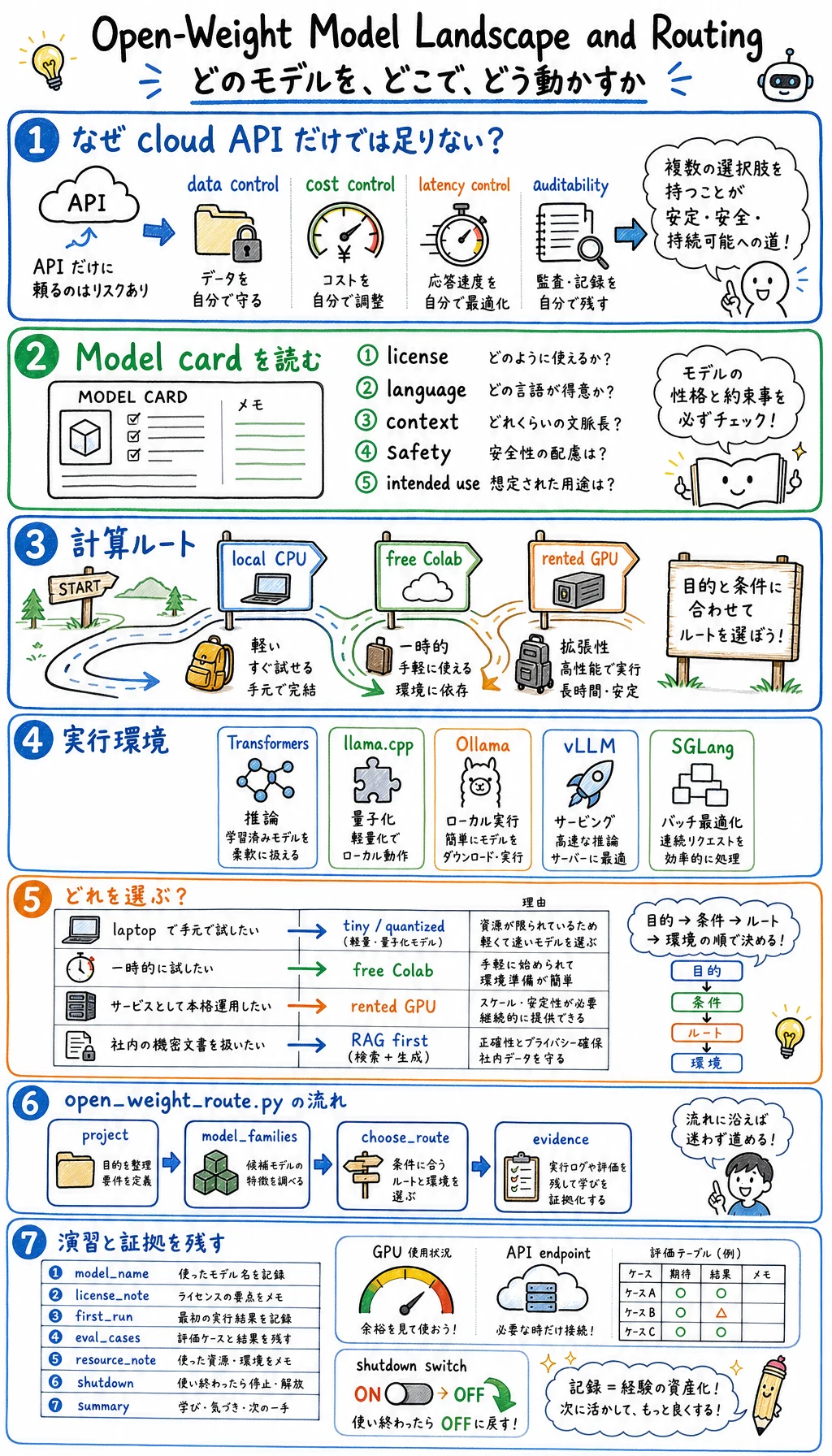
Open-weight models は、AI engineering stack の実用的な部品になっています。OpenAI gpt-oss、Qwen、DeepSeek-style reasoning models、Llama family、Mistral family などにより、privacy、cost、latency、deployment をより細かく制御できます。
このレッスンは、すべてのモデル名を追うためのものではありません。Model card を読み、runtime を選び、小さな proof を実行し、評価し、その後で fine-tuning を決める流れを学びます。
なぜ登場したのか
Section titled “なぜ登場したのか”Cloud API は LLM application を始めやすくしました。Open-weight models が重要になった理由は、チームが次のことを必要とするからです。
-
Data control 一部の入力は private machine や VPC の外に出せません。
-
Cost control 高頻度の inference は、自前または rented hardware の方が安い場合があります。
-
Latency control Local / regional deployment は round trip を減らせます。
-
Customization RAG、decoding settings、adapters、quantization、LoRA を製品に合わせて調整できます。
-
Auditability Model files、revision、runtime settings、evaluation cases を記録できます。
その代わり、downloads、licenses、memory、drivers、serving、evaluation、shutdown などの systems work を自分で持つことになります。
| レイヤー | 質問 | 証拠 |
|---|---|---|
| Model card | この model は何に使えるか、何が許可されるか | License、language、context、safety notes、intended use |
| Runtime | どう実行するか | Transformers、llama.cpp、Ollama、vLLM、SGLang、notebook |
| Compute route | どこで実行するか | Local CPU/GPU、free Colab、rented GPU |
| Evaluation | この task に十分か | Fixed prompts、pass/fail notes、latency、memory |
| Adaptation | tuning すべきか | Prompt/RAG first、失敗 eval があってから LoRA |
| 状況 | 最初の route | 最初の target | 止まるべき証拠 |
|---|---|---|---|
| Laptop のみ、GPU なし | Local CPU quantized model | Tiny instruct model / small quantized model | Prompt、output、time note、memory note |
| 一時実験 | Free Colab if available | Small model and short eval | Notebook link、runtime type、reset note |
| Stable service が必要 | Rented GPU | vLLM/SGLang/OpenAI-compatible API | Endpoint、request/response、cost/hour、stop command |
| Private documents が必要 | Local or private GPU | RAG before tuning | Access rule、source trace、no data-leak note |
| Domain behavior を変えたい | GPU route | LoRA only after eval failures | Before/after eval and adapter artifact |
実行できる演習: Open-Weight Route を選ぶ
Section titled “実行できる演習: Open-Weight Route を選ぶ”open_weight_route.py を作り、Python 3.10 以上で実行します。この script は model を download しません。GPU 費用を使う前に書く decision card を作ります。
import jsonfrom pathlib import Path
project = { "task": "course Q&A assistant", "privacy": "private_docs", "available_route": "rented_gpu", "needs_service_api": True, "needs_fine_tuning": False, "budget_level": "small",}
model_families = [ {"family": "small instruct model", "fit": ["cpu_lab", "colab"], "runtime": "llama.cpp or Transformers"}, {"family": "Qwen or Llama family", "fit": ["colab", "rented_gpu"], "runtime": "Transformers, vLLM, or SGLang"}, {"family": "gpt-oss family", "fit": ["rented_gpu"], "runtime": "check current model card and runtime support"}, {"family": "reasoning model family", "fit": ["rented_gpu"], "runtime": "serve only after latency and cost checks"},]
def choose_route(info): if info["available_route"] == "local_cpu": return {"route": "local_cpu", "goal": "prove the pipeline with a small quantized model"} if info["available_route"] == "free_colab": return {"route": "free_colab", "goal": "run one notebook experiment and save reset notes"} return {"route": "rented_gpu", "goal": "run a stable API with explicit cost and shutdown"}
def choose_family(info, families): route = choose_route(info)["route"] for item in families: if route in item["fit"]: if info["needs_service_api"] and "vLLM" not in item["runtime"] and route == "rented_gpu": continue return item return families[0]
decision = { "project": project["task"], "route": choose_route(project), "model_family": choose_family(project, model_families), "adaptation": "RAG first; LoRA only after fixed eval failures" if not project["needs_fine_tuning"] else "prepare LoRA after baseline eval", "evidence": [ "model card and license note", "runtime command", "first prompt and output", "five-case eval table", "latency and memory note", "shutdown command", ],}
Path("open_weight_route.json").write_text(json.dumps(decision, indent=2), encoding="utf-8")print(json.dumps(decision, indent=2))期待される出力:
{ "project": "course Q&A assistant", "route": { "route": "rented_gpu", "goal": "run a stable API with explicit cost and shutdown" }, "model_family": { "family": "Qwen or Llama family", "fit": [ "colab", "rented_gpu" ], "runtime": "Transformers, vLLM, or SGLang" }, "adaptation": "RAG first; LoRA only after fixed eval failures", "evidence": [ "model card and license note", "runtime command", "first prompt and output", "five-case eval table", "latency and memory note", "shutdown command" ]}コードを一行ずつ読む
Section titled “コードを一行ずつ読む”project は constraint card です。Route、privacy、API need、tuning need を変えてから model を選びます。
model_families は benchmark table ではありません。Planning table です。Download / serve の前に必ず現在の official model card を確認します。
choose_route() は local CPU、free Colab、rented GPU を分けます。それぞれ proof target が違います。
choose_family() は人気だけで model family を選ばないための関数です。Route と runtime に合うかを見ます。
decision["evidence"] は最小 run packet です。これがないまま fine-tuning しません。
Script を3回実行します。
| Run | Change | 何が起きるべきか |
|---|---|---|
| Local CPU | available_route="local_cpu", needs_service_api=False | Goal は serving ではなく pipeline proof になる |
| Free Colab | available_route="free_colab" | Evidence に reset/runtime notes が必要 |
| Rented GPU | available_route="rented_gpu", needs_service_api=True | API、cost、shutdown を含む |
その後、採用しなかった model family を1つと、その理由を書きます。
すべての open-weight experiment は次を保存します。
- Model Name
- 可能なら正確な repository と revision
- License Note
- 許可される用途
- Route
- local CPU, free Colab, rented GPU
- Runtime
- command and version
- First Run
- prompt, output, timestamp
- Eval
- at least five fixed cases
- Resource Note
- memory, latency, disk, cost
- Shutdown
- server または rented instance の停止方法
- Decision
- keep, switch, RAG, LoRA, stop
Open-weight models は制御を増やしますが、engineering responsibility も増えます。小さな proof から始め、証拠を保存し、tuning 前に評価し、GPU rental を shortcut ではなく reproducible experiment として扱います。
理解チェック
Local CPU、free Colab、rented GPU のどれを使うかを選び、必要な model-card evidence を言え、小さな proof を計画または実行し、fine-tuning は baseline eval が失敗してからにすべき理由を説明できれば合格です。