7.6.3 LoRA と QLoRA
- LoRA の低ランク増分の直感を理解する
- QLoRA が LoRA の上でさらに何をしているかを理解する
- 最小限の行列増分のイメージをつかむ
- いつ LoRA を考え、いつ QLoRA を考えるべきかの実用的な判断軸を作る
まずは全体像をつかもう
Section titled “まずは全体像をつかもう”LoRA / QLoRA を初心者が理解する順番として最適なのは、「先に略語を覚える」ことではなく、まず次をはっきり見ることです。
flowchart LR A["モデル全体はあまり変えたくない"] --> B["LoRA:小さな増分だけ学習する"] B --> C["ベースモデル自体はまだ大きい"] C --> D["QLoRA:ベースモデルをさらに量子化する"]この節で本当に解決したいのは、次の2つです。
- LoRA は何を節約しているのか
- QLoRA は LoRA に加えて何をさらに解決しているのか
初心者向けの、よりわかりやすい比喩
Section titled “初心者向けの、よりわかりやすい比喩”LoRA / QLoRA は、次のように考えると理解しやすいです。
- 大きな機械全体を作り直すのではなく、重要な小さな部品だけを交換する
全量ファインチューニングは、より具体的には次のイメージです。
- 機械全体を分解して、全部再調整する
LoRA は次のようなイメージです。
- 学習する小さな改造パーツだけを追加する
QLoRA はそのうえで、さらに次のことをします。
- 先に元の機械をより省スペースにしてから、その改造パーツを付ける
なぜ LoRA はこれほど重要なのか?
Section titled “なぜ LoRA はこれほど重要なのか?”大規模モデルでは、全量ファインチューニングはたいてい高すぎるからです。
- パラメータ数が多すぎる
- GPU メモリの消費が大きすぎる
- 学習コストも保存コストも高い
そこで自然に出てくる疑問はこうです。
モデル全体を変えずに、本当に必要なところだけを少し変えられないのか?
LoRA はまさにこの問いへの答えです。
LoRA のいちばん核心的な直感は何か?
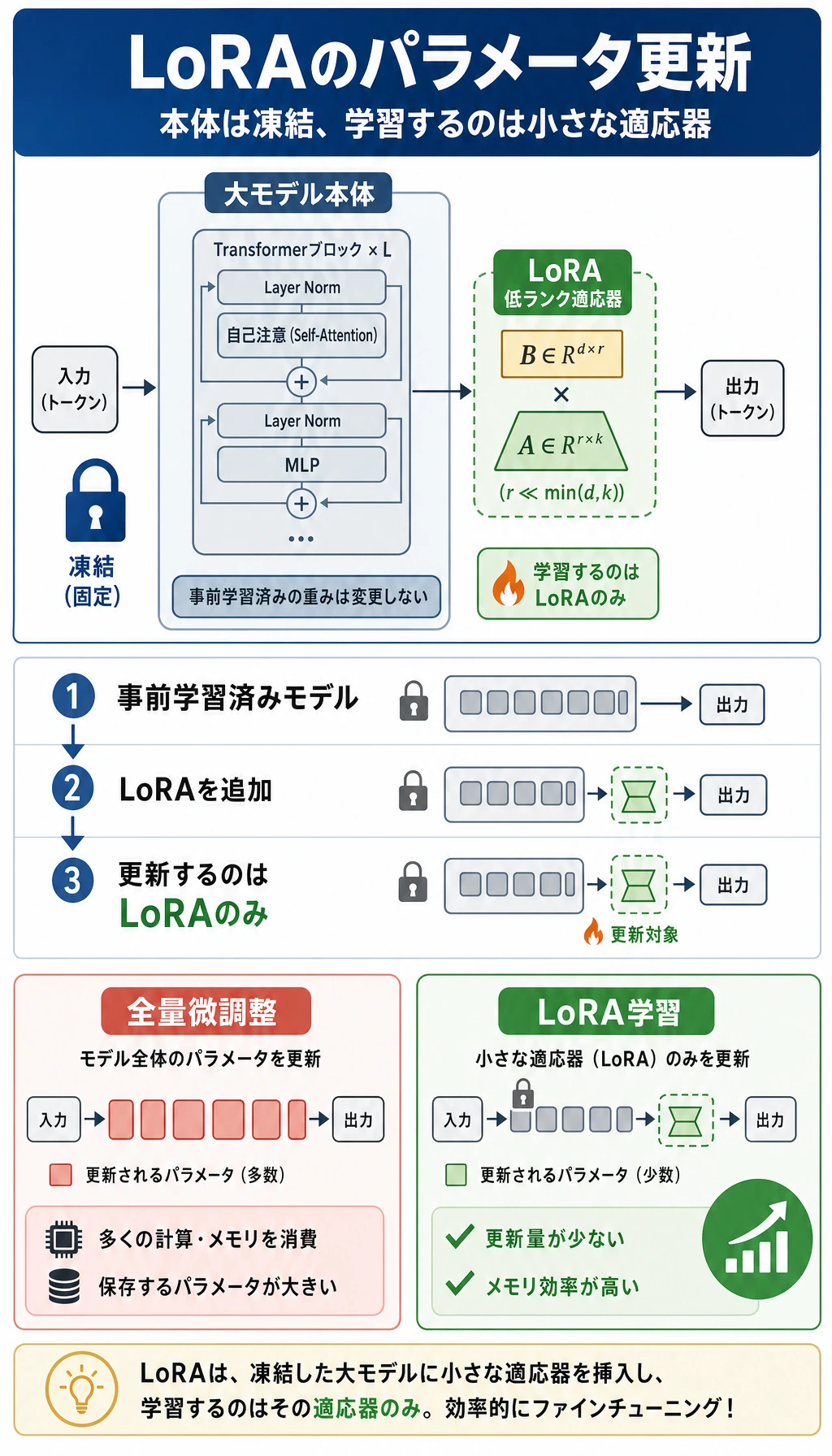
Section titled “LoRA のいちばん核心的な直感は何か?”行列全体を直接変更しない
Section titled “行列全体を直接変更しない”元の重み行列を次のようにします。
W
LoRA の考え方はこうです。
Wを直接学習するのではなく、増分ΔWを学習する
そして実際には次のように使います。
W + ΔW
なぜ「低ランク」なのか?
Section titled “なぜ「低ランク」なのか?”この増分は、完全な大きい行列をそのまま学習するのではなく、通常は次のように表します。
ΔW = A @ B
ここで:
AとBは元の行列よりずっと小さい
これが「低ランク」の核心です。
この節で出てくる記号と略語
Section titled “この節で出てくる記号と略語”| 用語 | 意味 | なぜ重要か |
|---|---|---|
| LoRA | Low-Rank Adaptation、低ランク適応 | 重み行列全体ではなく、小さな低ランク増分を学習する |
| QLoRA | Quantized LoRA、量子化 LoRA | LoRA adapter は学習可能なまま、ベースモデルを低精度で読み込む |
Rank r | A @ B の中間にある小さい次元 | rank が大きいほど表現力は増えるが、メモリと計算量も増える |
W | 元の凍結された重み行列 | 凍結することで学習コストを下げ、adapter 管理もしやすくなる |
ΔW | 学習された重みの増分 | LoRA がベースモデルに足す、タスク固有の小さな変化 |
| Quantization | 4-bit など、少ない bit 数で重みを保存すること | 特にベースモデルが大きいとき、メモリ使用量を大きく減らせる |
最小限の LoRA 行列のイメージ
Section titled “最小限の LoRA 行列のイメージ”import torch
W = torch.randn(8, 8)A = torch.randn(8, 2)B = torch.randn(2, 8)
delta = A @ BW_new = W + delta
print("W の形 :", W.shape)print("delta の形 :", delta.shape)print("W_new の形 :", W_new.shape)期待される出力:
W の形 : torch.Size([8, 8])delta の形 : torch.Size([8, 8])W_new の形 : torch.Size([8, 8])このコードは何を教えているのか?
Section titled “このコードは何を教えているのか?”このコードが教えているのは、次のことです。
- LoRA は重み全体を再学習しない
- 代わりに、より小さい増分構造を学習する
これが、リソースを節約できる根本的な理由です。
![]()
初心者が最初に覚えるとよい比較表
Section titled “初心者が最初に覚えるとよい比較表”| 方法 | まず覚えるべき中心的な動き |
|---|---|
| 全量ファインチューニング | 元のモデルのすべてのパラメータを直接変更する |
| LoRA | 小さな増分行列を学習する |
| QLoRA | 小さな増分を学習しつつ、ベースモデルを量子化する |
この表は初心者にとても役立ちます。3つの方法の違いを、「最も大事な一言」に圧縮して見せてくれるからです。
なぜこれで学習コストを大きく下げられるのか?
Section titled “なぜこれで学習コストを大きく下げられるのか?”元の大きな行列をすべて学習するのは、とてもコストが高いからです。
それに対して、低ランク分解で学習する部分はずっと小さくなります。
したがって、LoRA のエンジニアリング上の価値は、まず次のように覚えるとよいです。
学習するパラメータを少なくしても、タスクへの適応性能を十分に得られる。
これが、実際のプロジェクトで LoRA が広く使われる理由です。
QLoRA はさらに何を解決するのか?
Section titled “QLoRA はさらに何を解決するのか?”LoRA だけでは、なぜ十分でないことがあるのか?
Section titled “LoRA だけでは、なぜ十分でないことがあるのか?”小さな増分パラメータだけを学習しても、ベースモデル本体はやはり大きいです。
モデルを読み込んだ時点で、GPU メモリへの圧迫はまだ大きくなります。
QLoRA の重要なポイント
Section titled “QLoRA の重要なポイント”QLoRA は LoRA に加えて、もう一歩進めます。
ベースモデルをより低い精度に量子化する。
つまり、
- ベースモデルはより省メモリになる
- それでも増分の適応層は学習可能なまま
最小限の直感イメージ
Section titled “最小限の直感イメージ”config = { "base_model_precision": "4bit", "trainable_part": "LoRA adapters", "goal": "より少ない GPU メモリでファインチューニングする"}
print(config)期待される出力:
{'base_model_precision': '4bit', 'trainable_part': 'LoRA adapters', 'goal': 'より少ない GPU メモリでファインチューニングする'}このイメージでいちばん大事なのは、次の点です。
- LoRA:主に学習パラメータを減らす
- QLoRA:それに加えて、ベースモデルの占有メモリも減らす
さらに最小の「リソース制約 -> 方式選択」の例
Section titled “さらに最小の「リソース制約 -> 方式選択」の例”constraints = { "gpu_memory_gb": 12, "want_larger_model": True, "task_boundary_clear": True,}
def choose_peft_route(c): if not c["task_boundary_clear"]: return "まだ急いでファインチューニングしないで、まずタスク境界をはっきりさせましょう。" if c["gpu_memory_gb"] <= 12 and c["want_larger_model"]: return "まずは QLoRA を優先して考えましょう。" return "まずは LoRA から始めても大丈夫です。"
print(choose_peft_route(constraints))期待される出力:
まずは QLoRA を優先して考えましょう。この例は、初心者にとても役立ちます。なぜなら、次の順番を思い出させてくれるからです。
- 先に制約を見る
- そのあとで方法を選ぶ
LoRA と QLoRA は、それぞれいつ向いているのか?
Section titled “LoRA と QLoRA は、それぞれいつ向いているのか?”LoRA が向いているケース
Section titled “LoRA が向いているケース”- リソースにまだ余裕がある
- GPU メモリを極限まで削らなくてもよい
- まずはパラメータ効率のよいファインチューニングを素早く試したい
QLoRA が向いているケース
Section titled “QLoRA が向いているケース”- GPU メモリがかなり厳しい
- より小さなマシンで、より大きなモデルを動かしたい
つまり、次のように言えます。
QLoRA は「リソース制約がある現実的な場面で使いやすい工程上の解決策」です。
最初のプロジェクトでは、どう選ぶと安定か?
Section titled “最初のプロジェクトでは、どう選ぶと安定か?”実用的な判断順は、次のようになります。
- リソースにまだ余裕があるなら、まず LoRA から始める
- GPU メモリがすでにかなり厳しいなら、QLoRA を優先して考える
- まだタスク境界がはっきりしていないなら、まずファインチューニングの細部に急がない
プロジェクトや提案資料で何を見せるとよいか
Section titled “プロジェクトや提案資料で何を見せるとよいか”よくある見せ方は、単に
- 「LoRA/QLoRA を使いました」
ではなく、次の点です。
- なぜ全量ファインチューニングを選ばなかったのか
- どんなリソース制約があったのか
- LoRA または QLoRA がそれぞれ何を解決したのか
- なぜこの方法が今のタスクにとって最も現実的なのか
こうすると、相手には次のことが伝わりやすくなります。
- あなたはファインチューニング方式の選び方を理解している
- 単にいくつかの略語を知っているだけではない
なぜ、これらがファインチューニングのハードルを変えたのか?
Section titled “なぜ、これらがファインチューニングのハードルを変えたのか?”LoRA / QLoRA が広まる前は、大規模モデルのファインチューニングと聞くと、多くの人は次のように考えていました。
- 大きなチームにしかできない
- 機材要件が非常に高い
それらの重要な意味は、まさにここにあります。
もともとハードルが高かったことを、もっと多くのチームや開発者が試せる範囲まで下げた。
これは単なる小さな改善ではなく、実際に手が届く範囲を変えたということです。
このページを終えたら、この証拠カードを残します。
- ベースモデル
- frozen な base はほぼ変化しない
- LoRA パラメータ
- rank、対象モジュール、学習可能パラメータ数
- QLoRAの理由
- 量子化されたベースがメモリ圧迫を減らす
- 評価差分
- 前後のスコアまたは失敗の変化
- リスク
- adapter の品質はデータ品質に強く依存する
よくある誤解
Section titled “よくある誤解”LoRA / QLoRA を「代償なしの強化」だと思うこと
Section titled “LoRA / QLoRA を「代償なしの強化」だと思うこと”確かに強力ですが、完全にコストゼロではありません。
QLoRA を使えばリソースを気にしなくてよいと思うこと
Section titled “QLoRA を使えばリソースを気にしなくてよいと思うこと”軽くはなりますが、無限に軽くなるわけではありません。
方法名だけ覚えて、何を変えているのか理解しないこと
Section titled “方法名だけ覚えて、何を変えているのか理解しないこと”本当に覚えるべきなのは、次の2つです。
- LoRA:増分を学習する
- QLoRA:増分を学習しつつ、ベースモデルを量子化する
コアメッセージ
Section titled “コアメッセージ”- LoRA の核心は「変更するパラメータを少なくする」こと
- QLoRA の核心は「変更するパラメータを少なくしつつ、ベースモデルのメモリもより節約する」こと
- 重要なのは新しい名前だからではなく、ファインチューニングを現実にやりやすくしたから
この節で最も大事なのは、略語を暗記することではなく、次を理解することです。
LoRA はより少ないパラメータでタスク適応を行い、QLoRA はその上で大規模モデルのファインチューニングに必要なリソースのハードルをさらに下げる。
これらが重要なのは、「新しい方法だから」ではなく、「大規模モデルのファインチューニングを本当に実行しやすくしたから」です。
- 自分の言葉で説明してください:なぜ LoRA は「行列全体を再学習する」のではないのですか?
- QLoRA の重要な追加点がベースモデルの量子化であると言えるのはなぜですか?
- GPU メモリが限られているのに、より大きなモデルを試したい場合、なぜ QLoRA が優先候補になりやすいのですか?
- 自分の言葉でまとめてください:LoRA と全量ファインチューニングの最も本質的な違いは何ですか?
解法と解説
- LoRA は元の重み行列を凍結し、小さな low-rank update 行列だけを学習します。ベース行列は変えず、学習した差分を適応時に足すか、後で merge します。
- QLoRA はベースモデルを量子化した形で保持し、メモリを下げながら LoRA adapter を学習します。重要なのは adapter が魔法のように強いことではなく、凍結されたベースが使う VRAM を大きく減らせることです。
- VRAM が限られていると、ベースの量子化によって、full precision では入らない大きなモデルを試せる可能性があります。ただし sequence length、batch size、optimizer memory、評価品質は引き続き確認が必要です。
- 全量ファインチューニングは、すべてまたは大部分の重みを変えます。LoRA は小さな学習可能な適応経路だけを変え、ベースモデルはほぼ凍結したままにします。