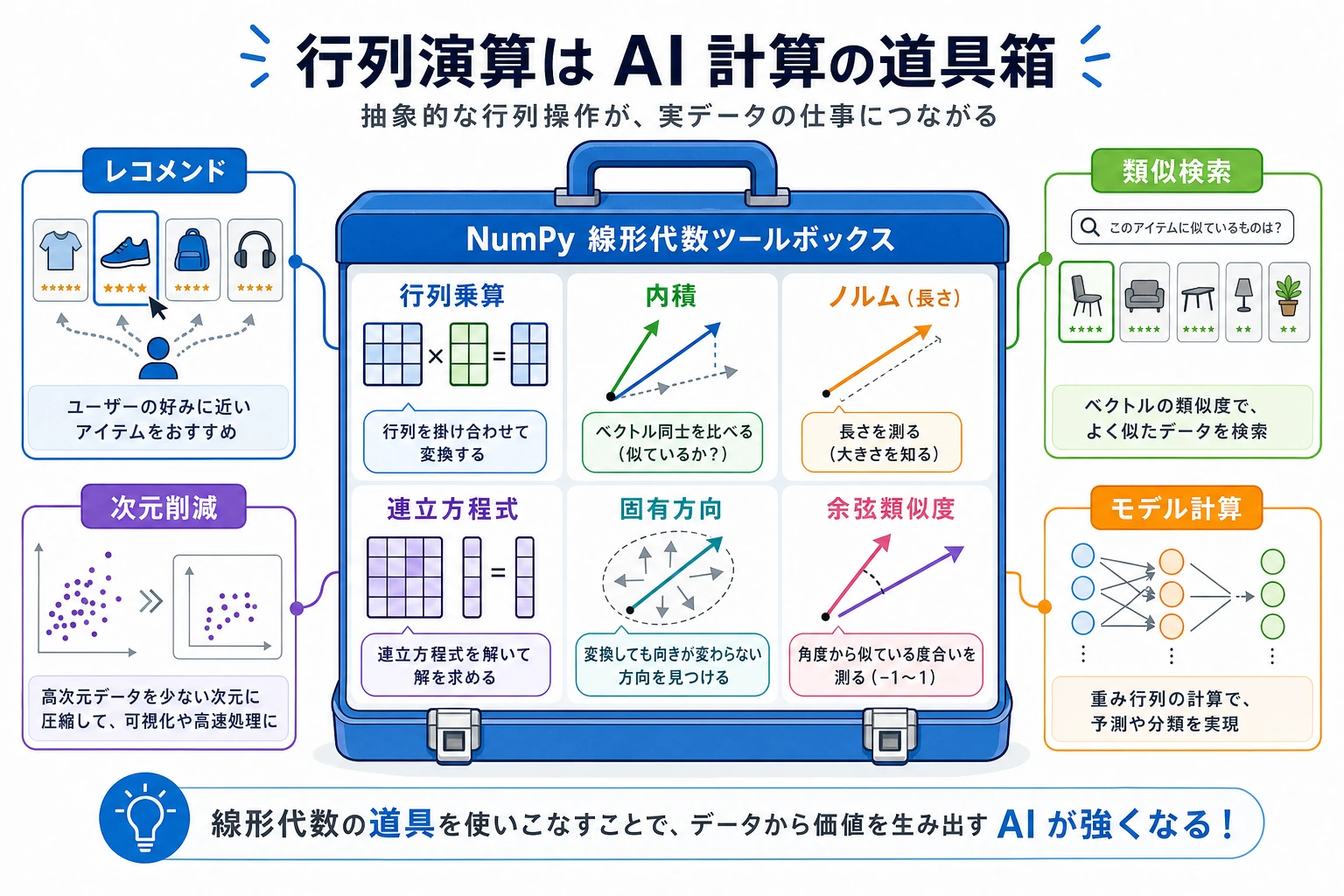
3.2.6 線形代数の基本操作
- 行列積の3つの書き方(dot、matmul、@)を身につける
- 逆行列、行列式、固有値の意味と計算方法を理解する
numpy.linalgモジュールを使って線形代数計算ができるようになる- 線形代数が AI で重要な理由を理解する
なぜ線形代数を学ぶの?
Section titled “なぜ線形代数を学ぶの?”「線形代数」と聞くと、数学っぽくて抽象的に感じるかもしれません。ですが、AI の分野ではもっとも重要な数学の基礎です。
| AI の場面 | 線形代数の役割 |
|---|---|
| ニューラルネットワーク | 各層の計算は行列積そのもの |
| レコメンドシステム | ユーザー-商品行列の分解 |
| 画像処理 | 1枚の画像は行列として表せる |
| 単語ベクトル | 各単語はベクトル、類似度 = 内積 |
| 次元削減 | PCA は固有値と固有ベクトルを求める処理 |
まずは NumPy でこれらの概念を触って、感覚をつかみましょう。4 AI 数学の最小必要基礎で、原理をさらに詳しく説明します。
要素ごとの掛け算 vs 行列積
Section titled “要素ごとの掛け算 vs 行列積”ここは初心者がいちばん混同しやすいポイントです。
import numpy as np
A = np.array([[1, 2], [3, 4]])B = np.array([[5, 6], [7, 8]])
# 要素ごとの掛け算(同じ位置どうしを掛ける)print(A * B)# [[ 5 12]# [21 32]]# 計算過程:1×5=5, 2×6=12, 3×7=21, 4×8=32
# 行列積print(A @ B)# [[19 22]# [43 50]]# 計算過程:# [1×5+2×7, 1×6+2×8] = [19, 22]# [3×5+4×7, 3×6+4×8] = [43, 50]行列積の3つの書き方
Section titled “行列積の3つの書き方”A = np.array([[1, 2], [3, 4]])B = np.array([[5, 6], [7, 8]])
# 方法 1:@ 演算子(おすすめ、いちばん簡潔)C1 = A @ B
# 方法 2:np.matmulC2 = np.matmul(A, B)
# 方法 3:np.dotC3 = np.dot(A, B)
# 3つの方法は結果がまったく同じprint(np.array_equal(C1, C2)) # Trueprint(np.array_equal(C2, C3)) # True行列積のルール
Section titled “行列積のルール”2つの行列が掛け算できる条件は、前の列数 = 後ろの行数 です。
# (2, 3) @ (3, 4) → (2, 4) ✅ 3 == 3A = np.ones((2, 3))B = np.ones((3, 4))C = A @ Bprint(C.shape) # (2, 4)
# (2, 3) @ (2, 4) → ❌ エラー!3 ≠ 2# A = np.ones((2, 3))# B = np.ones((2, 4))# C = A @ B # ValueError!覚え方:(m, n) @ (n, p) → (m, p)
ベクトルの内積
Section titled “ベクトルの内積”1次元配列の @ や np.dot は、内積(点積)を計算します。
a = np.array([1, 2, 3])b = np.array([4, 5, 6])
# 内積 = 1×4 + 2×5 + 3×6 = 32print(a @ b) # 32print(np.dot(a, b)) # 32内積は AI でとても重要です。あとで学ぶコサイン類似度やAttention 機構でも使います。
numpy.linalg モジュール
Section titled “numpy.linalg モジュール”NumPy の linalg サブモジュールには、線形代数の機能がひと通りそろっています。
行列の逆行列は A × A⁻¹ = 単位行列 を満たします。
A = np.array([[1, 2], [3, 4]])
# 逆行列を求めるA_inv = np.linalg.inv(A)print(A_inv)# [[-2. 1. ]# [ 1.5 -0.5]]
# 確認:A × A_inv ≈ 単位行列print(A @ A_inv)# [[1.0000000e+00 0.0000000e+00]# [8.8817842e-16 1.0000000e+00]]# 対角線は 1、それ以外は 0 に近い(浮動小数点の誤差)行列式はスカラー値で、行列の「拡大・縮小の度合い」を表します。
A = np.array([[1, 2], [3, 4]])det = np.linalg.det(A)print(f"行列式: {det:.1f}") # -2.0
# 2×2 行列の行列式 = ad - bc# [[a, b], [c, d]] → 1×4 - 2×3 = -2固有値と固有ベクトル
Section titled “固有値と固有ベクトル”固有値と固有ベクトルは、行列の「DNA」のようなものです。行列の内側にある性質を教えてくれます。
A = np.array([[4, 2], [1, 3]])
# 固有値と固有ベクトルを求めるeigenvalues, eigenvectors = np.linalg.eig(A)print(f"固有値: {eigenvalues}") # [5. 2.]print(f"固有ベクトル:\n{eigenvectors}")# [[ 0.894 -0.707]# [ 0.447 0.707]]連立一次方程式を解く
Section titled “連立一次方程式を解く”方程式を解く:2x + y = 5x + 3y = 7行列形式では Ax = b と書けます。
A = np.array([[2, 1], [1, 3]])b = np.array([5, 7])
# 方程式を解くx = np.linalg.solve(A, b)print(f"x = {x[0]:.2f}, y = {x[1]:.2f}") # x = 1.60, y = 1.80
# 確認print(A @ x) # [5. 7.] ← b と一致するので、解は正しいそのほかの便利な操作
Section titled “そのほかの便利な操作”ノルム(ベクトルの長さ)
Section titled “ノルム(ベクトルの長さ)”v = np.array([3, 4])
# L2 ノルム(ユークリッド距離)l2 = np.linalg.norm(v)print(f"L2 ノルム: {l2}") # 5.0 (3² + 4² = 25, √25 = 5)
# L1 ノルム(絶対値の和)l1 = np.linalg.norm(v, ord=1)print(f"L1 ノルム: {l1}") # 7.0 (|3| + |4| = 7)
# 行列のノルムM = np.array([[1, 2], [3, 4]])print(f"行列の Frobenius ノルム: {np.linalg.norm(M):.2f}") # 5.48行列のランク
Section titled “行列のランク”A = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])rank = np.linalg.matrix_rank(A)print(f"行列のランク: {rank}") # 2(フルランクではない。3行目 = 1行目×(-1) + 2行目×2)よく使う関数一覧
Section titled “よく使う関数一覧”| 関数 | 役割 | 例 |
|---|---|---|
A @ B | 行列積 | np.array([[1,2],[3,4]]) @ np.eye(2) |
np.linalg.inv(A) | 逆行列 | |
np.linalg.det(A) | 行列式 | |
np.linalg.eig(A) | 固有値と固有ベクトル | |
np.linalg.solve(A, b) | 方程式 Ax=b を解く | |
np.linalg.norm(v) | ノルム | |
np.linalg.matrix_rank(A) | 行列のランク | |
A.T | 転置 | |
np.trace(A) | トレース(対角線の和) |
実践:コサイン類似度を計算する
Section titled “実践:コサイン類似度を計算する”コサイン類似度は、AI で 2 つのベクトルの「似ている度合い」を測る定番の方法です。あとで学ぶ単語ベクトル、レコメンドシステム、RAG でも何度も使います。
公式:cos(θ) = (a · b) / (||a|| × ||b||)
import numpy as np
def cosine_similarity(a, b): """2つのベクトルのコサイン類似度を計算する""" dot_product = a @ b # 内積 norm_a = np.linalg.norm(a) # a の長さ norm_b = np.linalg.norm(b) # b の長さ return dot_product / (norm_a * norm_b)
# 例:モデルサービングプロファイルを比較する# 各次元は [accuracy, throughput, low_latency, low_memory, stability]baseline = np.array([4, 3, 2, 2, 4])quantized = np.array([4, 3, 3, 3, 4])experimental = np.array([2, 5, 5, 4, 2])
print(f"Baseline vs quantized: {cosine_similarity(baseline, quantized):.4f}") # 0.9857print(f"Baseline vs experimental: {cosine_similarity(baseline, experimental):.4f}") # 0.8137print(f"Quantized vs experimental: {cosine_similarity(quantized, experimental):.4f}") # 0.8778このページを終えたら、この evidence card を残します。
- 配列状態
- 操作前の shape、dtype、axis、サンプル値
- 操作
- indexing、slicing、broadcasting、reshape、線形代数、またはランダム/stat関数
- 出力
- 結果の配列形状、値、または統計量
- 失敗確認
- 軸の混同、view/copy の落とし穴、ブロードキャスト不一致、または誤った形状
- 期待される成果
- 配列操作を確認できる出力形状と値
| 概念 | 説明 | NumPy 関数 |
|---|---|---|
| 行列積 | (m,n) @ (n,p) → (m,p) | A @ B または np.matmul |
| 逆行列 | A × A⁻¹ = I | np.linalg.inv() |
| 行列式 | 行列の拡大・縮小の度合い | np.linalg.det() |
| 固有値/ベクトル | 行列の「DNA」 | np.linalg.eig() |
| 方程式を解く | Ax = b を解く | np.linalg.solve() |
| ノルム | ベクトルの長さ | np.linalg.norm() |
手を動かしてみよう
Section titled “手を動かしてみよう”練習 1:行列積
Section titled “練習 1:行列積”# 3 つのパイプライン段階ごとのリソースコストcost_per_stage = np.array([4, 12, 6]) # [embed, rerank, generate]
# 3 つのリクエストバッチにおける段階呼び出し回数stage_counts = np.array([ [3, 1, 2], # バッチ 1 [0, 2, 5], # バッチ 2 [5, 0, 3] # バッチ 3])
# 行列積を使って、それぞれのバッチの総コストを計算する# totals = ?練習 2:方程式を解く
Section titled “練習 2:方程式を解く”# 次の連立方程式を解く:# 3x + 2y - z = 1# x - y + 2z = 5# 2x + 3y - z = 0## ヒント:Ax = b の形に書き直す練習 3:コサイン類似度の応用
Section titled “練習 3:コサイン類似度の応用”# モデルサービングプロファイルの特徴ベクトルがあるとします# 各次元は [accuracy, throughput, low_latency, low_memory, stability]profiles = { "baseline": np.array([4, 3, 2, 2, 4]), "quantized": np.array([4, 3, 3, 3, 4]), "experimental": np.array([2, 5, 5, 4, 2]),}
# コサイン類似度を使って、"baseline" と最も似ているプロファイルを見つける# ヒント:"baseline" と他の各プロファイルのコサイン類似度を計算する参考実装と解説
- リソースコストの例では、
stage_counts @ cost_per_stageが最もすっきりしたベクトル化答えです。コストが[4, 12, 6]、呼び出し回数が[3,1,2]、[0,2,5]、[5,0,3]なら、合計は36、54、38です。 - 連立方程式
3x + 2y - z = 1、x - y + 2z = 5、2x + 3y - z = 0は、np.linalg.solveでx=1、y=0、z=2になります。 - プロファイルのコサイン類似度では、ベクトル長で正規化した値を比較します。最も似ているプロファイルは、単なる内積ではなくコサイン値が最大のプロファイルです。