12.3.2 ビデオ生成技術
- ビデオ生成が画像生成より1段難しい理由を理解する
- 時間的一貫性と動きのモデリングの核心的な問題を理解する
- 主流のビデオ生成アプローチの全体像をつかむ
- ビデオ生成がなぜ「単一モデル」よりも「複数モジュールのシステム」に近いのかを理解する
まずは全体地図を作る
Section titled “まずは全体地図を作る”ビデオ生成は、「単一フレームの品質 + 時間的一貫性 + ワークフローの組み立て」として理解すると分かりやすいです。
flowchart LR A["1フレームが本物っぽい"] --> B["前後のフレームが一致している"] B --> C["動きやカメラの動きが自然"] C --> D["さらに音声 / 制御 / 後処理と組み合わせる"]なので、この節で本当に解決したいのは次の点です。
- なぜビデオ生成は「画像をたくさん作ればいい」ではないのか
- なぜ本質的に時間が連続するシステムとして考える必要があるのか
一、なぜビデオ生成は難しいのか?
Section titled “一、なぜビデオ生成は難しいのか?”画像生成は単一フレームの整合性だけでよい
Section titled “画像生成は単一フレームの整合性だけでよい”テキストから画像を生成するタスクで最も大事なのは、次の点です。
- この1枚の画像が本物のように見えること
ビデオ生成は前後の連続性も必要
Section titled “ビデオ生成は前後の連続性も必要”ビデオでは、1フレームの品質に加えて、次のことも満たさなければなりません。
- 同じ人物が急に別人にならない
- 背景がフレームごとにちらつかない
- 動きがなめらかである
- カメラの動きがつながっている
つまり、ビデオ生成で新しく最も重要になる問題は次のものです。
時間的一貫性。
初学者向けの分かりやすい比喩
Section titled “初学者向けの分かりやすい比喩”ビデオ生成は、次のように考えるとイメージしやすいです。
- 1枚の写真を作るのではなく、短い演技を撮る
写真はその1枚が良ければよいですが、 ビデオではさらに次のことが必要です。
- 演者の顔が急に変わらない
- 光が不自然に飛ばない
- 動きがカクカクしない
この比喩は、まず次の点をつかむのに役立ちます。
- ビデオで難しいのは「1フレームが本物っぽいか」だけではない
- 「全体としてつながりが自然か」がもっと重要
二、まずは最も単純な見方でビデオを理解する
Section titled “二、まずは最も単純な見方でビデオを理解する”ビデオの本質とは?
Section titled “ビデオの本質とは?”かなり粗く言うと、ビデオは次のように見なせます。
ビデオ = 時間順に並んだ画像フレームの列。
frames = ["frame_1", "frame_2", "frame_3", "frame_4"]
for i, frame in enumerate(frames, start=1): print(f"t={i}: {frame}")期待される出力:
t=1: frame_1t=2: frame_2t=3: frame_3t=4: frame_4t は時間順序だと考えてください。ビデオモデルは、各フレームの内容だけでなく、フレーム同士の順序関係も保つ必要があります。
もちろん、これでビデオのすべてを表せるわけではありません。 ただし、どのビデオ生成モデルでも避けて通れない出発点ではあります。
- 空間構造を理解するだけでなく
- 時間順序も理解する必要がある
三、なぜ「各フレームが良い」だけでは「良いビデオ」にならないのか?
Section titled “三、なぜ「各フレームが良い」だけでは「良いビデオ」にならないのか?”典型的な失敗例
Section titled “典型的な失敗例”あるビデオで、左から右へ走る猫を考えてみましょう。 各フレームを単独で見るとどれも良さそうでも、もし次のようなら違和感があります。
- 1フレーム目はオレンジ色の猫
- 2フレーム目は灰色の猫
- 3フレーム目で体型が急に大きくなる
この場合、ユーザーはやはり不自然だと感じます。
つまり、ビデオ生成で追加される重要な制約は
Section titled “つまり、ビデオ生成で追加される重要な制約は”- フレーム間の一貫性
- 動きの連続性
- 同一性の保持
だからこそ、ビデオタスクは次のように単純化できません。
「画像をたくさん作ればそれで終わり」
四、「フレームからクリップへ」の最小イメージ
Section titled “四、「フレームからクリップへ」の最小イメージ”frames = ["f1", "f2", "f3", "f4"]clips = [(frames[i], frames[i + 1]) for i in range(len(frames) - 1)]
print("frames:", frames)print("clips :", clips)期待される出力:
frames: ['f1', 'f2', 'f3', 'f4']clips : [('f1', 'f2'), ('f2', 'f3'), ('f3', 'f4')]clips は隠れた要件を見える形にしています。単独のフレームが良いだけでなく、隣り合うフレームのつながりも自然でなければなりません。
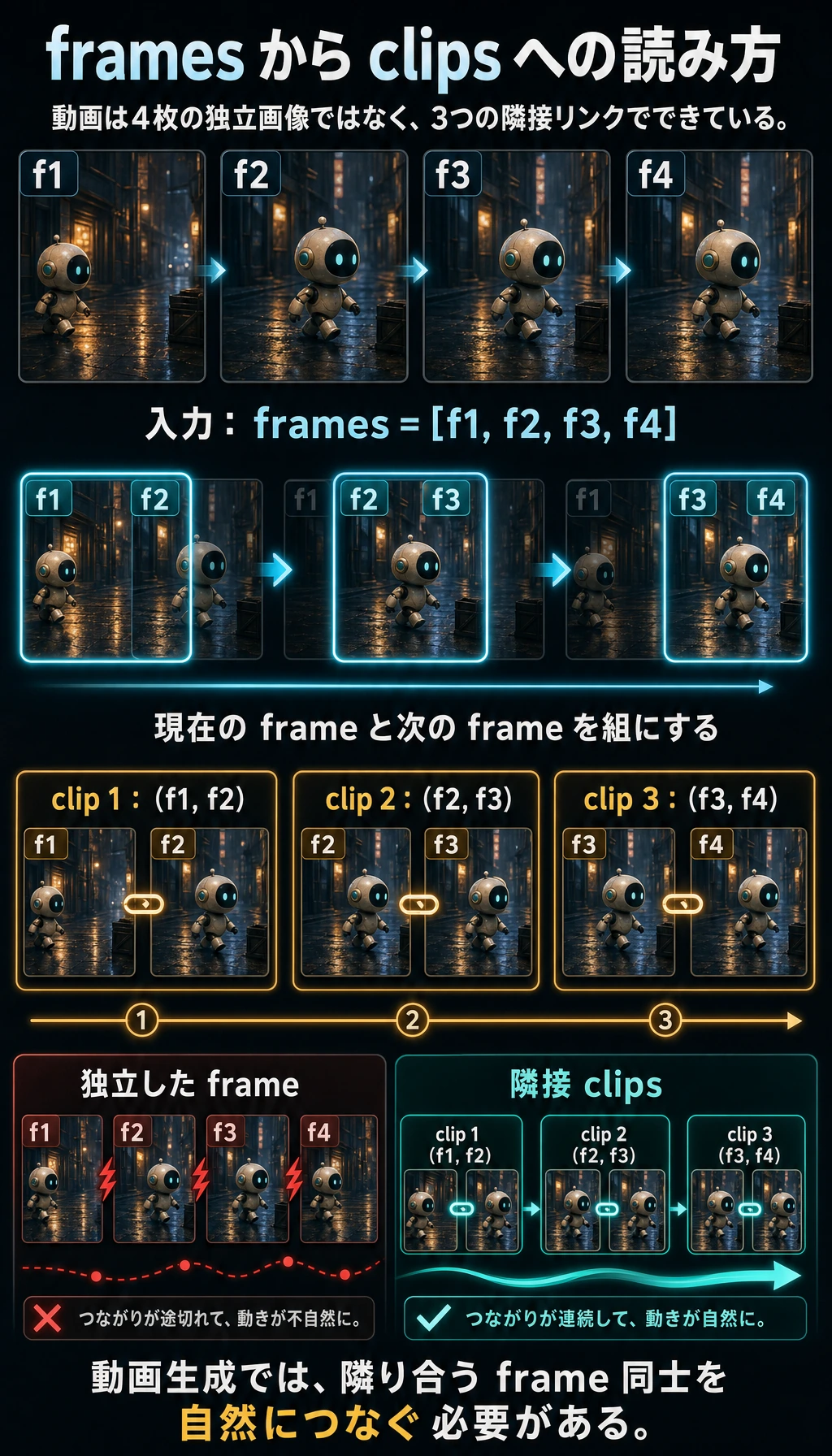
この例は何を教えているのか?
Section titled “この例は何を教えているのか?”この例が教えているのは次の点です。
- ビデオは独立したサンプルの集まりではない
- 隣り合うフレームには自然な関係がある
- 多くのモデルは、この局所的な時間関係をモデリングの基礎にしている
五、主流のビデオ生成アプローチは、まずどう理解すればよいか?
Section titled “五、主流のビデオ生成アプローチは、まずどう理解すればよいか?”フレームごとに生成する方法
Section titled “フレームごとに生成する方法”考え方:
- 1フレームずつ生成する
- そのあと、できるだけつながりを自然にする
利点:
- 理解しやすい
欠点:
- 一貫性が崩れやすい
画像モデルを時間次元へ拡張する方法
Section titled “画像モデルを時間次元へ拡張する方法”考え方:
- まず画像生成の能力を再利用する
- そこに時間のモデリングを加える
これはとても自然な流れです。なぜなら、画像生成自体がすでにかなり成熟しているからです。
ビデオ拡散のアプローチ
Section titled “ビデオ拡散のアプローチ”考え方:
- 単一フレームだけに拡散をかけるのではなく、ビデオ全体の表現に対して拡散とノイズ除去を行う
これは、今後ますます重要になる方向です。
初学者がまず覚えるとよいアプローチ比較表
Section titled “初学者がまず覚えるとよいアプローチ比較表”| アプローチ | まず覚えるべき感覚 |
|---|---|
| フレームごとの生成 | 理解しやすいが、一貫性が弱くなりやすい |
| 画像モデルの時間次元拡張 | とても自然なエンジニアリングの進化 |
| ビデオ拡散 | ビデオ全体をよりまとめて考える |
この表は、初心者にとってとても役立ちます。 「いろいろある」を、3つのつかみやすい考え方に圧縮してくれるからです。
六、なぜ多くのビデオ生成アプローチは画像モデルとつながっているのか?
Section titled “六、なぜ多くのビデオ生成アプローチは画像モデルとつながっているのか?”それは、画像生成がすでに多くの基礎課題を解決しているからです。
- テキスト条件による制御
- 1フレームの見た目の品質
- 細部の表現
そこで自然に出てくる考え方は次の通りです。
まず単一フレームの品質を作り、その後で「時間」という次元を少しずつ足していく。
そのため、多くのビデオ生成システムは、見た目としては次のような構成になっています。
- 画像拡散モデル + 時間モデリング
これは偶然ではなく、とても自然な進化の流れです。
七、ビデオ生成でよく使われる評価軸
Section titled “七、ビデオ生成でよく使われる評価軸”単一フレームの品質
Section titled “単一フレームの品質”各フレーム自体が本物らしく見えるか。
時間的一貫性
Section titled “時間的一貫性”前後のフレームがなめらかで安定しているか。
動きの自然さ
Section titled “動きの自然さ”動きの軌跡が自然かどうか。
ユーザーのテキストや参照条件が、ビデオ全体にわたって反映されているか。
つまり、ビデオ生成の評価は画像生成より複雑になりやすいです。 少なくとも「空間的な品質 + 時間的な品質」の両方を見る必要があるからです。
初学者がまず覚えるとよい評価表
Section titled “初学者がまず覚えるとよい評価表”| 観点 | まず見るべきこと |
|---|---|
| 単一フレームの品質 | 1枚1枚の見た目が本物っぽいか |
| 時間的一貫性 | 前後で急に変わっていないか |
| 動きの自然さ | 動きの軌跡が自然か |
| 条件制御 | テキストや参照条件が全体に通っているか |
この表も初心者に向いています。 「ビデオの品質」を、観察しやすい複数の問題に分解してくれるからです。
八、なぜビデオ生成はエンジニアリング上も難しいのか?
Section titled “八、なぜビデオ生成はエンジニアリング上も難しいのか?”計算量が大きい
Section titled “計算量が大きい”なぜなら、対象はもはや次のような単純なものではなくなるからです。
- 高さ × 幅 × チャンネル
代わりに、次のようになります。
- フレーム数 × 高さ × 幅 × チャンネル
失敗が目立ちやすい
Section titled “失敗が目立ちやすい”画像では小さな欠点でも、ユーザーが許容してくれることがあります。 しかしビデオでは、前後で跳ねるような変化があると、すぐに不自然だと分かってしまいます。
インタラクションのコストが高い
Section titled “インタラクションのコストが高い”ビデオ生成は通常、より遅く、より高価で、さらにエンジニアリング最適化への依存も大きくなります。
九、重要なプロダクト視点
Section titled “九、重要なプロダクト視点”実際のビデオ生成プロダクトは、1つの巨大な単一モデルだけに頼っているとは限りません。 むしろ、次のような要素の組み合わせで成り立っていることが多いです。
- キーフレーム生成
- フレーム補間
- 音声合成
- 姿勢制御
- 後処理
つまり、
ビデオ生成プロダクトは、多くの場合「複数モジュールのワークフローシステム」に近い。
これはとても重要です。なぜなら、次のことを意味するからです。
- すべての問題を1つの巨大な end-to-end モデルに任せる必要はない
これをプロジェクトやシステム設計として見せるなら、何を見せるべきか
Section titled “これをプロジェクトやシステム設計として見せるなら、何を見せるべきか”本当に見せる価値が高いのは、単に
- 「ビデオを生成できました」
と言うことではありません。
むしろ、次のような点です。
- 単一フレームの品質と時間的一貫性をどう分けて評価したか
- システムにどんなモジュールを使ったか
- どこが最も壊れやすいか
- なぜ単一モデルのボタン1つではなく、多モジュールのワークフローに近いのか
こうすると、相手にも次のことが伝わりやすくなります。
- あなたはビデオ生成のシステム的な難しさを理解している
- ただ結果を出力しただけではない
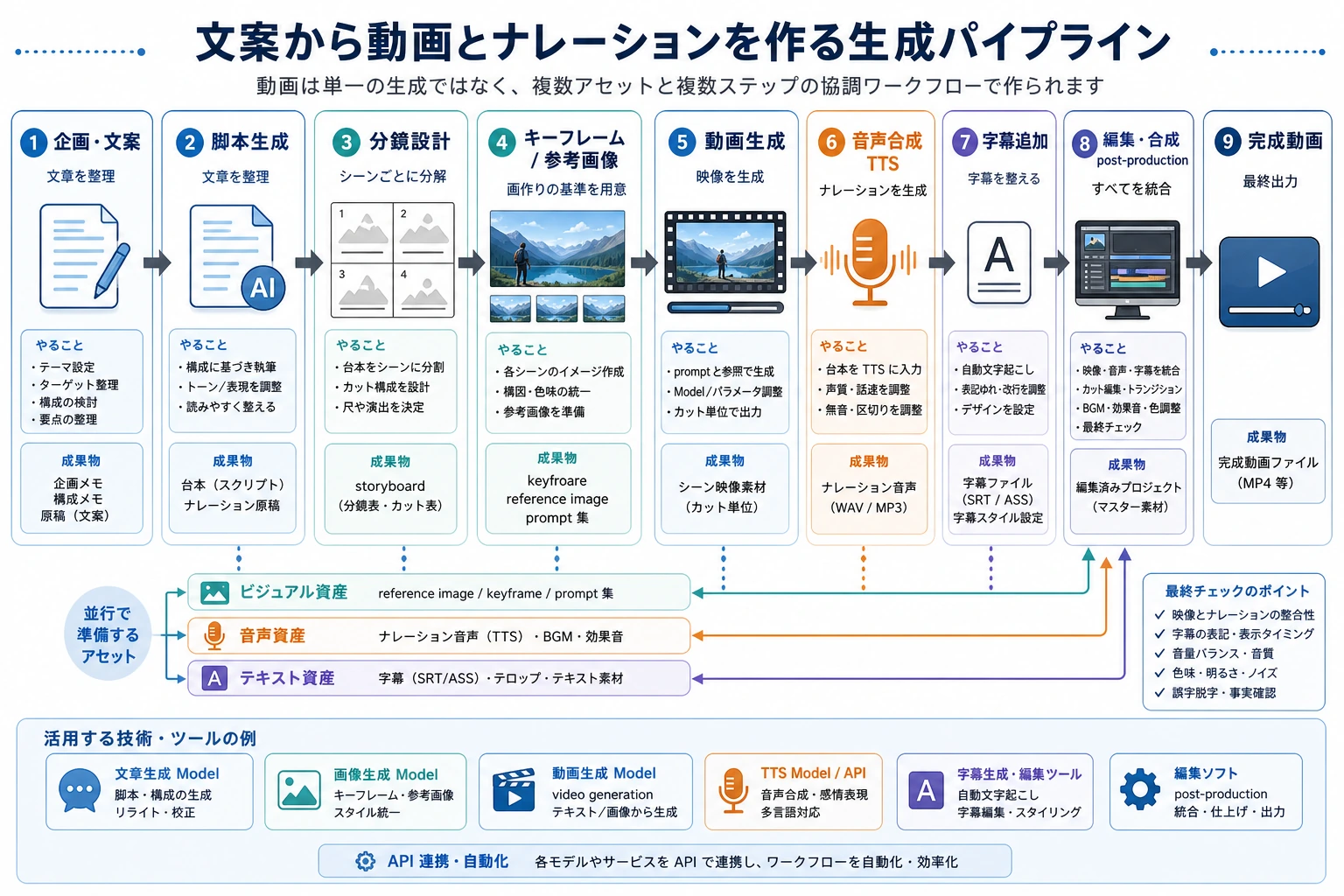
このページを終えたら、この evidence card を残します。
- ストーリーボード
- シーン一覧、duration、camera/voice/subtitle/timing のメモ
- 資産一覧
- images、audio、voice、captions、clips、source/license フィールド
- 同期チェック
- 音声テキストのタイミング、口パク、ショットの連続性、またはフレームの一貫性
- 失敗確認
- ちらつき、アイデンティティのずれ、音声不一致、安全でない類似、または書き出しの問題
- 期待される成果
- レビュー用メモを含むストーリーボードまたはタイムラインのアーティファクト
この節で最も大事なのは、あるアプローチ名を覚えることではなく、安定した直感を作ることです。
ビデオ生成 = 各フレームを生成すること + フレーム間の自然な連続性を保つこと。
これが、ビデオ生成が画像生成より難しく、しかもエンジニアリング上も大きな चुनौतीになる根本理由です。
- 自分の言葉で説明してください。なぜビデオ生成は画像生成より1段多い核心的な難しさがあるのでしょうか?
- あるビデオの各フレームは単独ではとても良いのに、つなげると不自然に見える場合、どの層に問題があると考えられますか?
- なぜ多くのビデオ生成システムは、本質的に「複数モジュールのワークフロー」に近いと言えるのでしょうか?
- 短いビデオ生成プロダクトを作るなら、まず単一フレームの品質と時間的一貫性のどちらを優先して改善しますか?その理由も考えてみてください。
解法と解説
- 動画には時間があります。1 枚のよい画像を作るだけでなく、人物や物体の同一性、動き、カメラ、光、場面状態をフレーム間で保つ必要があります。
- 各フレームはきれいなのに再生すると跳ねるなら、temporal consistency の層が失敗しています。動き、物体の持続性、カメラ軌道が連続していません。
- 多くの動画生成システムが multi-module workflow になるのは、prompt 理解、keyframe 生成、motion control、補間、upscaling、音声、編集、レビューがそれぞれ別の問題を解くからです。
- 多くの短尺動画製品では、早い段階で temporal consistency を優先すべきです。少し美しさが落ちても安定した clip の方が、単体フレームはきれいでもちらつきや同一性の崩れがある sequence より使いやすいからです。