5.1.1 機械学習基礎ロードマップ:タスク、データ、モデル、スコア
機械学習は、すべてのルールを手書きせず、モデルにデータからパターンを学ばせるところから始まります。最初の習慣はアルゴリズム暗記ではなく、小さなプロジェクトループです。
まずマップを見る
Section titled “まずマップを見る”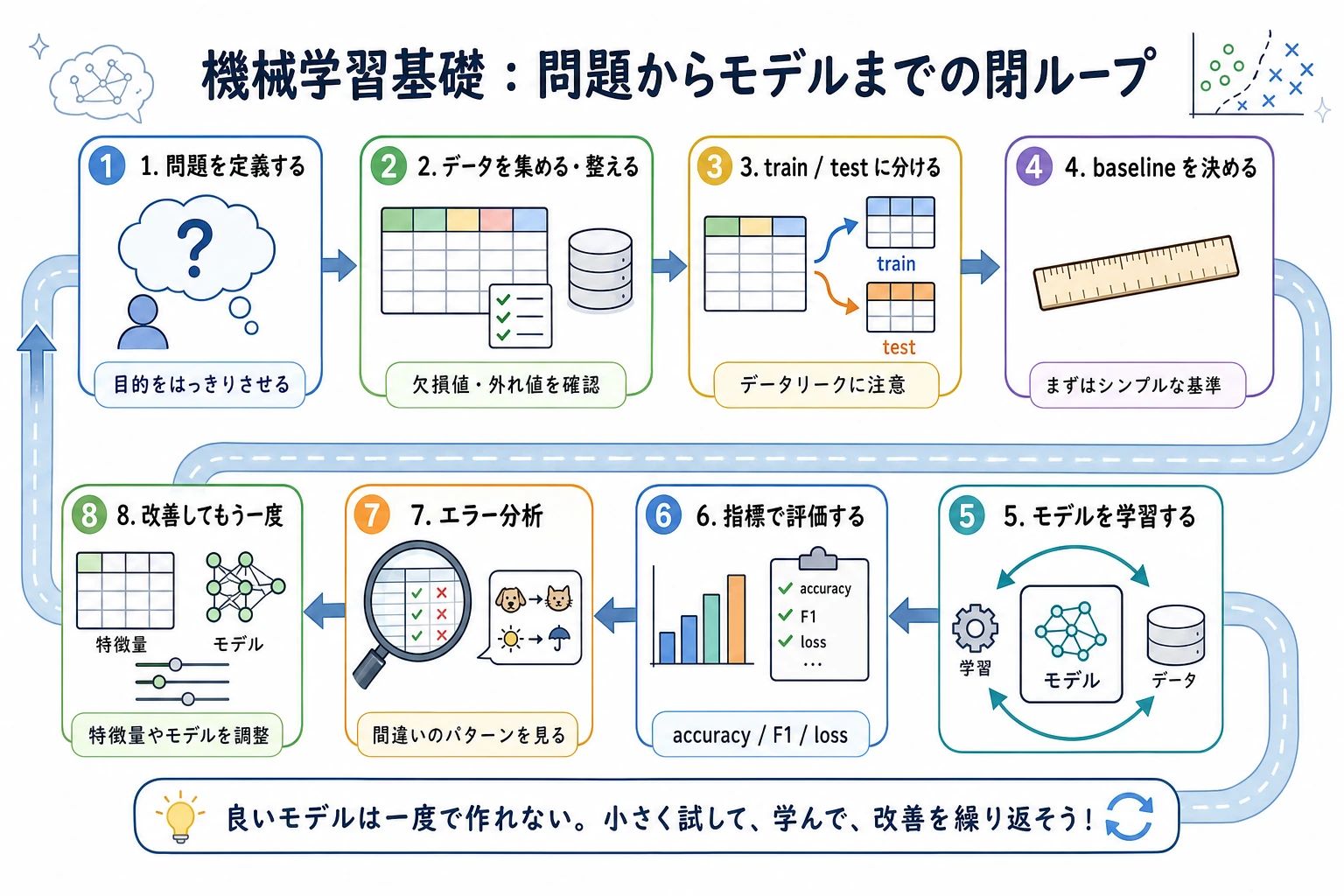
このループを覚えます。
タスク定義データ分割モデル学習予測評価次の判断
| 用語 | 最初の意味 |
|---|---|
| feature | モデルが使う入力列 |
| label / target | モデルが予測する答え |
| train set | 学習に使うデータ |
| test set | 汎化を確認するために取っておくデータ |
| baseline | 比較用のシンプルな最初のモデル |
最小 sklearn ループを動かす
Section titled “最小 sklearn ループを動かす”ml_first_loop.py を作り、scikit-learn をインストールしてから実行します。
from sklearn.datasets import load_irisfrom sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import train_test_split
X, y = load_iris(return_X_y=True)X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y)
model = LogisticRegression(max_iter=200)model.fit(X_train, y_train)predictions = model.predict(X_test)
print("task: classification")print("test_accuracy:", round(model.score(X_test, y_test), 3))print("prediction_count:", len(predictions))出力:
task: classificationtest_accuracy: 0.967prediction_count: 30これが最小の有用な機械学習ループです。先に分割し、学習データだけで学習し、テストデータで評価します。
このページを終えたら、この evidence card を残します。
- ML 問題
- 教師あり、教師なし、評価、または特徴量エンジニアリングのタスク
- ベースライン
- まずは最も簡単な sklearn/モデリングループと固定の train/test 分割
- 出力
- prediction、metric、chart、またはmodel decision note
- 失敗確認
- データリーク、不明確なターゲット、弱いベースライン、または指標不一致
- 期待される成果
- 指標と1件の失敗観察を含む最小限のMLループ
この順番で学ぶ
Section titled “この順番で学ぶ”| 順番 | 読む | 練習すること |
|---|---|---|
| 1 | 5.1.2 機械学習とは | タスク種別、特徴量、ラベル |
| 2 | 5.1.3 Scikit-learn 入門 | fit、predict、score |
| 3 | 5.1.4 数学が機械学習へ入る流れ | ベクトル、確率、loss、最適化 |
| 4 | 5.1.5 機械学習の発展史 | 主なアルゴリズムが生まれた理由 |
| 5 | 5.1.6 sklearn と Matplotlib ワークショップ | 実行、可視化、baseline の説明 |
タスク種別を言える、X と y を識別できる、train/test 分割の理由を説明できる、baseline スコアを証拠として残せるなら合格です。
確認の考え方と解説
Xは特徴量行列です。行はサンプル、列はモデルが使える入力です。yはラベルまたは target で、モデルが予測する答えです。- train/test 分割が重要なのは、test set が新しいデータの代わりになるからです。学習中に test 情報が入ると、そのスコアは汎化の証拠ではなくなります。
- 合格する baseline 記録には、タスク種別、分割設定、モデル、指標、そして失敗しうる理由を 1 文で残します。