11.1.1 テキスト基礎ロードマップ:Token、整形、表現
この章の目的は、NLP の入り口を作ることです。モデルは文字列をそのまま理解できません。まずテキストを小さな単位に分け、必要な形に整え、数値として扱えるようにします。
先に全体像を見る
Section titled “先に全体像を見る”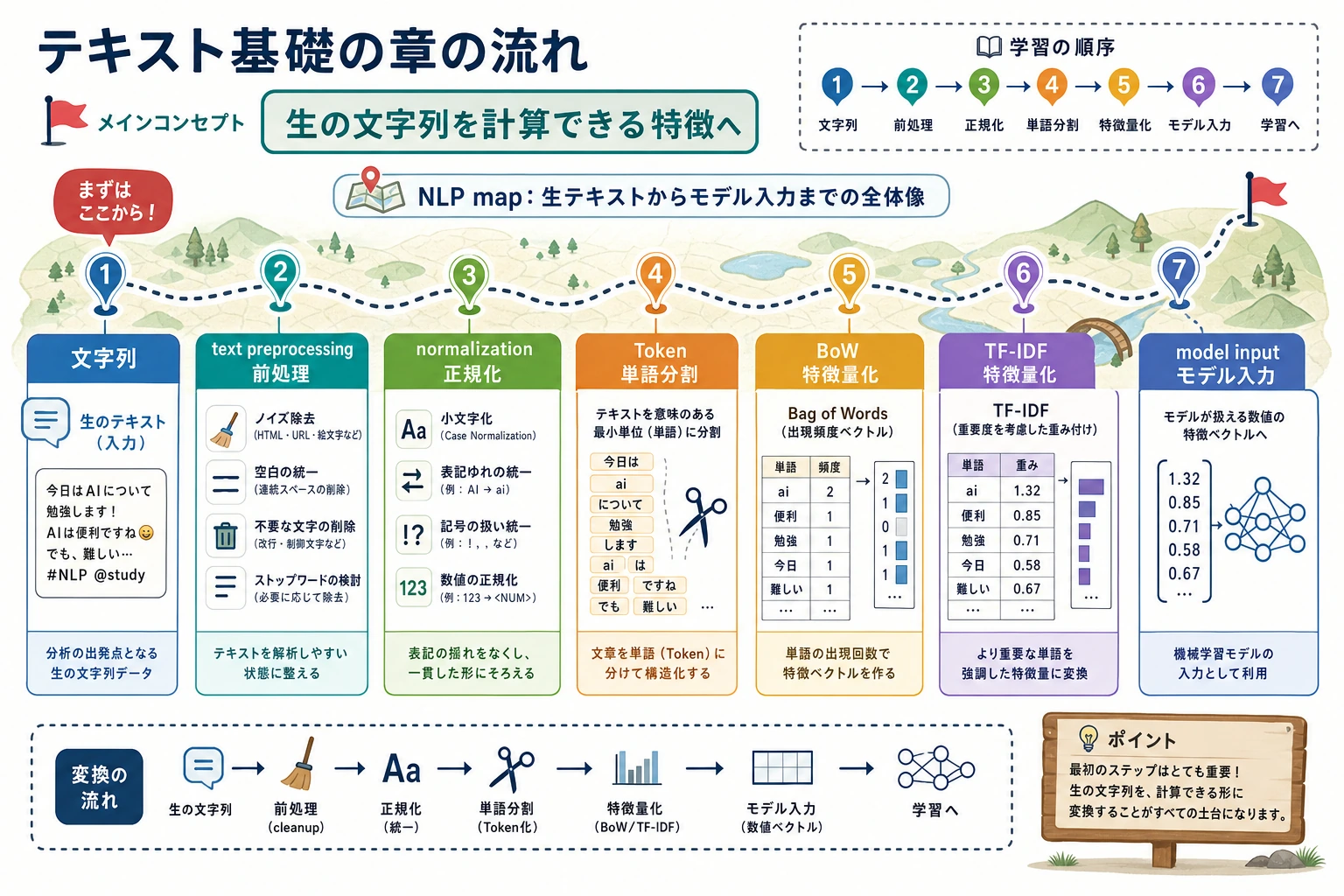
読む順番はシンプルです。
| 順番 | 学ぶこと | できるようになること |
|---|---|---|
| 1 | NLP タスクの種類 | 分類、抽出、生成の出力の違いを見分ける |
| 2 | 前処理 | 生テキストを安定した入力にする |
| 3 | 表現 | token を ID や特徴量に変える |
Token から始める
Section titled “Token から始める”
token は、モデルに渡すために切り出した最小単位です。英語なら単語に近いこともありますが、実際の tokenizer では単語の一部になることもあります。最初は「文章を小さな部品に分ける」と理解すれば十分です。
次のコードで、最小の token 化と ID 化を動かします。
text = "RAG answers need citations"tokens = text.lower().split()vocab = {token: index for index, token in enumerate(sorted(set(tokens)))}ids = [vocab[token] for token in tokens]
print("tokens:", tokens)print("ids:", ids)print("vocab_size:", len(vocab))期待される出力:
tokens: ['rag', 'answers', 'need', 'citations']ids: [3, 0, 2, 1]vocab_size: 4操作のコツ:lower() は大文字小文字をそろえます。split() は空白で分けるだけなので、本格的な日本語、中国語、英語混在テキストでは専用 tokenizer を使います。
出力でタスクを見分ける
Section titled “出力でタスクを見分ける”
初心者が迷ったときは、モデル名より先に出力を見ます。
| タスク | 入力 | 出力 |
|---|---|---|
| 分類 | 文章 | 1 つのラベル |
| 系列ラベリング | token の列 | token ごとのラベル |
| 要約・翻訳 | 文章 | 新しい文章 |
| 抽出 | 文章 | 構造化フィールド |
この章を終える前に、次を自分の言葉で説明できれば十分です。
| チェック | 合格ライン |
|---|---|
| token とは何か | テキストをモデルに渡すための小さな単位だと説明できる |
| 前処理の目的 | 掃除ではなく、入力を安定させる工程だと説明できる |
| 表現の目的 | テキストを計算できる形に変えることだと説明できる |
| 次章とのつながり | ID や特徴量から embedding へ進む流れを説明できる |
このページを終えたら、この evidence card を残します。
- 生テキスト
- クリーニングやトークナイズ前の元の例
- 処理済みテキスト
- 整形済みテキスト、トークン、正規化メモ、削除項目
- タスク境界
- classification、extraction、retrieval、generation、または QA の出力
- 失敗確認
- 意味の喪失、誤ったトークン分割、言語の問題、またはあいまいなラベル
- 期待される成果
- 前後のテキストサンプルと、token または表現の出力