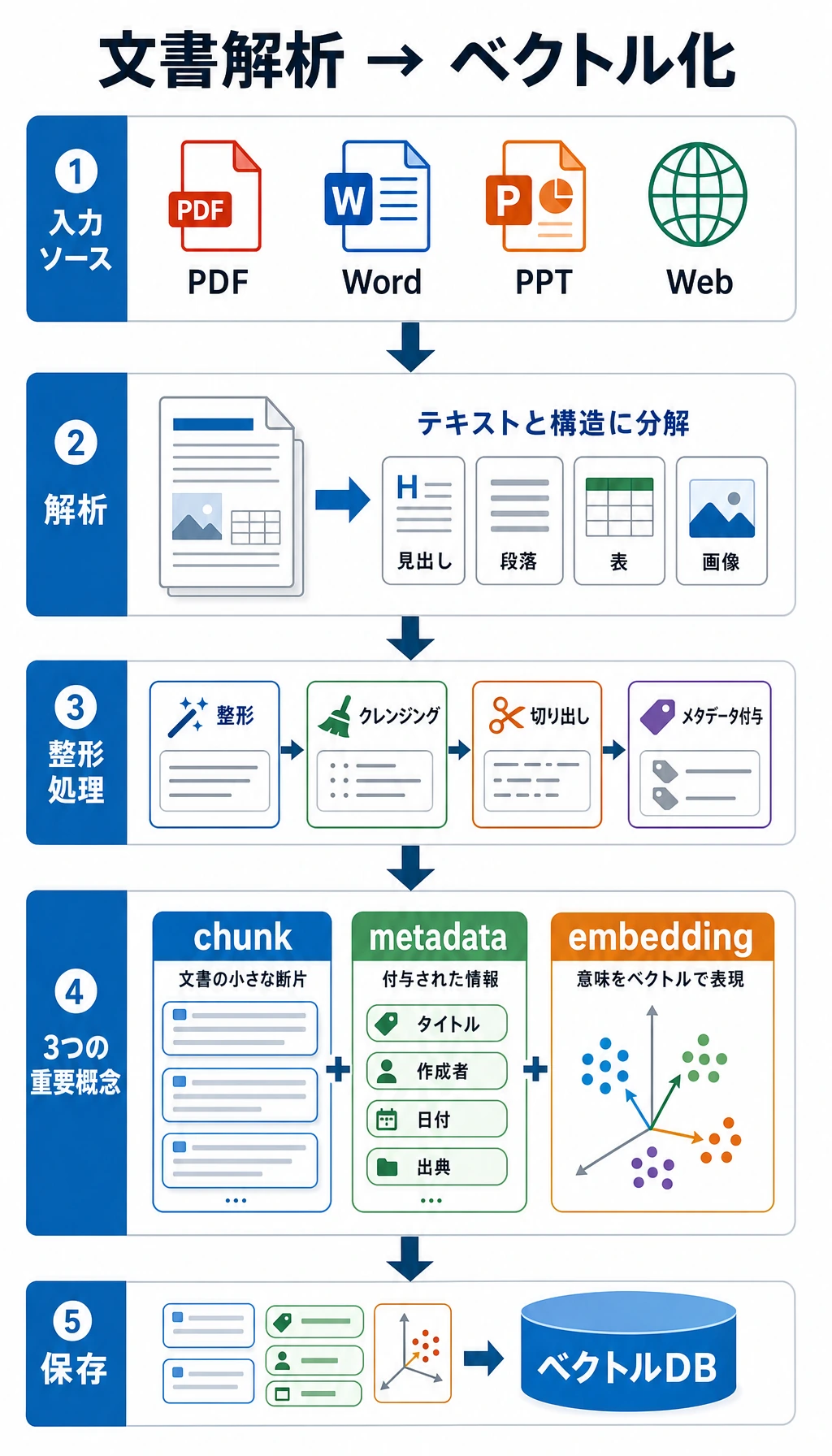
8.1.3 文書処理とベクトル化
この節を終えると、あなたは次のことができるようになります。
- なぜ RAG の効果が前処理に大きく左右されるのかを理解する
- 文書クリーニング、分割、重なり、メタデータの感覚をつかむ
- 簡単に動く分割と検索の例を自分で書く
- 「ベクトル化」が何をしているのかを理解する
一、なぜ RAG は「文書をそのまま入れる」だけではだめなのか?
Section titled “一、なぜ RAG は「文書をそのまま入れる」だけではだめなのか?”実際の文書は、たいてい長くて、雑然としていて、情報が混ざっています。
たとえば PDF には次のようなものが含まれます。
- ヘッダーとフッター
- 目次
- 空行
- 見出しの階層
- 表
- 重複したテキスト
これをそのままモデルに入れると、よくある問題は次のとおりです。
- コンテキストが長すぎて入りきらない
- 重要な情報が長文に埋もれて、検索しにくい
- ノイズが多く、検索品質が落ちる
つまり、文書処理は実は次の作業をしています。
資料を、モデルが見つけやすく、使いやすい知識ブロックに整えること。
二、文書処理のよくある 4 ステップ
Section titled “二、文書処理のよくある 4 ステップ”クリーニング
Section titled “クリーニング”不要なノイズを取り除きます。たとえば:
- 余分な空白
- ページ番号
- 重複した見出し
分割(Chunking)
Section titled “分割(Chunking)”長文を、検索しやすい小さな断片に分けます。
メタデータ付与
Section titled “メタデータ付与”各ブロックに次のような情報を付けます。
- 元ファイル
- 見出し
- ページ番号
- タグ
テキストブロックを、類似度検索に使えるベクトルへ変換します。
三、なぜ分割がそんなに重要なのか?
Section titled “三、なぜ分割がそんなに重要なのか?”分割のサイズは、「勉強ノートを 1 枚のカードにどれくらい書くか」によく似ています。
- 大きすぎる: 一度に情報が多すぎて、検索が不正確になる
- 小さすぎる: 文脈が足りず、回答が途切れやすい
唯一の正解はありませんが、必ずタスクに合わせて調整する必要があります。
たとえるなら:
開いた試験のためのノートを作るとき、教科書 1 冊をそのまま超巨大ポスター 1 枚に貼りつけたり、逆に 1 文字ずつ紙切れに切り分けたりはしませんよね。

四、最小限で動く分割の例
Section titled “四、最小限で動く分割の例”import re
text = """返金ポリシー:コース購入後 7 日以内で、学習進捗が 20% 未満なら、返金を申請できます。7 日を過ぎると、無条件返金はできません。
証明書の説明:すべての必修項目を完了し、修了テストに合格すると、修了証を取得できます。
学習順序:まず Python、データ分析、機械学習を学び、その後に深層学習と大規模モデルの段階へ進むのがおすすめです。""".strip()
def split_into_sentences(text): parts = re.split(r"[。!?\\n]+", text) return [p.strip() for p in parts if p.strip()]
sentences = split_into_sentences(text)print("文のリスト:")for s in sentences: print("-", s)期待される出力:
文のリスト:- 返金ポリシー:- コース購入後 7 日以内で、学習進捗が 20% 未満なら、返金を申請できます- 7 日を過ぎると、無条件返金はできません- 証明書の説明:- すべての必修項目を完了し、修了テストに合格すると、修了証を取得できます- 学習順序:- まず Python、データ分析、機械学習を学び、その後に深層学習と大規模モデルの段階へ進むのがおすすめですもし文がすでにかなり短いなら、そのまま 1 文を 1 chunk として使えます。
ただし実際には、複数の文をまとめて 1 つのブロックにすることのほうが多いです。
五、重なり付きの分割
Section titled “五、重なり付きの分割”なぜ多くの RAG システムで chunk overlap を使うのでしょうか?
情報がちょうど chunk の境界にまたがることがあるからです。
少し重なりを持たせると、「文脈が切れる」確率を下げられます。
def chunk_sentences(sentences, chunk_size=2, overlap=1): if chunk_size - overlap <= 0: raise ValueError("chunk_size は overlap より大きくなければなりません")
chunks = [] start = 0 while start < len(sentences): end = start + chunk_size chunk = " ".join(sentences[start:end]) chunks.append(chunk) start += chunk_size - overlap return chunks
chunks = chunk_sentences(sentences, chunk_size=2, overlap=1)
print("分割結果:")for i, chunk in enumerate(chunks): print(f"[chunk {i}] {chunk}")期待される出力:
分割結果:[chunk 0] 返金ポリシー: コース購入後 7 日以内で、学習進捗が 20% 未満なら、返金を申請できます[chunk 1] コース購入後 7 日以内で、学習進捗が 20% 未満なら、返金を申請できます 7 日を過ぎると、無条件返金はできません[chunk 2] 7 日を過ぎると、無条件返金はできません 証明書の説明:[chunk 3] 証明書の説明: すべての必修項目を完了し、修了テストに合格すると、修了証を取得できます[chunk 4] すべての必修項目を完了し、修了テストに合格すると、修了証を取得できます 学習順序:[chunk 5] 学習順序: まず Python、データ分析、機械学習を学び、その後に深層学習と大規模モデルの段階へ進むのがおすすめです[chunk 6] まず Python、データ分析、機械学習を学び、その後に深層学習と大規模モデルの段階へ進むのがおすすめです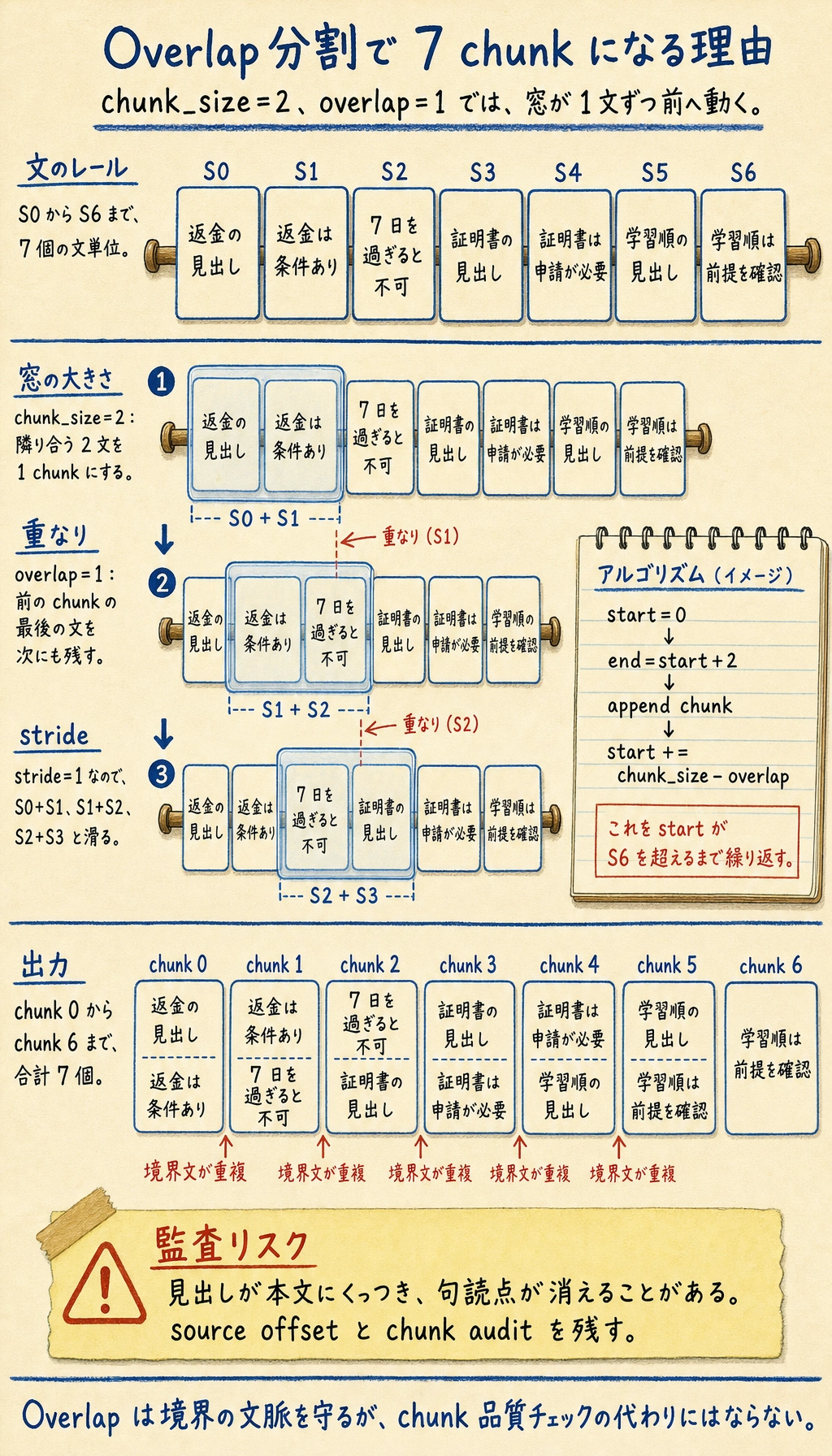
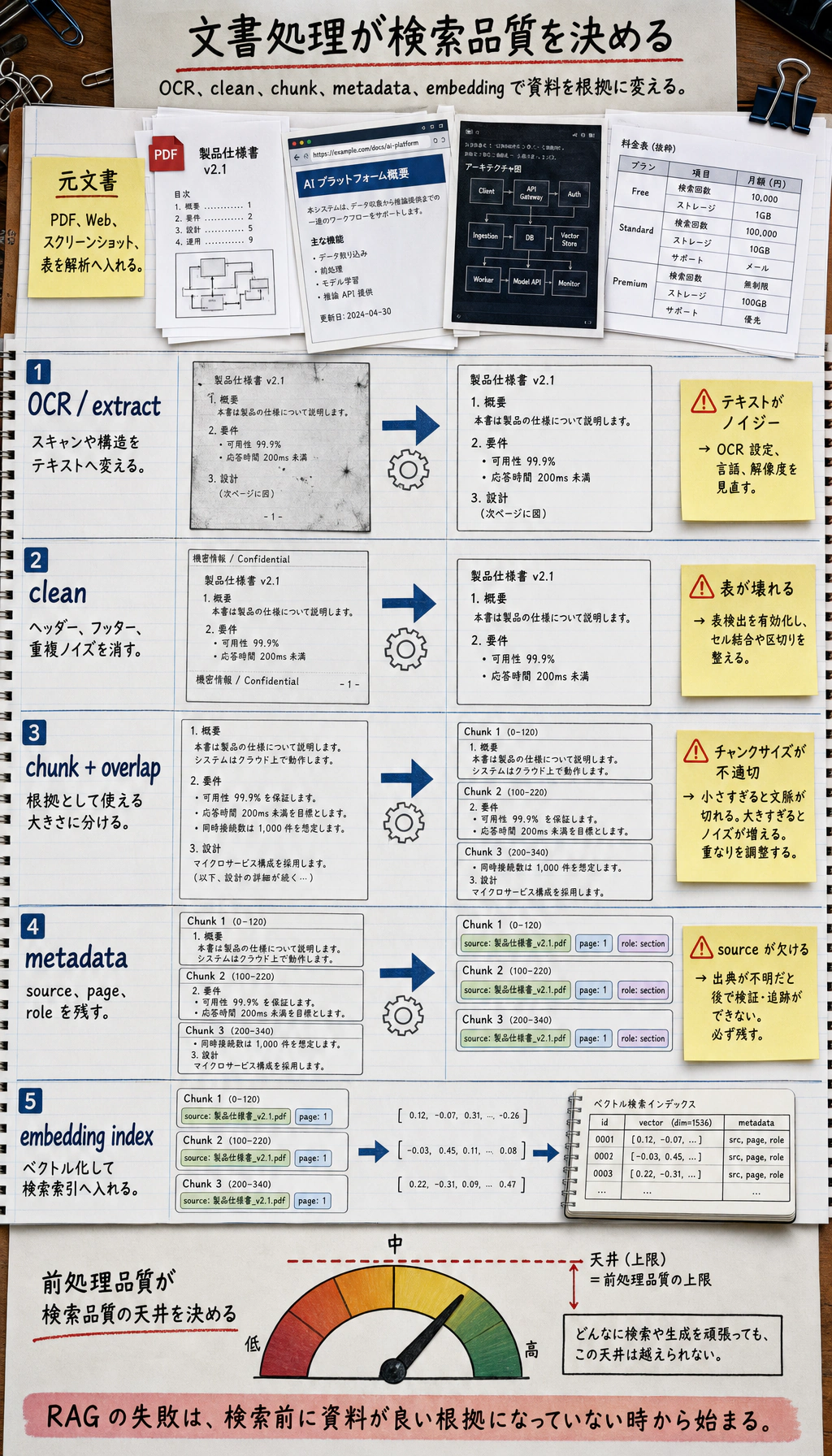
この出力は、素朴な分割の限界も見せています。見出しが本文にくっつき、句読点が消えることがあります。本番では source offset を残し、インデックス投入前に chunk audit を行います。
六、なぜメタデータが重要なのか?
Section titled “六、なぜメタデータが重要なのか?”初心者はテキスト内容ばかりに注目して、メタデータを見落としがちです。
でもメタデータは、検索結果と表示体験にそのまま影響します。
1 つの chunk には、よく次のようなメタデータがあります。
source: どのファイルから来たかsection: どの節に属するかpage: 何ページ目かtags: どんなテーマか
たとえば:
chunks_with_meta = [ { "text": "コース購入後 7 日以内で、学習進捗が 20% 未満なら、返金を申請できます", "source": "course_policy.pdf", "section": "返金ポリシー", "page": 3 }, { "text": "すべての必修項目を完了し、修了テストに合格すると、修了証を取得できます", "source": "course_policy.pdf", "section": "証明書の説明", "page": 5 }]
for item in chunks_with_meta: print(item)メタデータの価値は次のとおりです。
- フィルタリングしやすい
- 出典を示しやすい
- 後から UI に表示しやすい
七、目標が「知識ベース駆動の SOP 文書アシスタント」なら、分割はもう一段考える
Section titled “七、目標が「知識ベース駆動の SOP 文書アシスタント」なら、分割はもう一段考える”このタイプのプロジェクトは、普通の FAQ 質問応答と大きく違います。
- 単に「関連箇所を見つけたい」だけではない
- さらに資料を「ポリシー / 対応ケース / チェックリスト」に再構成したい
なので、最初に作るときは、分割を単なる長さだけで考えないでください。
「内容の種類」でも考える必要があります。
よくある安定したデフォルトの考え方は、次のとおりです。
| 内容タイプ | どう分けるのが向いているか |
|---|---|
| ポリシールール | 条件、対応、例外を同じブロックに残す |
| 対応ケース | 事象、判断、証拠、結果を同じブロックに残す |
| チェックリスト項目 | 1 つの運用確認を 1 ブロックにして、後で配置しやすくする |
| 手順サマリー | 見出しと重要ステップを残す |
この表が大事なのは、初心者に次のことを気づかせてくれるからです。
分割は固定のテキスト操作ではなく、その先の生成目的のためにある。
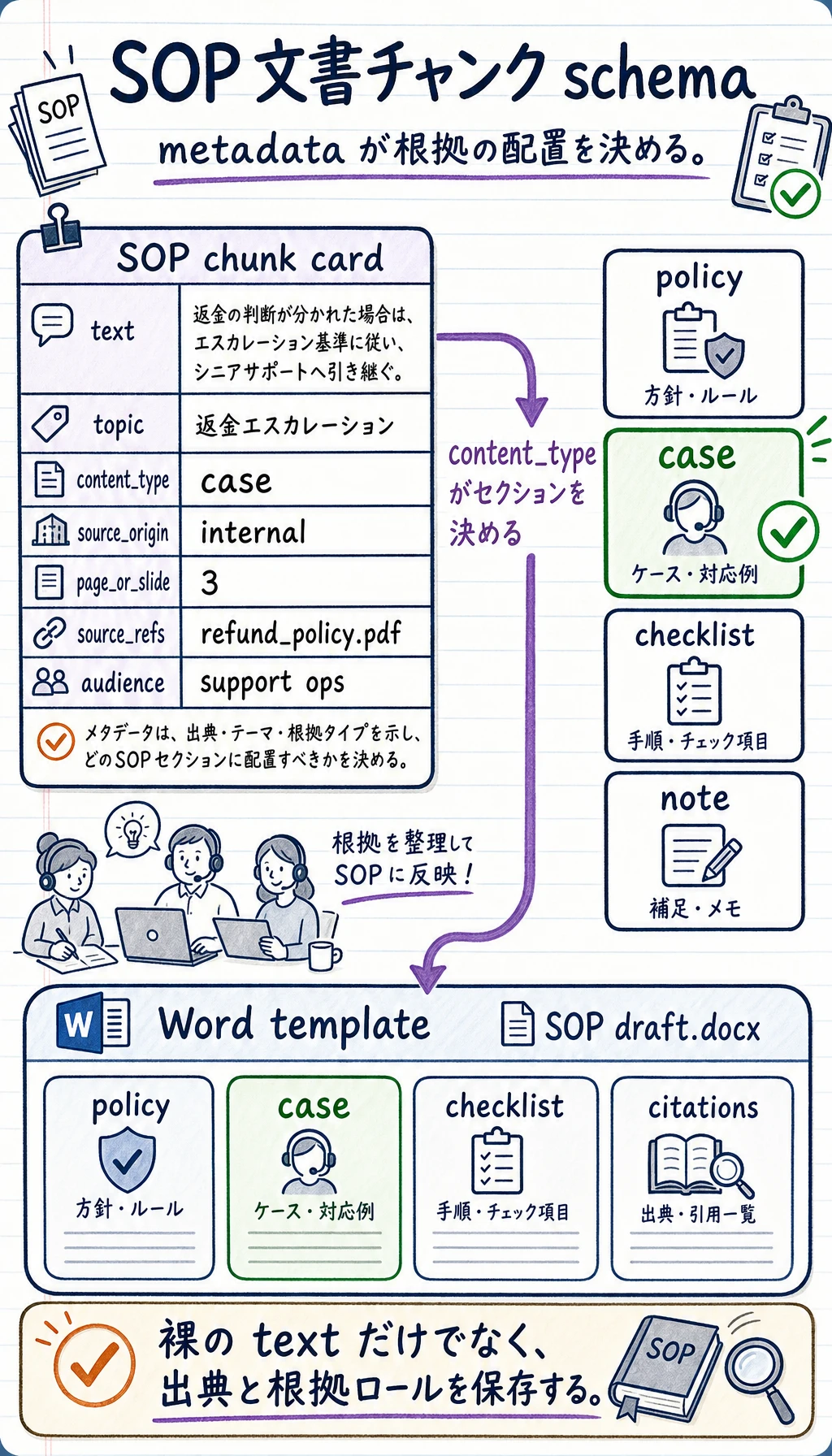
八、SOP 文書プロジェクトらしい知識ブロックの例
Section titled “八、SOP 文書プロジェクトらしい知識ブロックの例”sop_chunks = [ { "topic": "返金エスカレーション", "content_type": "policy", "section": "ポリシールール", "page": 1, "text": "重複請求の返金は、取引証拠を添えてエスカレーションする必要がある。", }, { "topic": "返金エスカレーション", "content_type": "case", "section": "対応ケース", "page": 2, "text": "決済失敗後に顧客へ 2 回請求されたため、サポートが両方の請求を確認して billing にエスカレーションした。", }, { "topic": "返金エスカレーション", "content_type": "checklist", "section": "確認チェックリスト", "page": 3, "text": "取引 ID、決済プロバイダの状態、返金期限、エスカレーション担当者を確認する。", },]
for item in sop_chunks: print(item["content_type"], "->", item["text"])この例で初心者が特に注目すべき点は次のとおりです。
- 同じテーマでも、知識ブロックはポリシー、対応ケース、チェックリストに分けるのがよい
- そうすると、後で Word SOP を生成するときに、どの内容をどの欄に入れるべきかシステムが判断しやすい
九、ベクトル化は実際には何をしているのか?
Section titled “九、ベクトル化は実際には何をしているのか?”ベクトル化の核心は、テキストブロックを「意味空間」に写すことです。
そうすると、クエリも文書ブロックもベクトルになり、あとは類似度を比べられます。
コードがそのまま動くように、まずは超簡単な単語袋ベクトルでこの流れを真似してみましょう。
import mathimport refrom collections import Counter
chunks = [ "コース購入後 7 日以内で、学習進捗が 20% 未満なら、返金を申請できます", "すべての必修項目を完了し、修了テストに合格すると、修了証を取得できます", "まず Python、データ分析、機械学習を学び、その後に深層学習と大規模モデルの段階へ進むのがおすすめです"]
def tokenize(text): words = re.findall(r"[a-zA-Z0-9_]+", text.lower()) cjk_chars = re.findall(r"[\u4e00-\u9fff\u3040-\u30ff]", text) cjk_bigrams = ["".join(cjk_chars[i:i + 2]) for i in range(len(cjk_chars) - 1)] return words + cjk_bigrams
vocab = sorted(set(token for chunk in chunks for token in tokenize(chunk)))vocab_index = {word: idx for idx, word in enumerate(vocab)}
def vectorize(text): vec = [0] * len(vocab) counts = Counter(tokenize(text)) for word, count in counts.items(): if word in vocab_index: vec[vocab_index[word]] = count return vec
def cosine_similarity(a, b): dot = sum(x * y for x, y in zip(a, b)) norm_a = math.sqrt(sum(x * x for x in a)) norm_b = math.sqrt(sum(y * y for y in b)) if norm_a == 0 or norm_b == 0: return 0.0 return dot / (norm_a * norm_b)
query = "返金を申請するにはどうすればいいですか"query_vec = vectorize(query)
scores = []for chunk in chunks: score = cosine_similarity(query_vec, vectorize(chunk)) scores.append((score, chunk))
scores.sort(reverse=True)for score, chunk in scores: print(round(score, 4), "->", chunk)期待される出力:
0.3032 -> コース購入後 7 日以内で、学習進捗が 20% 未満なら、返金を申請できます0.07 -> すべての必修項目を完了し、修了テストに合格すると、修了証を取得できます0.0609 -> まず Python、データ分析、機械学習を学び、その後に深層学習と大規模モデルの段階へ進むのがおすすめですこれが、最小限の「検索」の原理です。
十、実際のプロジェクトでは、もっと複雑になる
Section titled “十、実際のプロジェクトでは、もっと複雑になる”本当の RAG システムでは、ベクトル化に単純な単語頻度ではなく、専用の embedding モデルを使うのが一般的です。
でも考え方は同じです。
- クエリをベクトルにする
- 文書ブロックをベクトルにする
- ベクトル空間で最も近いブロックを探す
なので、「ベクトルデータベース」という言葉におびえる必要はありません。
本質はあくまで類似度検索で、違いは規模が大きく、効率が高いことです。
十一、文書処理で最も失敗しやすいポイント
Section titled “十一、文書処理で最も失敗しやすいポイント”chunk が大きすぎる
Section titled “chunk が大きすぎる”再現率が下がり、コンテキストを無駄にします。
chunk が小さすぎる
Section titled “chunk が小さすぎる”情報が不完全になり、モデルが見る断片がバラバラになります。
クリーニングしすぎる
Section titled “クリーニングしすぎる”見出し、階層、表の構造など、価値のある情報まで消してしまいます。
メタデータがない
Section titled “メタデータがない”後から「答えはどこから来たのか」を説明しにくくなります。
長さだけで分割し、タスクに合わせて分けていない
Section titled “長さだけで分割し、タスクに合わせて分けていない”SOP 文書生成プロジェクトでは、これにより次の問題が起こります。
- ケースと判断証拠が分断される
- ポリシーとチェックリストが混ざる
- 後で決まった形式の文書に安定して組み立てにくくなる
文書処理の確認表
Section titled “文書処理の確認表”文書処理が終わったら、「chunk が何個できたか」だけでなく、その chunk が後続の質問応答を本当に支えられるかを確認してください。
| 確認項目 | 合格の状態 | よくある問題 |
|---|---|---|
| テキストのクリーニング | ヘッダー、フッター、重複空白、意味のないノイズを除去できている | クリーニングしすぎて、見出しや表の構造まで消えている |
| chunk の完全性 | 1 つの chunk で、1 つの事実または 1 つの手順を完結して表せる | 重要な条件が隣の chunk に切れている |
| chunk の粒度 | 正確に再現でき、かつ細かすぎない | 大きすぎて検索が不正確、小さすぎて証拠が不完全 |
| メタデータ | source、section、page、topic、content_type が残っている | 答えの出典を示せない、テーマで絞り込めない |
| サンプル確認 | ランダムに 10 個ほど chunk を目視で確認する | 数だけ見て、品質を見ない |
いちばん実用的なのは、まず「chunk 抜き取り確認表」を作ることです。分割ルールを変えるたびに、chunk をランダムに数件抽出し、検索・引用・表示に向いているかを確認しましょう。
chunk 品質の抽出確認スクリプト
Section titled “chunk 品質の抽出確認スクリプト”次のスクリプトは外部ライブラリに依存せず、確認の習慣をつけるためのものです。実際のプロジェクトでは、確認結果を CSV や Markdown に書き出してもよいでしょう。
chunks_with_meta = [ { "id": "policy_001_01", "text": "コース購入後 7 日以内で、学習進捗が 20% 未満なら、返金を申請できます", "source": "course_policy.pdf", "section": "返金ポリシー", "page": 3, "content_type": "policy", }, { "id": "policy_001_02", "text": "すべての必修項目を完了し、修了テストに合格すると、修了証を取得できます", "source": "course_policy.pdf", "section": "証明書の説明", "page": 5, "content_type": "rule", },]
required_fields = {"id", "text", "source", "section", "page", "content_type"}
for chunk in chunks_with_meta: missing = required_fields - set(chunk) too_short = len(chunk["text"]) < 10 too_long = len(chunk["text"]) > 300 print({ "id": chunk.get("id"), "missing_fields": sorted(missing), "too_short": too_short, "too_long": too_long, "preview": chunk["text"][:40], })期待される出力:
{'id': 'policy_001_01', 'missing_fields': [], 'too_short': False, 'too_long': False, 'preview': 'コース購入後 7 日以内で、学習進捗が 20% 未満なら、返金を申請できます'}{'id': 'policy_001_02', 'missing_fields': [], 'too_short': False, 'too_long': False, 'preview': 'すべての必修項目を完了し、修了テストに合格すると、修了証を取得できます'}このスクリプトは意味の品質までは判断してくれませんが、まず次のような基本問題を見つけるのに役立ちます。
- フィールド不足
- chunk が短すぎる
- chunk が長すぎる
- 出典を追跡できない
分割戦略の比較記録
Section titled “分割戦略の比較記録”新しい分割戦略を試すたびに、結果を同じ形式で記録するのがおすすめです。
- 文ごとに分ける: 1 文 1 chunk。シンプルで検索精度は高いですが、証拠が不完全になりやすいので、短い FAQ にだけ向きます。
- スライディングウィンドウ: 2-4 文、overlap 1。文脈が切れにくい一方で、chunk 数は増えます。baseline に向きます。
- 見出し階層で分ける: H2/H3 配下を 1 ブロックにします。構造を残せますが、長い章は大きくなりがちです。手順書や文書に向きます。
- 内容タイプで分ける: ポリシー、ケース、チェックリストを分けます。SOP 文書生成に向きますが、解析やラベル付けが必要です。構造化プロジェクトに向きます。
どこから始めればいいか迷ったら、まず「見出し階層 + スライディングウィンドウ」を baseline にして、評価用データセットに合わせて調整するのがおすすめです。
このページを終えたら、この証拠カードを残します。
- クエリ
- 1つのユーザー質問またはテストケース
- 検索チャンク
- chunk id、スコア、ソースタイトル
- 回答
- 引用または出典メモ付きの最終回答
- 失敗確認
- 証拠不足、誤ったチャンク、古い文書、または裏付けのない主張
- 次の行動
- chunking、embedding、reranking、prompt、または eval の変更
この節でいちばん大事なのは次の理解です。
RAG の前処理は脇役ではなく、効果の上限を決める重要な要素である。
検索がうまくいかなければ、生成が安定することはほとんどありません。
だからこそ、文書クリーニング、分割、メタデータ、ベクトル化は、どれも丁寧に設計する必要があります。
chunk_sizeとoverlapを調整して、分割結果がどう変わるか観察してみましょう。chunksに、返金とはまったく関係のない文を 1 つ追加して、検索スコアの並びをもう一度見てみましょう。- 考えてみましょう。1 つの規約が 2 つの段落にまたがる場合、どのように chunk を設計すれば、重要な情報を切り断ちにくいでしょうか?
- あなたの目標が SOP 文書生成なら、ポリシー、対応ケース、チェックリストを同じ分割方法でまとめてしまうのがなぜ向かないのか、考えてみましょう。
参考実装と解説
- 小さい chunk は精密に検索しやすい一方で、文脈を失いやすいです。大きい chunk は文脈を保ちますが、信号が薄まりやすくなります。Overlap は境界情報の欠落を減らします。
- 返金と無関係な文は、返金質問では低く並ぶべきです。高く出るなら、embedding や scoring が意図を十分に区別できていません。
- まず意味の境界で分け、そのうえで overlap や parent-child chunks を使うとよいです。各検索単位が、回答を支えるだけの情報を含むことが目標です。
- ポリシーは条件と例外が重要で、ケースは証拠と結果が必要で、チェックリストは明確な操作確認が必要です。全部同じ chunking にすると、判断証拠を切りすぎたり、ポリシー検索がノイズだらけになったりします。