11.6.6 Transformers ライブラリ実践
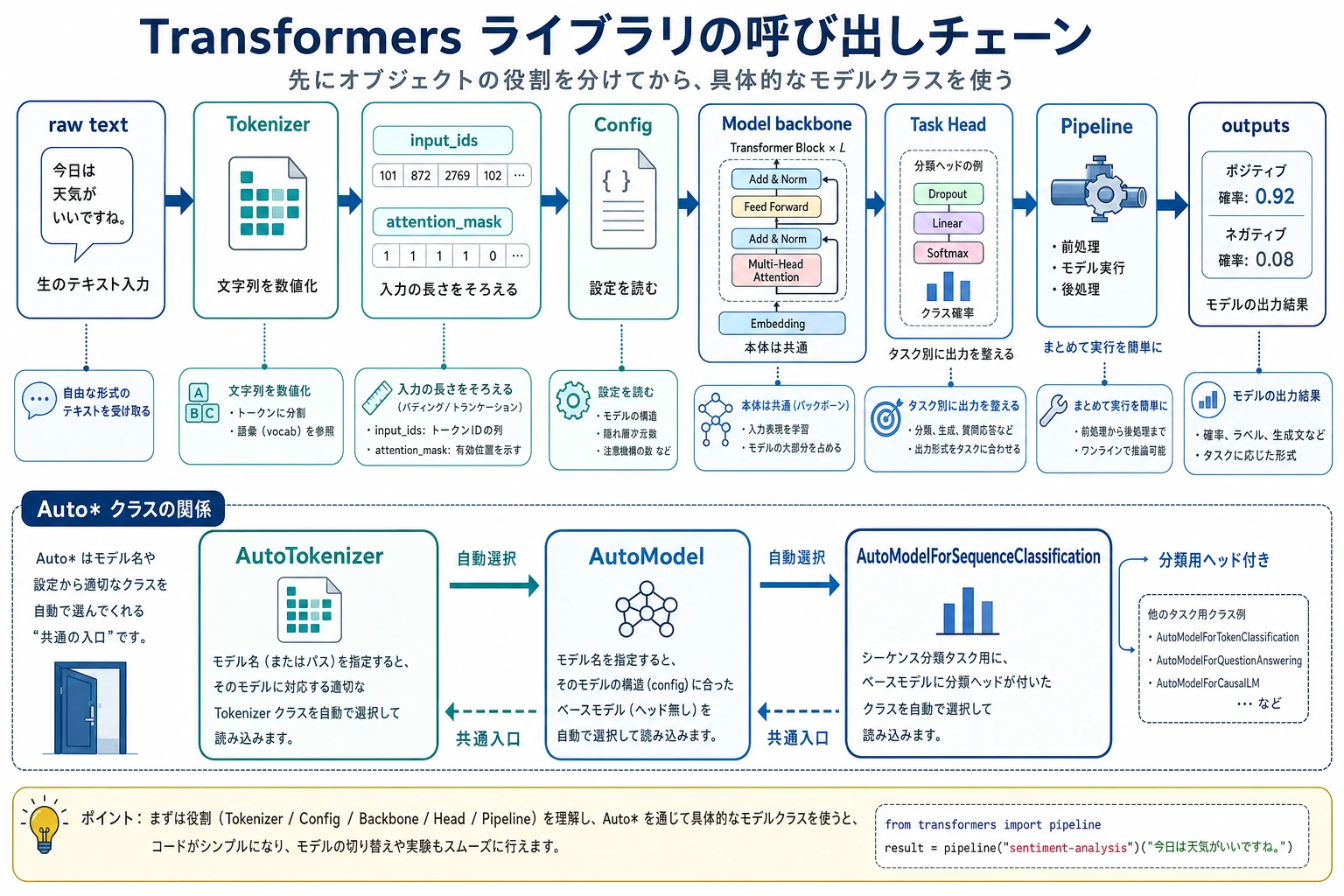
transformersライブラリでよく使う主要オブジェクトの役割を理解する- tokenizer、config、model、pipeline の違いを区別できるようになる
- オフラインで tokenizer + model の最小サンプルを動かす
- 実際のプロジェクトで「動く」から「保守しやすい」へ進む考え方を理解する
一、まずはライブラリの主役たちを整理しよう
Section titled “一、まずはライブラリの主役たちを整理しよう”Tokenizer
Section titled “Tokenizer”テキストを、モデルが扱える数値列に変換する役割です。
Config
Section titled “Config”モデルの構造パラメータを記述します。たとえば:
- hidden size
- 層数
- ヘッド数
実際に前向き計算を行う本体です。
Pipeline
Section titled “Pipeline”より高レベルのラッパーで、次の処理をひとまとめにしてくれます。
- 分かち書き
- 前向き計算
- 後処理
より簡単に呼び出せるインターフェースにしてくれます。
一言で覚えるなら:
tokenizer は入口を担当し、model は計算を担当し、pipeline は全体をつなげる役割です。
二、なぜ多くの人は最初に transformers を使うと混乱するのか?
Section titled “二、なぜ多くの人は最初に transformers を使うと混乱するのか?”理由は、このライブラリに二つの見方があるからです。
たとえば、あなたは次のようなことを知っています。
- BERT は encoder-only
- GPT は decoder-only
ツールの世界
Section titled “ツールの世界”一方で、次のようなものにも出会います。
AutoTokenizerAutoModelAutoModelForSequenceClassificationpipelinefrom_pretrained
初学者がよくつまずくのは、
名前はたくさんあるのに、それぞれが何を解決するのか分からない。
という点です。
なので、この節の核心はインターフェースを暗記することではなく、呼び出し順序の地図を作ることです。
三、まずはオフラインで最小の tokenizer を作る
Section titled “三、まずはオフラインで最小の tokenizer を作る”なぜ既製モデルをそのままダウンロードしないのか?
Section titled “なぜ既製モデルをそのままダウンロードしないのか?”教材では、外部ネットワークがなくても動くようにしておくことが大切だからです。
そこでここでは、手作業でとても小さな vocab.txt を用意して、tokenizer が何をしているのかを本当に理解できるようにします。
実行可能なサンプル
Section titled “実行可能なサンプル”from pathlib import Pathfrom tempfile import TemporaryDirectoryfrom transformers import BertTokenizer
vocab_tokens = [ "[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]", "我", "愛", "自", "然", "語", "言", "処", "理", "北", "京"]
with TemporaryDirectory() as tmpdir: vocab_path = Path(tmpdir) / "vocab.txt" vocab_path.write_text("\n".join(vocab_tokens), encoding="utf-8")
tokenizer = BertTokenizer.from_pretrained(tmpdir)
encoded = tokenizer("我愛自然言語処理", return_tensors="pt")
print(encoded) print("tokens:", tokenizer.convert_ids_to_tokens(encoded["input_ids"][0]))想定出力:
{'input_ids': tensor([[ 2, 5, 6, 7, 8, 10, 9, 11, 12, 3]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}tokens: ['[CLS]', '我', '愛', '自', '然', '言', '語', '処', '理', '[SEP]']一時ディレクトリを使うので、練習後にプロジェクト直下へ vocab.txt が残りません。input_ids は token 番号で、attention_mask は有効な位置を示します。
このコードで学ぶこと
Section titled “このコードで学ぶこと”このコードが教えているのは、次のことです。
- tokenizer は魔法のブラックボックスではない
- 本質は「語彙 + 分割ルール + エンコードルール」
- 出力で特に重要なのは
input_idsとattention_mask
四、次に最小の BERT モデルをオフラインで作る
Section titled “四、次に最小の BERT モデルをオフラインで作る”なぜランダム初期化のモデルを使うのか?
Section titled “なぜランダム初期化のモデルを使うのか?”今の目的は精度を追うことではなく、
transformersライブラリの model オブジェクトが、入力をどう受け取り、出力をどう返すのかをきちんと理解すること
だからです。
実行可能なサンプル
Section titled “実行可能なサンプル”import torchfrom transformers import BertConfig, BertModel
config = BertConfig( vocab_size=15, hidden_size=32, num_hidden_layers=2, num_attention_heads=4, intermediate_size=64)
model = BertModel(config)
input_ids = torch.tensor([[2, 5, 6, 7, 8, 9, 10, 11, 12, 3]])attention_mask = torch.ones_like(input_ids)
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
print("last_hidden_state shape:", outputs.last_hidden_state.shape)print("pooler_output shape :", outputs.pooler_output.shape)想定出力:
last_hidden_state shape: torch.Size([1, 10, 32])pooler_output shape : torch.Size([1, 32])このランダムモデルは、精度ではなくインターフェースを学ぶためのものです。最初の shape は、1 件のサンプル、10 個の token 位置、各位置 32 次元の隠れ表現を意味します。
本当に理解すべきポイント
Section titled “本当に理解すべきポイント”input_idsは token の番号attention_maskはどの位置が有効かをモデルに伝えるlast_hidden_stateは各位置の文脈化された表現pooler_outputは文全体の表現の一種に近いもの
このあたりを理解しておくと、後で分類 head、マッチング head、生成 head をつなぐときにぐっと楽になります。
五、tokenizer と model をつないでみる
Section titled “五、tokenizer と model をつないでみる”実行可能なサンプル
Section titled “実行可能なサンプル”from pathlib import Pathfrom tempfile import TemporaryDirectoryimport torchfrom transformers import BertTokenizer, BertConfig, BertModel
vocab_tokens = [ "[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]", "我", "愛", "自", "然", "語", "言", "処", "理"]
with TemporaryDirectory() as tmpdir: vocab_path = Path(tmpdir) / "vocab.txt" vocab_path.write_text("\n".join(vocab_tokens), encoding="utf-8")
tokenizer = BertTokenizer.from_pretrained(tmpdir)
config = BertConfig( vocab_size=len(vocab_tokens), hidden_size=32, num_hidden_layers=2, num_attention_heads=4, intermediate_size=64 ) model = BertModel(config)
batch = tokenizer(["我愛自然言語処理", "我愛言語"], padding=True, return_tensors="pt") outputs = model(**batch)
print("input_ids shape :", batch["input_ids"].shape) print("attention_mask shape :", batch["attention_mask"].shape) print("last_hidden_state shape:", outputs.last_hidden_state.shape)想定出力:
input_ids shape : torch.Size([2, 10])attention_mask shape : torch.Size([2, 10])last_hidden_state shape: torch.Size([2, 10, 32])tokenizer は短い文を長い文と同じ長さまで padding します。そのため、batch はきれいな長方形の tensor になります。
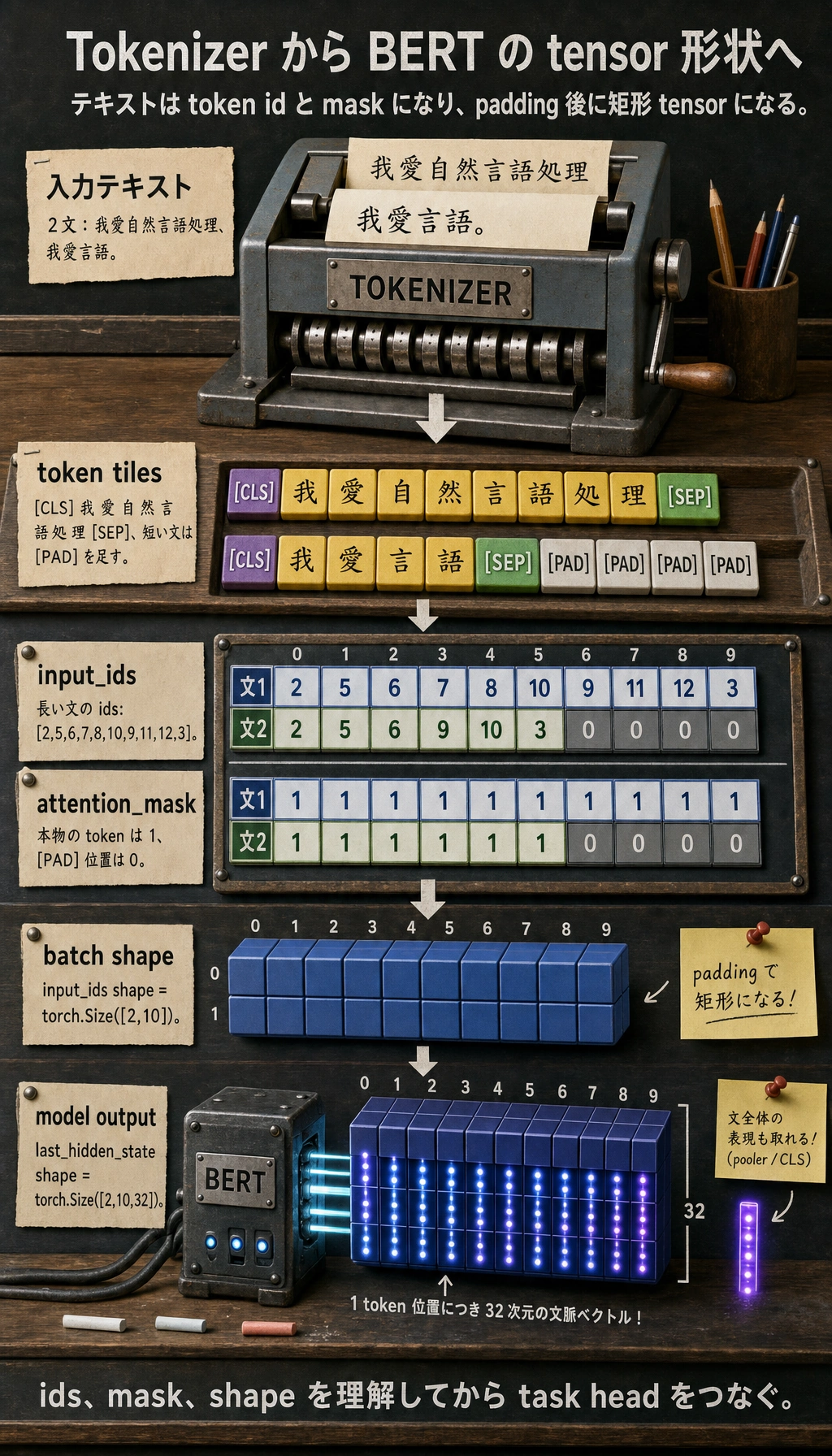
これが基本の本当の呼び出しチェーン
Section titled “これが基本の本当の呼び出しチェーン”実際のプロジェクトで最もよくある基本フローは、だいたい次の通りです。
- テキスト -> tokenizer
- tokenizer -> tensor
- tensor -> model
- model の出力 -> 後処理または task head
ここまでで、このチェーンはすでに自分で動かせるようになりました。
六、Auto* 系インターフェースは何のためにあるのか?
Section titled “六、Auto* 系インターフェースは何のためにあるのか?”なぜライブラリには AutoModel がたくさんあるのか?
Section titled “なぜライブラリには AutoModel がたくさんあるのか?”transformers は、あなたがたくさんのモデル型を手書きで判定しなくて済むように設計されています。
たとえば:
AutoTokenizerAutoModelAutoModelForSequenceClassificationAutoModelForCausalLM
これらの設計目標は、
モデル名や config を与えれば、適切なクラスを自動で選ぶ
ということです。
オフラインの AutoModel.from_config の例
Section titled “オフラインの AutoModel.from_config の例”from transformers import AutoModel, BertConfig
config = BertConfig( vocab_size=20, hidden_size=16, num_hidden_layers=1, num_attention_heads=4, intermediate_size=32)
model = AutoModel.from_config(config)print(type(model))想定出力:
<class 'transformers.models.bert.modeling_bert.BertModel'>AutoModel は BERT の config を読み取り、それに合う BERT モデルクラスを自動で作ります。実際の事前学習済み checkpoint を名前で読み込むときも、考え方は同じです。
これが示しているのは次の点です。
AutoModelは必ずしもネットワークからのダウンロードが必要ではない- 本質は「config に基づいて正しいモデルを自動生成する」こと
七、pipeline は学ぶ価値があるのか?
Section titled “七、pipeline は学ぶ価値があるのか?”価値はある。ただし、使いどころを知ることが大事
Section titled “価値はある。ただし、使いどころを知ることが大事”pipeline の良い点:
- すぐに使える
- デモを素早く作れる
- 定型コードを減らせる
特に向いているのは:
- 学習
- すばやい検証
- 小さな実験
ただし、実務では pipeline だけに頼れない
Section titled “ただし、実務では pipeline だけに頼れない”実際のプロジェクトでは、次のような制御も必要になることが多いです。
- batch
- device
- 出力形式
- ログ
- エラー処理
だから、成熟したやり方としては通常、
- まず
pipelineを使えるようになる - 同時に、下層の tokenizer + model の呼び出しチェーンも理解する
という流れになります。
八、Transformers ライブラリでよく使う task head
Section titled “八、Transformers ライブラリでよく使う task head”よく使うものをざっくり覚えておきましょう。
| インターフェース | 向いている用途 |
|---|---|
AutoModel | 基本表現だけ取り出す |
AutoModelForSequenceClassification | テキスト分類 |
AutoModelForTokenClassification | シーケンスラベリング |
AutoModelForQuestionAnswering | 抽出型質問応答 |
AutoModelForCausalLM | 生成タスク |
裏側の考え方はとてもシンプルです。
同じ backbone モデル + 異なる task head。
九、初学者がよくハマる落とし穴
Section titled “九、初学者がよくハマる落とし穴”pipeline しか使えず、下層の呼び出しが分からない
Section titled “pipeline しか使えず、下層の呼び出しが分からない”これだと、実務の場面で止まりやすくなります。
tokenizer の出力フィールドを理解していない
Section titled “tokenizer の出力フィールドを理解していない”最低でも次は読めるようにしておきましょう。
input_idsattention_mask
「モデルの概念」と「ライブラリのインターフェース」を混同する
Section titled “「モデルの概念」と「ライブラリのインターフェース」を混同する”次の違いを分けて考えられるようにしましょう。
- BERT / GPT はモデルの系統
AutoModel/pipelineはライブラリのインターフェース
このページを終えたら、この evidence card を残します。
- モデル選択
- BERT、GPT、T5、Transformers のパイプライン、または他の事前学習ベースライン
- tokenizer 出力
- ids、masks、デコード済みテキスト、またはバッチ形状
- タスク結果
- classification、generation、extraction、または text-to-text 出力
- 失敗確認
- 間違ったモデルファミリー、トークン上限、ドメイン不一致、コスト、またはレイテンシ
- 期待される成果
- モデル呼び出し結果と短い選択理由
この節で最も大切なのは、API を暗記できるかどうかではありません。大事なのは、次のことをはっきりさせることです。
Transformers ライブラリの核心的な呼び出しチェーンは、tokenizer がテキストを tensor にエンコードし、model が tensor に対して前向き計算を行い、最後に task head または後処理で結果を得る、という流れである。
この流れが分かれば、その後に分類、抽出、生成、あるいは fine-tuning を行うときも、考え方がかなり安定します。
- この節の mini vocab を変更して、自分の単語をいくつか追加し、tokenizer の出力がどう変わるか見てみましょう。
BertConfigのhidden_sizeを 64 に変えて、出力 shape がどう変わるか確認してみましょう。- 自分の言葉で説明してみましょう:なぜ
transformersライブラリを学ぶとき、pipelineだけでは不十分なのでしょうか? - 考えてみましょう:テキスト分類をしたい場合、まず探すべきなのは
AutoModelでしょうか、それともAutoModelForSequenceClassificationでしょうか?
参考実装と解説
- mini vocab を変えると token IDs が変わります。vocabulary に語がない場合は unknown token が出ることもあります。
hidden_sizeを 64 にすると hidden representation の次元が変わります。sequence length や batch size が変わるわけではありません。pipelineは便利ですが、実プロジェクトを debug するには tokenizer、config、model class、tensor、label、evaluation も理解する必要があります。- text classification では、分類 head が必要なら
AutoModelForSequenceClassificationから始めます。head を自作するならAutoModelを使います。