6.6.3 VAE 基礎 [任意]
- encoder、
mu、logvar、latent samplez、decoder を説明できる。 - VAE が reparameterization を使う理由を理解する。
- 2D point で小さな PyTorch VAE を動かせる。
- reconstruction loss と KL regularization を読める。
- VAE、通常の autoencoder、GAN を比較できる。
まず流れを見る
Section titled “まず流れを見る”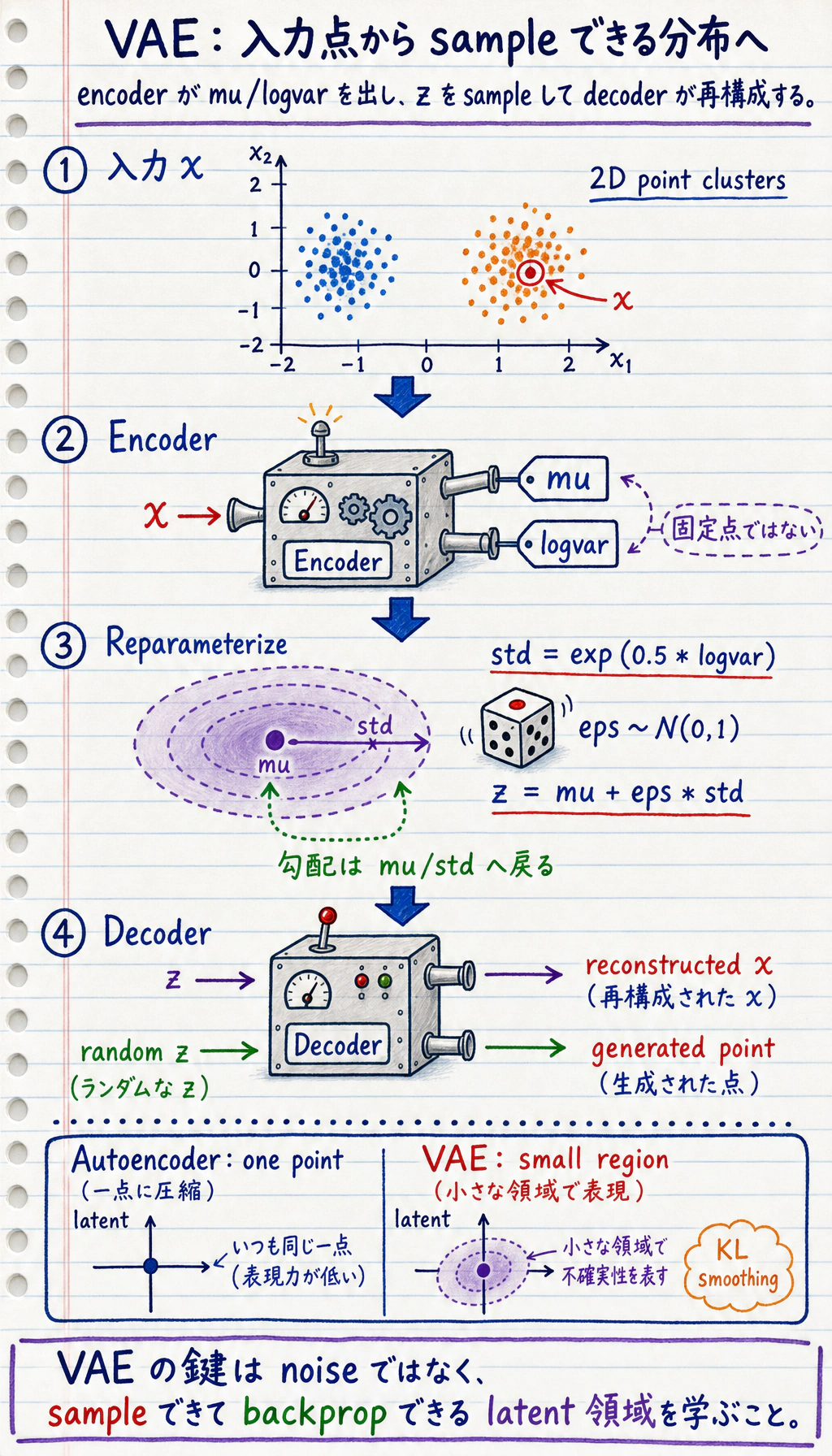
| 手順 | 何が起こるか | 実践的な意味 |
|---|---|---|
| Encode | x -> mu, logvar | latent の領域を表す |
| Sample | z = mu + eps * std | sampling を微分可能にする |
| Decode | z -> reconstructed x | latent code をデータに戻す |
| Regularize | KL 項 | latent space を滑らかで sample しやすくする |
通常の autoencoder との違い:
Autoencoder: x -> 1 つの latent 点 -> reconstructionVAE: x -> latent distribution -> sample z -> reconstruction または generation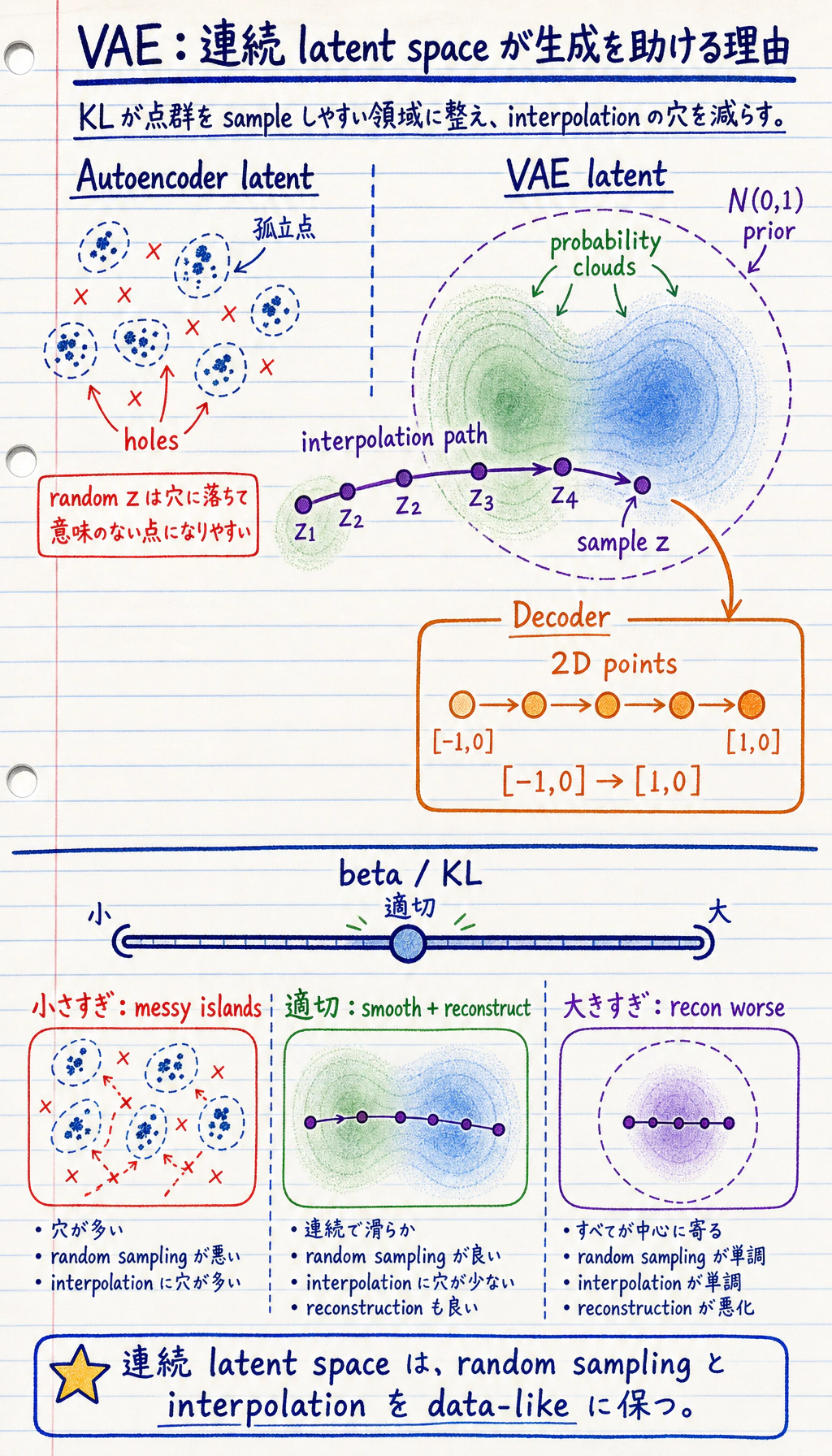
Reparameterization が必要な理由
Section titled “Reparameterization が必要な理由”sampling にはランダム性があります。ランダム sampling をそのまま使うと、通常の backpropagation が通りにくくなります。VAE は sampling を次の形に書き換えます。
std = exp(0.5 * logvar)eps ~ N(0, 1)z = mu + eps * stdこれで勾配は mu と std を通って戻れます。eps はランダム性を与える役目です。
VAE Loss
Section titled “VAE Loss”VAE の訓練では、ふつう 2 つの目標を合わせます。
loss = reconstruction_loss + beta * KL(q(z|x) || p(z))自然な言葉で読むと:
- reconstruction loss:decoder は入力を再構成できるか。
- KL 項:latent space は N(0, 1) のような滑らかな prior に近いか。
beta:latent space をどれくらい強く整えるか。
KL の圧力が弱すぎると latent space が乱れやすくなります。強すぎると reconstruction が悪くなったり、latent variable がほとんど情報を持たなくなったりします。
実験:2D Point で小さな VAE を訓練する
Section titled “実験:2D Point で小さな VAE を訓練する”これは画像 VAE ではありません。VAE の仕組み全体を見える形で動かすための小さな実験です。
tiny_vae_2d.py を作成します。
import torchfrom torch import nn
torch.manual_seed(4)
cluster_a = torch.randn(128, 2) * 0.15 + torch.tensor([1.0, 0.0])cluster_b = torch.randn(128, 2) * 0.15 + torch.tensor([-1.0, 0.0])x = torch.cat([cluster_a, cluster_b], dim=0)
class TinyVAE(nn.Module): def __init__(self): super().__init__() self.encoder = nn.Sequential(nn.Linear(2, 16), nn.ReLU()) self.mu = nn.Linear(16, 2) self.logvar = nn.Linear(16, 2) self.decoder = nn.Sequential(nn.Linear(2, 16), nn.ReLU(), nn.Linear(16, 2))
def reparameterize(self, mu, logvar): std = torch.exp(0.5 * logvar) eps = torch.randn_like(std) return mu + eps * std
def forward(self, x): h = self.encoder(x) mu = self.mu(h) logvar = self.logvar(h) z = self.reparameterize(mu, logvar) recon = self.decoder(z) return recon, mu, logvar
model = TinyVAE()opt = torch.optim.Adam(model.parameters(), lr=0.02)
for epoch in range(1, 201): recon, mu, logvar = model(x) recon_loss = ((recon - x) ** 2).mean() kl = -0.5 * torch.mean(1 + logvar - mu.pow(2) - logvar.exp()) loss = recon_loss + 0.05 * kl
opt.zero_grad() loss.backward() opt.step()
if epoch in [1, 50, 100, 200]: print( f"epoch={epoch:03d} " f"recon={recon_loss.item():.4f} " f"kl={kl.item():.4f} " f"loss={loss.item():.4f}" )
with torch.no_grad(): z = torch.randn(5, 2) samples = model.decoder(z) rounded = [[round(v, 3) for v in row.tolist()] for row in samples] print("generated_points") print(rounded)実行します。
python tiny_vae_2d.py期待される出力:
epoch=001 recon=0.5903 kl=0.0293 loss=0.5917epoch=050 recon=0.0335 kl=0.9007 loss=0.0785epoch=100 recon=0.0261 kl=0.8229 loss=0.0673epoch=200 recon=0.0244 kl=0.7138 loss=0.0601generated_points[[1.075, -0.014], [-0.997, -0.001], [-1.118, -0.054], [0.553, 0.041], [0.74, 0.021]]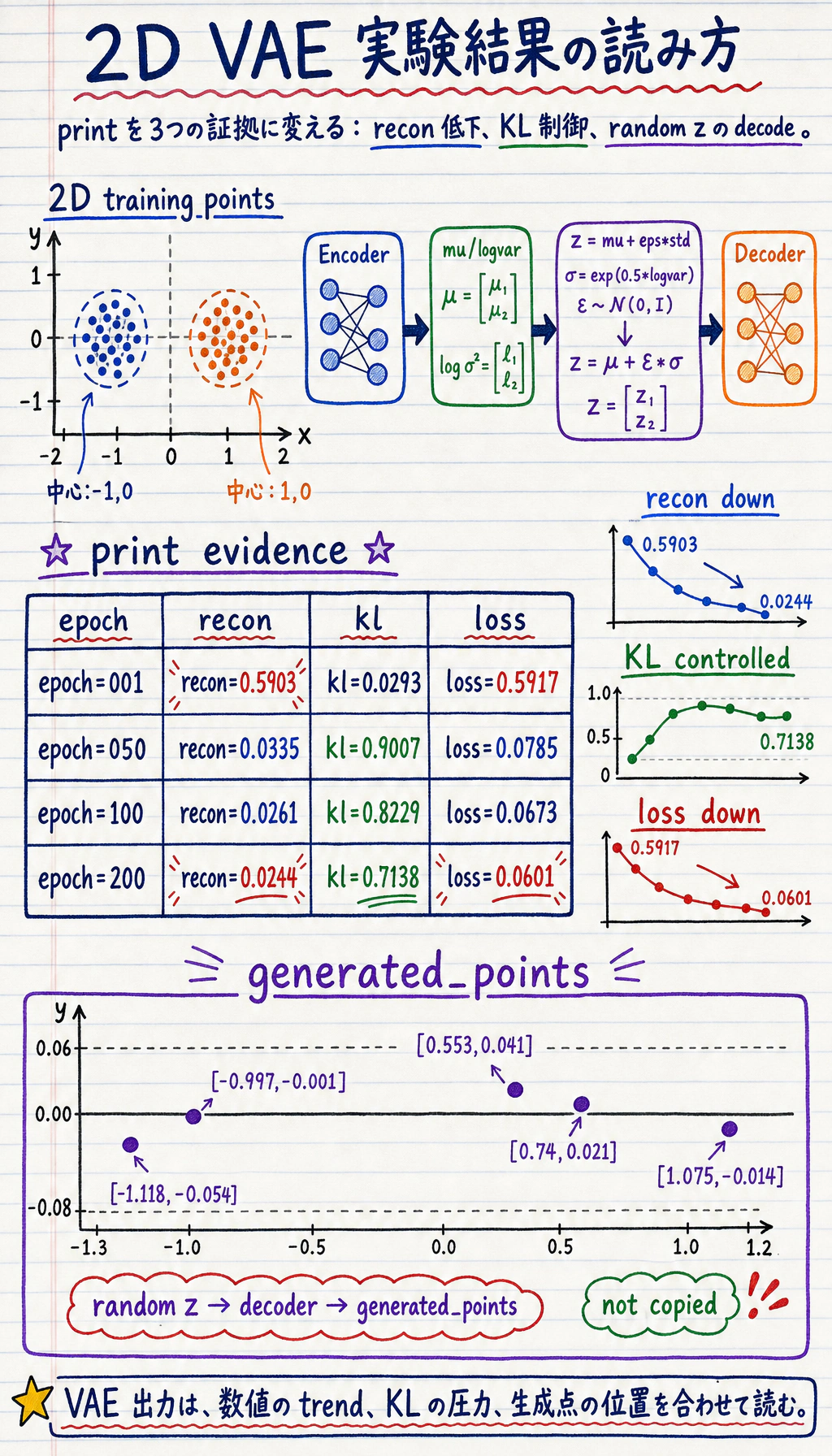
出力の読み方:
reconが下がるのは、decoder が 2D point を再構成できるようになっているからです。klは 0 になる必要はありません。latent space を滑らかな prior に近づける圧力です。generated_pointsはランダムなzから decode したもので、訓練データを直接コピーしたものではありません。
VAE 実行では、この再構成と latent の記録を残します。
- エンコーダ出力
- mu と logvar
- サンプリング規則
- z = mu + eps * std
- 再構成シグナル
- recon が 0.5903 から 0.0244 に低下する
- 正則化シグナル
- KL が非ゼロで制御されている
- 生成確認
- デコーダがランダムな z からもっともらしい 2D 点を生成できる
- トレードオフ
- 再構成品質と滑らかな潜在空間のトレードオフ
VAE、Autoencoder、GAN
Section titled “VAE、Autoencoder、GAN”| モデル | 何を学ぶか | 強み | よくある弱点 |
|---|---|---|---|
| Autoencoder | compact representation | reconstruction | latent space が sample しやすいとは限らない |
| VAE | distribution-shaped latent space | 滑らかな sampling と interpolation | 画像ではぼやけやすいことがある |
| GAN | adversarial realism | sharp な sample を作りやすい | 訓練が不安定で mode collapse しやすい |
| 信号 | 健康な方向 | 警告サイン |
|---|---|---|
| reconstruction loss | 下がって安定する | 高いまま |
| KL 項 | 0 ではなく、制御されている | 0 に潰れる、または loss を支配する |
| generated samples | もっともらしく多様 | すべて似ている、または意味がない |
| interpolation | 滑らかに変化する | 急に飛ぶ、data-like な領域から外れる |
よくある深層学習の tradeoff:
より良い reconstruction <-> より規則的な latent spaceこの balance は KL weight で調整します。beta-VAE ではよく beta と呼ばれます。
よくある間違い
Section titled “よくある間違い”| 間違い | 直し方 |
|---|---|
| VAE は autoencoder に noise を足しただけだと思う | mu、logvar、KL、sample 可能な latent space に注目する |
| reparameterization を無視する | z = mu + eps * std が勾配を通すと覚える |
| KL を早すぎる段階で強くしすぎる | 小さな beta や KL warmup を試す |
| reconstruction だけで判断する | generated samples と interpolation も見る |
| VAE と GAN を画像の sharpness だけで比べる | 安定性、latent structure、task fit も比べる |
- KL weight を
0.05から0.0に変えてください。klと generated samples はどう変わりますか。 - KL weight を
0.5に変えてください。reconstruction は悪くなりますか。 [-2, 0]から[2, 0]までの線上の点を decode してください。出力は滑らかに変わりますか。- decoder の
ReLUをTanhに変えてください。訓練はまだ収束しますか。 - GAN や diffusion の画像がより sharp に見えても、VAE が latent-space intuition に役立つ理由を説明してください。
参考実装と解説
- KL weight が 0 だと普通の autoencoder に近づき、再構成は良くなることがありますが、latent distribution は整いにくくなります。
- KL weight が大きいと latent は prior に近づきますが、decoder が使える情報が減り、reconstruction は悪くなりやすいです。
- 良い latent space なら、線上の decode 結果は滑らかに変化します。急な変化は表現空間が不連続なサインです。
Tanhは activation range と勾配の性質を変えます。収束する場合もありますが、出力スケールとデータ範囲を確認します。- VAE は reconstruction、sampling、連続的な latent 表現を同じ枠組みで扱えるため、生成モデルの確率的な直感を学ぶのに向いています。
- VAE は固定 code ではなく latent distribution を学びます。
- Reparameterization によって sampling と backpropagation を両立します。
- KL 項は latent space をより滑らかで sample しやすくします。
- VAE は GAN より訓練しやすいことが多い一方、構造と引き換えに sharpness を失う場合があります。
- VAE を理解すると、後の diffusion や representation learning が学びやすくなります。